Стоимость операций в тактах ЦП
Время на прочтение
17 мин
Количество просмотров 69K
Всем доброго! Вот мы и добрались до тематики С++ на наших курсах и по нашей старой доброй традиции делимся тем, что мы нашли достаточно интересным при подготовке программы и то, что будем затрагивать во время обучения.
Инфографика:
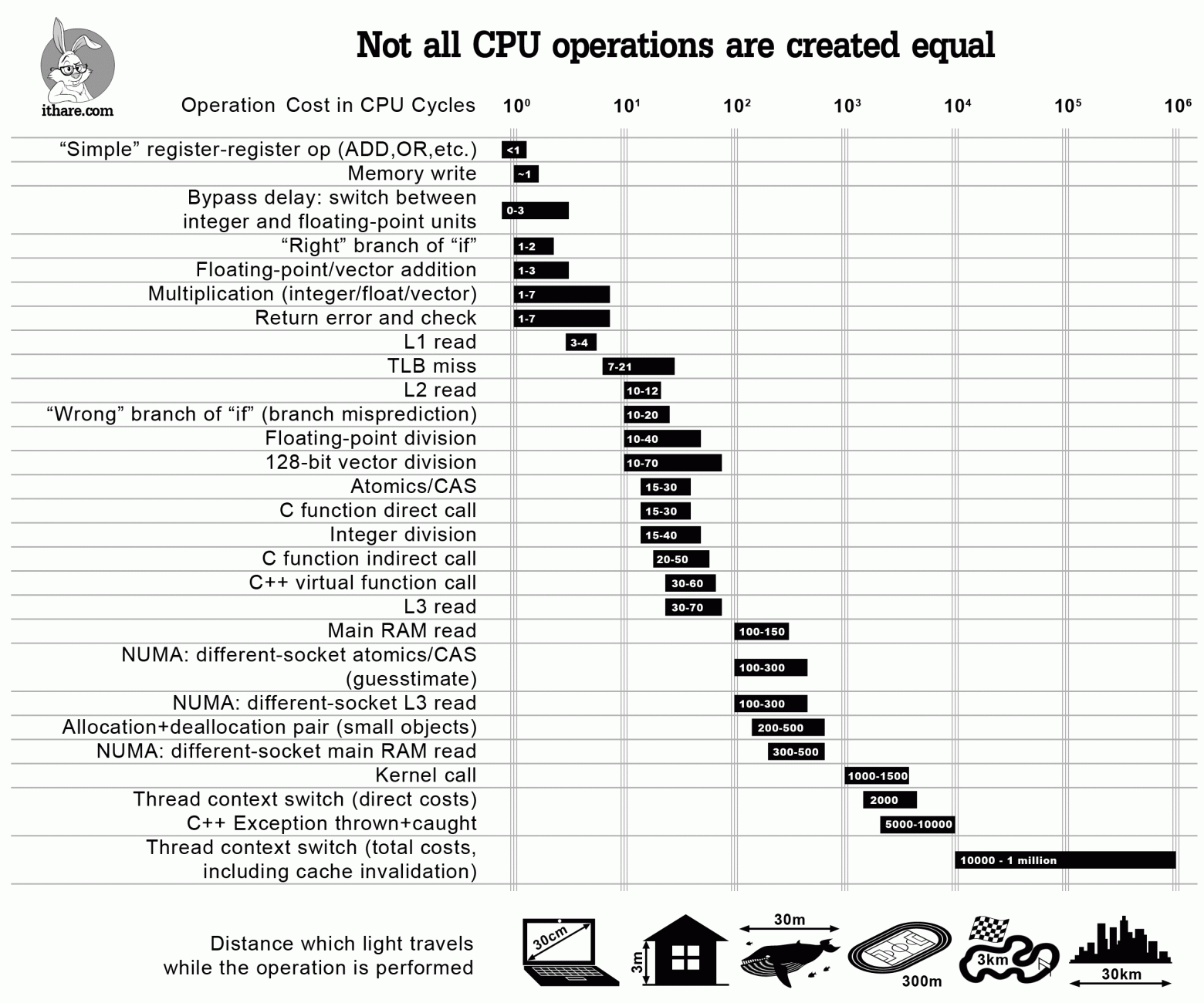
Когда нам нужно оптимизировать код, мы должны отпрофилировать его и упростить. Однако, иногда имеет смысл просто узнать приблизительную стоимость некоторых популярных операций, чтобы не делать с самого начала неэффективных вещей (и, надеюсь, не профилировать программу позже).
Итак, вот она — инфографика, которая должна помочь оценить стоимость конкретных операций в тактах ЦП — и ответить на такие вопросы, как “эй, сколько обычно стоит операция чтения L2?”. Хотя ответы на все эти вопросы более или менее известны, я не знаю ни одного места, где все они перечислены и представлены в перспективе. Также отметим, что, хотя перечисленные стоимости, строго говоря, применяются только к современным процессорам x86/x64, ожидается, что аналогичное отношение стоимостей будут наблюдаться на других современных процессорах с большими многоуровневыми кэшами (такими как ARM Cortex A или SPARC); с другой стороны, MCU (включая ARM Cortex M) достаточно отличны, чтобы некоторые из закономерностей могли быть к ним не применимы.
И последнее, но не менее важное, предостережение: все оценки здесь лишь указывают на порядок; однако, учитывая масштаб различий между различными операциями, эти показания могут по-прежнему использоваться (по крайней мере, следует помнить, что нужно избегать «преждевременной пессимизации»).
С другой стороны, я все еще уверен, что такая диаграмма полезна, чтобы не говорить «эй, вызовы виртуальных функций ничего не стоят» — что может быть или не быть истинным в зависимости от того, как часто вы их вызываете. Вместо этого, используя инфографику выше, вы сможете увидеть, что если вы вызовете свою виртуальную функцию 100K раз в секунду на процессоре с частотой 3 ГГц — это, вероятно, не будет стоить вам более 0,2% от общего объема вашего процессора; однако, если вы вызываете одну и ту же виртуальную функцию 10M раз в секунду, это легко может означать, что виртуализация поглощает двузначные проценты ядра вашего процессора.
Другой способ приблизиться к тому же вопросу — сказать «эй, я вызываю виртуальную функцию один раз за кусок кода, который составляет 10000 тактов, поэтому виртуализация не будет потреблять более 1% от времени программы», — но вам все равно нужен какой-то способ увидеть порядок величины связанных затрат — и приведенная выше диаграмма по-прежнему будет полезна.
Теперь давайте более подробно рассмотрим пункты в нашей инфографике выше.
Операции ALU и FPU
Для наших целей, говоря об операциях ALU, мы будем рассматривать только операции типа регистр-регистр. Если задействована память, затраты могут быть ОЧЕНЬ разными — это будет зависеть от того, “насколько велик был промах кэша” при доступе к памяти, как описано ниже.
“Простые” операции
В наши дни (и на современных процессорах), «простые» операции, такие как ADD/MOV/OR/…, могут легко выполняться быстрее одного такта ЦП. Это не означает, что операция будет выполняться буквально в течение половины такта. Напротив — в то время, как все операции все еще выполняются за целое число тактов, некоторые из них могут выполняться параллельно.
В [Agner4] (который, кстати, ИМХО является лучшим справочным руководством по оценке операций процессора) эта особенность отражается в наличии двух величин характеризующих каждую операцию: одна — это задержка (которая всегда представлена целым числом тактов), а другая — производительность. Следует отметить, однако, что в реальном мире, когда выходят за рамки оценок порядка, точное время будет сильно зависеть от характера вашей программы и от порядка, в котором компилятор поставил, казалось бы, несвязанные инструкции; вкратце — если вам нужно что-то лучше, чем порядок ожидания, вам нужно профилировать свою конкретную программу, скомпилированную вашим конкретным компилятором (и в идеале — на конкретном целевом процессоре тоже).
Дальнейшее обсуждение таких методов (известных как «внеочередное исполнение»), будучи Действительно Интересным, будет слишком аппаратно-ориентированным (как насчет «именования регистра», которое происходит под капотом процессора, чтобы уменьшить количество зависимостей, которые снижают эффективность работы внеочередного порядка?), и явно не входит в область нашего внимания в настоящий момент.
Целочисленное умножение/деление
Целочисленное умножение/деление достаточно дорогое по сравнению с «простыми» операциями выше. [Agner4] оценивает стоимость 32/64-битного умножения (MUL/IMUL в мире x86/x64) в 1-7 тактов (на практике я наблюдал более узкий диапазон значений, например 3-6 тактов), и стоимость 32/64-разрядного деления (известного как DIV/IDIV на x86/64) — около 12-44 тактов.
Операции с плавающей запятой
Стоимость операций с плавающей запятой взята из [Agner4] и варьируется от 1-3 тактов ЦП для сложения (FADD/FSUB) и 2-5 тактов для умножения (FMUL) до 37-39 тактов для деления (FDIV).
Если использовать скалярные SSE-операции (которыми, по-видимому, пользуется “каждая собака” в наши дни), показатели уменьшаться до 0,5-5 тактов для умножения (MULSS/MULSD) и до 1-40 тактов для деления (DIVSS/DIVSD); на практике, однако, вы должны ожидать скорее 10-40 тактов для деления (1 такт — это «взаимная пропускная способность», что на практике редко реализуется).
128-битные векторные операции
В течении уже нескольких лет ЦП поддерживают «векторные» операции (точнее — операции множественных данных Single Instruction Multiple Data или SIMD); в мире Intel они известны как SSE и AVX и в мире ARM — как ARM Neon. Забавно, что они работают с «векторами» данных, причем данные имеют одинаковый размер (128 бит для SSE2-SSE4, 256 бит для AVX и AVX2 и 512 бит для предстоящего AVX-512), но интерпретировать их можно по-разному. Например, 128-битный регистр SSE2 может быть интерпретирован как (a) два double, (b) четыре float, © два 64-битных integer, (d) четыре 32-битных integer, (e) восемь 16-битных integer, (f) шестнадцать 8-битных integer.
[Agner4] оценивает целочисленное сложение над 128-битным вектором в < 1 такт, если вектор интерпретируется как 4 × 32-битных целых числа и в 4 такта, если это 2 × 64-битных целых числа; умножение (4 × 32 бита) оценивается в 1-5 тактов — и в последний раз, когда я проверял, не было операций целочисленного векторного деления в наборе команд x86/x64. Операций с плавающей запятой над 128-битными векторами оцениваются от 1-3 тактов ЦП для сложения и 1-7 тактов ЦП для умножения, для деления до 17-69 тактов.
Задержки перехода
Не такая очевидная вещь, связанная с затратами на вычисления, заключается в том, что переключение между целыми и плавающими инструкциями не бесплатно. [Agner3] оценивает эту стоимость (известную как «задержка перехода») в 0-3 такта в зависимости от процессора. На самом деле проблема более общая, и (в зависимости от ЦП) также могут быть штрафы за переключение между векторными (SSE) целочисленными инструкциями и обычными (скалярными) целочисленными инструкциями.
Совет по оптимизации: в коде, для которого критична производительность, избегайте комбинирования вычислений с плавающей запятой и целыми числами.
Ветвление
Следующее, что мы будем обсуждать, — это ветвление кода. Переход (if внутри вашей программы), по сути, является сравнением и изменением в счетчике команд. В то время как обе эти вещи просты, ветвление может быть достаточно затратным. Обсуждение, почему это так, опять получится слишком аппаратно-ориентированным (в частности, это затрагивает конвейерную обработку и спекулятивное исполнение), но с точки зрения разработчика программного обеспечения это выглядит так:
- если процессор правильно угадывает, куда будет направлено выполнение (это до фактического вычисления условия if), тогда стоимость перехода составляет около 1-2 тактов ЦП
- однако, если процессор делает неправильное предположение — это приводит к тому, что ЦП «глохнет»
Продолжительность этой задержки оценивается в 10-20 тактов процессора, для последних процессоров Intel — около 15-20 тактов [Agner3].
Отметим, что в то время как макрос GCC __builtin_expect(), как полагают, влияет на предсказание ветвления — и он работал таким образом всего 15 лет назад, он больше не актуален, по крайней мере, для процессоров Intel (начиная с Core 2 или около того).
Как описано в [Agner3], на современных Intel-процессорах предсказание перехода всегда динамично (или, по крайней мере, доминируют динамические решения); это, в свою очередь, подразумевает, что ожидаемые отклонения от кода __builtin_expect() не будут влиять на предсказание переходов (на современных процессорах Intel). Однако __builtin_expect() все еще влияет на способ генерации кода, как описано в разделе «Доступ к памяти» ниже.
Доступ к памяти
В 80-е годы скорость процессора была сопоставима с задержкой памяти (например, процессор Z80, работающий на частоте 4 МГц, тратил 4 такта на команду типа регистр-регистр и 6 тактов на команду типа регистр-память). В то время можно было вычислить скорость программы, просто посмотрев на сборку.
С тех пор скорости процессоров выросли на 3 порядка, а задержки памяти улучшились только в 10-30 раз или около того. Чтобы справиться с оставшимся более чем тридцати кратным несоответствием, были введены все эти виды кэшей. Современный процессор обычно имеет 3 уровня кэшей. В результате скорость доступа к памяти очень сильно зависит от ответа на вопрос «где хранятся данные, которые мы пытаемся прочитать?». Чем ниже уровень кэша, где был найден ваш запрос, тем быстрее вы можете его получить.
Время доступа к кэшу L1 и L2 можно найти в официальных документациях, таких как [Intel.Skylake]; он оценивает время доступа к L1 / L2 / L3 в 4/12/44 такта процессора соответственно (обратите внимание: эти цифры немного варьируются от одной модели процессора к другой). Вообще, как упоминается в [Levinthal], время доступа к L3 может достигать 75 тактов, если кэш совместно используется с другим ядром.
Однако, что сложнее найти, так это информацию о времени доступа к основной ОЗУ. [Levinthal] оценивает его в 60нс (~ 180 тактов, если процессор работает на частоте 3ГГц).
Совет по оптимизации: улучшайте локальность данных. Подробнее об этом см., например, [NoBugs].
Помимо чтения из памяти, есть также запись. В то время как запись интуитивно воспринимается как более дорогая, чем чтение, чаще всего это не так; причина для этого проста: процессору не нужно ждать завершения записи перед тем, как идти вперед (вместо этого он только начинает писать — и сразу переходит к другим делам). Это означает, что большую часть времени процессор может выполнять запись в 1 такт; это согласуется с моим опытом и, по-видимому, достаточно хорошо коррелирует с [Agner4]. С другой стороны, если ваша система завязана на пропускной способности памяти, цифры могут получиться ЧРЕЗВЫЧАЙНО высокие; все же, из того, что я видел, перегрузка шины операциями записи является очень редким явлением, поэтому я не отразил его на диаграмме.
Еще помимо данных, есть и код.
Еще один совет по оптимизации: постарайтесь улучшить также и локальность кода. Это менее очевидно (и, как правило, оказывает меньшее влияние на производительность, чем плохая локализация данных). Обсуждение способов улучшения локальности кода можно найти в [Drepper]; эти способы включают такие вещи, как inlining, и __builtin_expect().
Следует отметить, что хотя __builtin_expect(), как упоминалось выше, больше не влияет на предсказание переходов на процессорах Intel, она все равно влияет на разметку кода, что, в свою очередь, влияет на пространственную локальность кода. В результате __builtin_expect() не имеет эффектов, которые слишком выражены на современных процессорах Intel (на ARM — понятия не имею, если быть честным), но все равно может повлиять на производительность в той или иной степени. Также сообщалось, что под MSVC замена if и else переходов условного оператора имеет эффекты, сходные с __builtin_expect() (если предполагаемый переход является if-переходом условного оператора с двумя переходами), но к этому следует относится с сомнением.
NUMA (Архитектура с неравномерной памятью)
Еще одна вещь, связанная с доступом к памяти и производительностью, редко наблюдается на настольных компьютерах (так как для этого требуются многопроцессорные машины — не следует путать с многоядерными). Таким образом, это, в основном, серверная парафия; однако это существенно влияет на время доступа к памяти.
Когда задействованы несколько сокетов, современные процессоры имеют тенденцию реализовывать так называемую архитектуру NUMA, причем каждый процессор (где «процессор» = «эта штука, вставленная в сокет») имеет свою собственную ОЗУ (в отличие от архитектуры FSB более раннего возраста с общей FSB aka Front-Side Bus и общая оперативная память). Несмотря на то, что каждый процессор имеет собственную ОЗУ, ЦП совместно используют адресное пространство ОЗУ — и всякий раз, когда требуется доступ к ОЗУ, физически находящемуся в другом, это делается путем отправки запроса на другой сокет через сверхбыстрый протокол, такой как QPI или Hypertransport.
Удивительно, но это не так долго, как вы могли бы ожидать — [Levinthal] дает 100-300 тактов ЦП, если данные были в кэше L3 удаленного процессора и 100нс (~ = 300 тактов), если данные были не там, и удаленный процессор должен был перейти в свою основную ОЗУ для этих данных.
CAS (сравнение с обменом)
Иногда (в частности, в неблокирующих алгоритмах и при реализации мьютексов) мы хотим использовать так называемые атомарные операции. Академически обычно рассматривается только одна атомарная операция, известная как CAS (Compare-And-Swap — сравнение с обменом) (на том основании, что все остальное может быть реализовано через CAS); в реальном мире их обычно больше (см., например, std::atomic в C++ 11, Interlocked*() в Windows или __sync _*_ и _*() в GCC/Linux). Эти операции — довольно странные звери: в частности, им нужна специальная поддержка ЦП для правильной работы. В x86 / x64 соответствующие инструкции ASM характеризуются наличием префикса LOCK, поэтому CAS на x86 / x64 обычно записывается как LOCK CMPXCHG.
С нашей нынешней точки зрения важно то, что эти операции, подобные CAS, будут выполняться значительно дольше обычного доступа к памяти (чтобы гарантировать атомарность, процессор должен синхронизировать процессы, по крайней мере, между разными ядрами, или в случае мультисокетных конфигураций, также между различными сокетами).
[AlBahra] оценивает стоимость операций CAS примерно в 15-30 тактов (с небольшой разницей между семействами x86 и IBM Power). Стоит отметить, что это число обоснованно только при выполнении двух допущений: (а) мы работаем с одноядерной конфигурацией и (б), что сравниваемая память уже находится в L1.
Касательно затрат CAS в мультисокетных NUMA-конфигурациях, я не смог найти данные о CAS, поэтому мне пока не обойтись без спекуляций. С одной стороны, ИМХО будет почти невозможным иметь задержки работы CAS на «удаленной» памяти меньше, чем кругооборот HyperTransport между сокетами, что в свою очередь сопоставимо со стоимостью чтения NUMA кэша L3.
С другой стороны, я действительно не вижу причин, чтобы превысить эти показатели :-). В результате я оцениваю стоимость NUMA раздельных CAS (и CAS-подобных) операций в 100-300 тактов ЦП.
TLB (Буфер ассоциативной трансляции)
Всякий раз, когда мы работаем с современными процессорами и современными ОС, на уровне приложений мы обычно имеем дело с «виртуальным» адресным пространством; другими словами, если мы запускаем 10 процессов, каждый из этих процессов может (и, вероятно, будет) иметь свой собственный адрес 0x00000000. Для поддержки такой изоляции процессоры реализуют так называемую «виртуальную память». В мире x86 она была впервые реализована через «защищенный режим», введенный еще в 1982 году на 80286.
Обычно «виртуальная память» работает постранично (для x86 каждая страница имеет размер либо 4K, либо 2M или, по крайней мере, теоретически, даже 1G (!)), когда ЦП знает какой процесс выполняется (!), и переразмечает виртуальные адреса на физические адреса при каждом доступе к памяти. Обратите внимание, что эта повторная разметка происходит полностью за кулисами, в том смысле, что все регистры процессора (кроме тех, которые имеют дело с разметкой) содержат все указатели в формате «виртуальной памяти».
И раз уж мы заговорили о «разметке» — ну, информация об этой разметке должна быть где-то сохранена. Более того, поскольку эта разметка (из виртуальных адресов в физические) происходит при каждом доступе к памяти, это должно быть Чертовски Быстро. Для этого обычно используется специальный вид кэша, называемый Буфер ассоциативной трансляции (TLB).
Так же как и для любого типа кэша, существует стоимость промаха TLB; для x64 она колеблется между 7-21 тактами ЦП [7cpu]. В целом, на TLB довольно сложно повлиять; однако здесь еще можно дать несколько рекомендаций:
- еще раз — улучшение общей локальности памяти помогает уменьшить промахи TLB; чем локальнее ваши данные, тем меньше шансов выйти из TLB.
- рассмотрите возможность использования «больших страниц» (те 2 MБ страницы на x64). Чем больше страницы, тем меньше записей в TLB вам понадобится; с другой стороны, использовать «больший страницы» нужно с осторожностью, это палка о двух концах. Это означает, что вам нужно протестировать его для своего конкретного приложения.
- рассмотрите возможность отключения ASLR (=«рандомизация размещения адресного пространства»). Как обсуждалось в [Drepper], в то время как включение ASLR хорошо для безопасности, оно убивает производительность, и в том числе именно из-за промахов TLB .
Примитивы программного обеспечения
Теперь мы закончили с теми вещами, которые напрямую связаны с “железом”, и будем говорить о некоторых вещах, связанных с программным обеспечением; они действительно все еще повсюду встречаются, поэтому давайте посмотрим, сколько мы тратим каждый раз, когда используем их.
Вызовы функций в С/С++
Сначала давайте рассмотрим стоимость вызова функций в C/C++. На самом деле, то, что вызывает функции в C/C++ делает чертовски много дел перед вызовом, и вызываемое тоже не сидит сложа руки.
[Efficient C++] оценивает затраты ЦП для вызова функции в 25-250 тактов в зависимости от количества параметров; однако, это довольно старая книга, а у меня нет лучшей ссылки того же калибра. С другой стороны, по моему опыту, для функции с достаточно небольшим числом параметров это скорее будет 15-30 тактов; это также, по-видимому, относится к процессорам, отличным от Intel, как выяснил [eruskin].
Совет по оптимизации: используйте inline-функции, где это применимо. Однако имейте в виду, что в наши дни компиляторы чаще всего игнорируют встраиваемые спецификации. Поэтому для действительно критически важных фрагментов кода вы можете использовать __attribute __ ((always_inline)) для GCC и __forceinline для MSVC, чтобы заставить их делать то, что вам нужно. Тем не менее, НЕ используйте эти принудительные inline для не очень критических фрагментов кода, это может сделать намного хуже.
Кстати, во многих случаях выигрыш от встраивания может превышать стоимость простого удаления вызова. Это происходит из-за того, что встраивание обеспечивает довольно много дополнительных оптимизаций (в том числе связанных с переупорядочением для обеспечения правильного использования аппаратного конвейера). Также давайте не будем забывать, что встраивание улучшает пространственную локальность для кода, что также немного помогает (см., например, [Drepper]).
Косвенные и виртуальные вызовы
Дискуссия выше была связана с обычными («прямыми») вызовами функций. Стоимость косвенных и виртуальных вызовов, как известно, выше, и многие согласны с тем, что косвенный вызов вызывает ветвление (однако, как отмечает [Agner1], до тех пор, пока вы вызываете одну и ту же функцию из одной и той же точки кода, механизмы предсказания переходов современных процессоров могут предсказать это довольно хорошо, в противном случае, вы получите штраф за ложное предсказание в 10-30 тактов). Что касается виртуальных вызовов — это одно дополнительное чтение (чтение указателя VMT), поэтому, если в этот момент все кэшируется (как обычно и есть), мы говорим о дополнительных 4 тактах процессора или около того.
С другой стороны, практические измерения [eruskin] показывают, что стоимость виртуальных функций примерно вдвое меньше стоимости прямых вызовов для небольших функций; в пределах нашей погрешности (которая является «порядком») это вполне согласуется с вышеприведенным анализом.
Совет по оптимизации: если ваши виртуальные вызовы стоят дорого, вместо этого в C++ вы можете подумать об использовании шаблонов (реализация так называемого полиморфизма времени компиляции); CRTP — это один (хотя и не единственный) способ сделать это.
Аллокации
В наши дни аллокаторы как таковые могут быть довольно быстрыми; в частности, аллокаторы tcmalloc и ptmalloc2 могут потратить всего 200-500 тактов ЦП для выделения/освобождения небольшого объекта [TCMalloc].
Тем не менее, есть существенное предостережение, связанное с аллокацией, и добавление к косвенным затратам на использование аллокаций: аллокация, как старое доброе правило большого пальца, означает уменьшение локальности памяти, что, в свою очередь, отрицательно влияет на производительность (из-за взаимодействий с незакэшированной памятью, описанных выше). Чтобы проиллюстрировать, насколько это плохо на практике, мы можем взглянуть на 20-строчную программу в [NoBugs]; эта программа при использовании vector<> выполняется от 100 до 780 раз быстрее (в зависимости от компилятора и конкретного поля), чем эквивалентная программа, использующая list<> — все из-за плохой локальности памяти последнего :-(.
Совет по оптимизации: думайте о сокращении количества аллокаций в ваших программах, особенно если есть этап, когда большая часть работы выполняется с данными только для чтения. В некоторых реальных случаях сглаживание ваших структур данных (т.е. замена выделенных объектов упакованными) может ускорить вашу программу до 5 раз.
Реальная история по теме. Когда-то давным-давно была программа, в которой использовались гигабайты оперативной памяти, что считалось слишком большим; окей, я переписал ее в «сплющенную» версию (то есть каждый узел был сначала сконструирован динамически, а затем в памяти был создан эквивалентный «сплющенный» объект только для чтения); идея «сглаживания» заключалась в уменьшении объема памяти. Когда мы запускали программу, мы заметили, что не только объем памяти уменьшился в 2 раза (что и было тем, что мы ожидали), но также, как очень хороший побочный эффект, скорость выполнения увеличилась в 5 раз.
Вызовы ядра ОС
Если наша программа работает под операционной системой (да, есть еще программы, которые работают без нее), то у нас есть целая группа системных API. На практике (по крайней мере, если мы говорим о более или менее обычной ОС) многие из этих системных вызовов приводят к вызовам ядра, которые включают в себя переключения в режим ядра и обратно; это включает в себя переключение между различными «кольцами защиты» (на процессоре Intel обычно между «кольцом 3» и «кольцом 0»). В то время как переключение между уровнями процессора занимает всего около 100 тактов, другие связанные с этим накладные расходы, как правило, делают вызовы ядра намного более дорогими, поэтому обычный вызов ядра занимает не менее 1000-1500 тактов процессора [Wikipedia.ProtectionRing].
Исключения C++
В наши дни про исключения C++ говорят, что они ничего не стоят до тех пор, пока не сработают. Действительно ли ничего — все еще не на 100% ясно (ИМО даже не ясно, может ли вообще задаваться такой вопрос), но он, безусловно, очень близок.
Тем не менее, эти «беззатратные пока не сработавшие» реализации стоят за огромной кучей работы, которая должна выполняться всякий раз, когда возникает исключение. Все согласны с тем, что стоимость брошенного исключения огромна, однако (как обычно) экспериментальных данных мало. Тем не менее, эксперимент [Ongaro] дает нам примерное количество около 5000 тактов процессора (чума!). Более того, в более сложных случаях я бы ожидал, что это число будет еще больше.
Возврат ошибки и проверка
Временная альтернатива исключениям — это возврат кодов ошибок и проверка их на каждом уровне. Хотя у меня нет ссылок на измерения производительности такого рода, мы уже знаем достаточно, чтобы сделать разумный эксперимент. Давайте подробнее рассмотрим его (мы не очень заботимся о производительности в случае возникновения ошибки, поэтому сосредоточимся на оценке, когда все в порядке).
В принципе, стоимость возврата-и-проверки состоит из трех отдельных стоимостей. Первая из них — это стоимость самого условного перехода, и мы можем с уверенностью предположить, что в 99+% случаев он будет предсказан правильно; это означает, что стоимость условного перехода в этом случае составляет около 1-2 тактов. Вторая стоимость — это затраты на копирование кода ошибки, и до тех пор, пока он остается в пределах регистров, это простое MOV, которое при данных обстоятельствах составляет от 0 до 1 такта (0 тактов означает, что MOV не имеет дополнительную стоимость, поскольку она выполняется параллельно с некоторыми другими операциями). Третья стоимость гораздо менее очевидна — это стоимость дополнительного регистра, необходимого для переноса кода ошибки; если мы вышли из регистров — нам понадобится пара PUSH/POP (или разумная факсимиле), которая, в свою очередь запись + чтение L1 или 1 + 4 такта. С другой стороны, давайте иметь в виду, что шансы PUSH/POP быть необходимыми, варьируются от одной платформы к другой; например, на x86 любая реалистическая функция потребует их почти наверняка; однако на x64 (у которого есть двойное число регистров) вероятность того, что PUSH/POP будут необходимы, значительно снизится (и в довольно многих случаях, даже если регистр не является полностью свободным, компилятор сделать его доступным дешевле, чем тривиальный PUSH/POP).
Объединив все три стоимости, я бы оценил затраты на возврат-кода-ошибки-и-проверку (в нормальном случае) в пределах от 1 до 7 тактов ЦП. Это, в свою очередь, означает, что если у нас есть одно исключение на 10000 вызовов функций, нам, вероятно, будет лучше с исключениями; однако, если у нас есть одно исключение на 100 вызовов функций, нам, вероятно, будем лучше с кодами ошибок. Другими словами, мы только что подтвердили очень хорошо известную передовую практику — «используйте исключения только для ненормальных ситуаций».
Переключения контекста потока
Последнее, но, конечно, не менее важное, нам нужно поговорить о стоимости переключения контекста потока. Одна из проблем с их оценкой заключается в том, что их очень сложно понять. Общая мудрость говорит, что они «чертовски дороги» (эй, должна же быть причина, почему nginx превосходит Apache), но насколько это «чертовски дорого»?
Из моих личных наблюдений цена составляла не менее 10000 тактов ЦП; однако есть много источников, которые дают НАМНОГО более низкие цифры. Фактически, однако, речь идет о том, «что именно мы пытаемся измерить». Как отмечено в [LiEtAl], существуют две разные стоимости по отношению к переключениям контекста.
- Первая стоимость — прямые затраты на переключение контекста потока, и они измеряются примерно в 2000 тактов ЦП (3 то есть, если моя математика правильна при преобразовании из микросекунд в такты)
- Однако вторая стоимость намного выше; это связано с аннулированием кэша потоком; согласно [LiEtAl], он может быть примерно 3M тактов ЦП. Теоретически, с полностью случайным шаблоном доступа, современный процессор с 12M кэша L3 (и с учетом штрафа порядка 50 тактов за доступ) может вызвать задержку в 10M тактов за контекстный переключатель; однако на практике штрафы обычно несколько ниже, поэтому число 1M от [LiEtAl] имеет смысл. Эта «намного более высокая» оценка также согласуется с количеством спинлоков на x64 (по умолчанию это 4000, по крайней мере для Windows/x64): если обычно полезно ждать 4000 итераций (в сумме, по крайней мере, до 15-20 тыс. тактов ЦП и больше, чем 40-50K тактов, из моего опыта), считывая эту переменную-которая-в-настоящее-время-заблокирована в замкнутом цикле — просто в надежде, что переменная откроется до того, как закончится 4000 итераций, все эти проблемы и такты ЦП просто для того, чтобы избежать переключения контекста — это означает, что стоимость переключения контекста обычно намного выше, чем те десятки-тысяч-процессорных-тактов-которые-мы-готовы-потратить-на-замкнутый-цикл-не-делающий-ничего-полезного.
Подытожим
Фух, было сделано довольно много работы, чтобы найти ссылки на все эти более или менее известные наблюдения.
Также учтите, что, хотя я честно пытался собрать все связанные цены в одном месте (проверяя сторонние выводы на моем собственном опыте в процессе), это всего лишь первая попытка, поэтому, если вы найдете достаточно убедительные доказательство того, что что-то неправильно — сообщите мне, я буду рад сделать диаграмму более точной.
THE END
Как всегда ждём тапков, вопросов в комментариях или на Дне открытых дверей
Nehalem is capable of executing 4 DP or 8 SP FLOP/cycle. This is accomplished using SSE, which operates on packed floating point values, 2/register in DP and 4/register in SP. In order to achieve 4 DP FLOP/cycle or 8 SP FLOP/cycle the core has to execute 2 SSE instructions per cycle. This is accomplished by executing a MULDP and an ADDDP (or a MULSP and an ADDSP) per cycle. The reason this is possible is because Nehalem has separate execution units for SSE multiply and SSE add, and these units are pipelined so that the throughput is one multiply and one add per cycle. Multiplies are in the multiplier pipeline for 4 cycles in SP and 5 cycles in DP. Adds are in the pipeline for 3 cycles independent of SP/DP. The number of cycles in the pipeline is known as the latency. To compute peak FLOP/cycle all you need to know is the throughput. So with a throughput of 1 SSE vector instruction/cycle for both the multiplier and the adder (2 execution units) you have 2 x 2 = 4 FLOP/cycle in DP and 2 x 4 = 8 FLOP/cycle in SP. To actually sustain this peak throughput you need to consider latency (so you have at least as many independent operations in the pipeline as the depth of the pipeline) and you need to consider being able to feed the data fast enough. Nehalem has an integrated memory controller capable of very high bandwidth from memory which it can achieve if the data prefetcher correctly anticipates the access pattern of the data (sequentially loading from memory is a trivial pattern that it can anticipate). Typically there isn’t enough memory bandwidth to sustain feeding all cores with data at peak FLOP/cycle, so some amount of reuse of the data from the cache is necessary in order to sustain peak FLOP/cycle.
Details on where you can find information on the number of independent execution units and their throughput and latency in cycles follows.
See page 105 8.9 Execution units of this document
http://www.agner.org/optimize/microarchitecture.pdf
It says that for Nehalem
The floating point multiplier on port 0 has a latency of 4 for single precision and 5 for double and long double precision. The throughput of the floating point multiplier is 1 operation per clock cycle, except for long double precision on Core2. The floating point adder is connected to port 1. It has a latency of 3 and is fully pipelined.
In order to get 8 SP FLOP/cycle you need 4 SP ADD/cycle and 4 SP MUL/cycle. The adder and the multiplier are on separate execution units, and dispatch out of separate ports, each can execute on 4 SP packed operands simultaneously using SSE packed (vector) instructions (4x32bit = 128bits). Both have throughput of 1 operation per clock cycle. In order to get that throughput, you need to consider the latency… how many cycles after the instruction issues before you can use the result.. so you have to issue several independent instructions to cover the latency. The multiplier in single precision has a latency of 4 and the adder of 3.
You can find these same throughput and latency numbers for Nehalem in the Intel Optimization guide, table C-15a
http://www.intel.com/content/www/us/en/architecture-and-technology/64-ia-32-architectures-optimization-manual.html
| Автор | Сообщение | ||
|---|---|---|---|
|
|||
|
Member Статус: Не в сети |
Подскажите, где можно раздобыть информацию о количестве операций за такт всех выпускаемых сегодня компаниями Intel и AMD ЦП? * Число операций с плавающей запятой (floating point operations) за такт, (или хотя бы первый пункт, остальные не обязательно). Смог найти только для AMD Atlon XP (3-3-3-9-3). И то, нашёл на каком-то фанатском сайте. Знаю, что у Core 2 Duo 4 FLO за такт, а у Athlon 64 — 3. Но всё остальное не могу никак найти. Подскажите! Может кто-нибудь составлял таблички такие или они где-то выложены? Буду рад вашему отклику!
|
| Реклама | |
|
Партнер |
|
maco |
|
|
Member Статус: Не в сети |
У Фога поглядите, по IPC у него были данные, по декодерам — не знаю. |
|
McArcher |
|
|
Member Статус: Не в сети |
maco писал(а): У Фога поглядите, по IPC у него были данные, по декодерам — не знаю. там про ЦП 2 файлика, в них такое море инфы, но самого интересного для меня, выведенного в табличку не могу найти… плюс нету K10.5… |
|
maco |
|
|
Member Статус: Не в сети |
Цитата: Instruction tables: Lists of instruction latencies, throughputs and micro-operation breakdowns for Intel, AMD and VIA CPUs File name: instruction_tables.pdf, size: 1280593, last modified: 2009-Sep-26. Там этих таблиц как на табличной фабрике |
|
McArcher |
|
|
Member Статус: Не в сети |
Цитата: А для ламеров никто не запрещает почитать разнокалиберные рекламные материалы на оф. сайтах производителей и соответствующие статьи (на тему анонса/выхода нового семейства процессоров) на сайтах, занимающихся обзорами процессоров. Не могу найти. Обычно такие вещи очень редко пишут =( Добавлено спустя 6 минут 27 секунд: |
|
maco |
|
|
Member Статус: Не в сети |
McArcher писал(а): проверьте и подскажите количество операций с плавающей точкой для следующих процессоров/семейств процессоров (на ядро) Подсказываю — количество операций с плавающей точкой слегка превышает названные вами цифры Кстати, вот тут, например, можно поглядеть одним глазом для общего развития. |
|
Walkie |
|
|
Member Статус: Не в сети |
Как раньше было хорошо : за сколько тактов выполняется операция. А теперь дожили : кол-во операций/такт. Ужас. |
|
McArcher |
|
|
Member Статус: Не в сети |
Walkie писал(а): Как раньше было хорошо : за сколько тактов выполняется операция. А теперь дожили : кол-во операций/такт. Ужас.
|
—
Кто сейчас на конференции |
|
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 11 |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
Лаборатория
Новости
Оптимизация для процессоров семейства Pentium: 24. Работа с плавающей запятой (PPlain и PMMX)
Оптимизация для процессоров семейства Pentium: 24. Работа с плавающей запятой (PPlain и PMMX) — Архив WASM.RU
Инструкции плавающей запятой не могут спариваться так, как это делают
целочисленные инструкции, не считая некоторых случаев, определяемых следующими
правилами:
- первая инструкция (выполняющаяся в U-конвеере) должна быть FLD, FADD,
FSUB, FMUL, FDIV, FCOM, FCHS или FABS.- вторая инструкция (в V-конвеере) должна быть FXCH.
- инструкция, следующая за FXCH, должна быть инструкцией плавающей
запятой, иначе FXCH спарится несовершенно и займет лишний такт.Это особенное спаривание играет важную роль, что вкратце будет объяснено.
Хотя, как правило, инструкции плавающей запятой не могут спариваться, многие
из них конверизуются, то есть одна инструкция может начать выполнение до того,
как будет закончена предыдущая инструкция.Пример:
Очевидно, что выполнение двух инструкциий не может пересекаться, если второй
инструкции нужен результат первой. Так как почти все инструкции плавающей
запятой работают с вершиной стека регистров ST(0), возможностей сделать их
независимыми друг от друга не очень много. Решение этой проблемы состоит в
переименовании регистров. Инструкция FXCH в реальности не обменивает
содержимое двух регистров, оно только меняет их имена. Инструкции, которые
помещают или извлекают значение из стека регистров также работают с помощью
переименования. Переименование регистров на Pentium настолько хорошо
оптимизировано, что можно переименовать использующийся регистр. Переименование
регистров никогда не вызывает задержек — возможно даже переименовать регистр
более чем один раз за такт, например, когда вы спариваете FLD или FCOMPP с
FXCH.Правильно используя инструкции FXCH, вы можете создать условия, чтобы
инструкции плавающего кода были более независимыми друг от друга.Пример:
В вышеприведенном примере мы создали три независимые ветви. Каждый FADD
занимает 3 такта, поэтому мы можем каждый такт начинать выполнение нового
FADD. Когда мы начали выполнение ветви ‘a’, у нас есть время, чтобы начать
выполнение двух новых инструкций FADD в ветвях ‘b’ и ‘c’ до возвращения к
ветви ‘a’, поэтому каждый третий FADD принадлежит той же ветви. Мы используем
инструкции FXCH каждый раз, когда необходимо, чтобы ST(0) стал равен регистру,
который принадлежит к желаемой ветви. Как вы можете видеть из примера, это
образует регулярную последовательность, но уясните хорошо, что инструкции
FXCH повторяются с периодом, равным двум, в то время как у ветвей период
равен трем. Это может немного смущать, поэтому вам следует проработать этот
пример, чтобы понять где находится какой из регистров.Все версии инструкций FADD, FSUB, FMUL и FILD занимают три такта и
конвееризуются, поэтому вышеописанный метод можно применять и с этими
инструкциями. Использование переменных в памяти не отнимает больше времени,
чем использование регистров, если переменная в памяти находится в кэше
первого уровня и правильно выравнена.Вы уже, наверное, что у всех правил есть исключения, и у вышеизложенного они
тоже есть: вы не можете начать выполнение инструкции FMUL на следующий такт
после другой инструкции FMUL, потому что FMUL не может спариваться совершенно.
Рекомендуется, чтобы вы поместили другую инструкцию между двумя FMUL’ами.Пример:
Здесь у вас есть задержка между FMUL [b2] и между FMUL [c2], потому что
другая FMUL началась в предыдущий такт. Вы можете улучшить этот код, поместив
инструкции FLD между FMUL’ами.В других случаях вы можете поместить FADD, FSUB или что-нибудь еще между
FMUL’ами, чтобы избежать задержек.Инструкции плавающей запятой, чье выполнение пересекается, требуют, конечно,
чтобы у вас были независимые ветви, выполненине которых вы можете совместить.
Если у вас есть только одна большая формула, которую надо выполнить, тогда вы
можете посчитать части формулы параллельно, чтобы достигнуть цели. Если,
например, вы хотите добавить шесть чисел, тогда вы можете разделить операции
на две ветви с тремя числами в каждой, и добавить две ветви в конце:
Здесь у нас есть задержка в один такт перед FADD [f], потому что она ожидает
результата выполнения FADD [d] и задержка в два такта перед последним FADD,
потому что она ожидает результата FADD [f]. Более поздняя задержка может
быть спрятана путем заполнения ее несколько целочисленными инструкциями, но
с первой задержкой это не получится, так как целочисленная инструкция в этом
месте приведет к тому, что FXCH будет спариваться несовершенно.Первую задержку можно избежать, создав три ветви вместо двух, но это будет
стоить дополнительно FLD, поэтому мы ничего не выиграем, прибегнув к этому
варианту, если только у нас нет восьми чисел, которые нужно сложить.Выполнение не все инструкций плавающей запятой может пересекаться. И
выполнение некоторых инструкций плавающей запятой лучше сочетается с
целочисленными инструкциями. Например, инструкция FDIV занимает 39 тактов.
Во все, кроме первого такта, выполнение этой инструкции может пересекаться
с целочисленными инструкциями, но только в последние два такта она может
пересекаться с инструкциями плавающей запятой.Пример:
Первый FXCH спаривается с FDIV, но занимает дополнительный такт, потому что
за ней не следует инструкция плавающей запятой. Пара SHR / INC начинает свое
выполнение до того, как будет закончено выполнение FDIV, но была вынуждена
подождать, пока свое выполнение закончит FXCH.Если у вас нет ничего, что поместить после инструкции плавающей запятой,
которая может выполняться одновременно с целочисленной инструкцией, (FDIV,
FSQRT), вы можете поместить чтение значение из какой-нибудь переменной в
памяти, которое может вам понадобиться в дальнейшем, чтобы она на 100% была в
кэше.Пример:
Здесь мы загружаем загружаем значение в [ESI] в кэш, в то время как FDIV
вычисляется (результат самой операции сравнения нам не важен).В главе 28 приведен полный список инструкций плавающей запятой, и с чем они
могут спариваться.Никаких потерь при использовании переменных в памяти в инструкциях плавающей
запятой, потому что модуль арифметических вычислений на один шаг дальше в
конвеере, чем модуль чтения. Однако при сохранении данных может случиться
задержка, аналогичная задержке AGI: выполнение инструкции FST или FSTP с
переменной в памяти в качестве операнда занимает два такта, но данные должны
быть готовы в предыдущем такте, поэтому будет задержка в один такт, если
значение, которое нужно сохранить не будет готово еще в предыдущем такте.Пример:
FSTP задерживается на один такт, потому что результат FADD не был готов в
предыдущем такте. Во многих случаях вы не можете скрыть этот тип задержек
бзе организования вашего кода с плавающей запятой в четыре ветви или помещения
внутрь каких-то целочисленных инструкций. Два такта на стадии выполнения
инструкции FST(P) не могут спариваться или пересекаться с любой другой
последующей инструкцией.Инструкции с целочисленными операндами, такими как FIADD, FISUB, FIMUL, FIDIV,
FICOM можно разделить на простые операции, чтобы улучшить пересекаемость
выполнений инструкций.Пример:
Разделить на:
В этом примере вы экономите два такта, пересекая выполнение двух инструкций
FILD.© Агнер Фог, пер. Aquila
archive
New Member
- Регистрация:
- 27 фев 2017
- Публикаций:
- 532

Заинтересовал меня вопрос — а сколько инструкций за такт выполняют современные Arm и Intel процессоры. И мои 0.8 инструкции на такт — это хорошо или плохо?
Будем тестировать такой код.
int32_t asin[1000];
int32_t adata[1000];
int64_t sum;
void Test::process(int count)
{
sum = 0;
for (int i = 0; i < count; i++)
{
sum += asin[i] * adata[i];
}
}
count = 1000, функция эта вызывается 100000. Т.е. всего 1e8 итераций. Включаем везде максимальную оптимизацию, но принимаем меры против того, чтобы функция process заинлайнилась. И что-бы count не считался константой, которой можно сделать unwind цикла.
Сначала общая таблица. time=0.180 sec Intel Core i7 4 GHz x86. 8 инструкций в цикле. Примерно 7.2 такта на цикл. time=0.056 sec Intel Core i7 4 GHz x64. 8 инструкций в цикле. Примерно 2.4 такта на цикл. time=0.350 sec Cortex-A53 2.016 GHz arm64-v8a 7 инструкций в цикле. Примерно 7.05 такта на цикл. time=0.355 sec Cortex-A53 2.016 GHz armeabi-v7a 9 инструкций в цикле. Примерно 7.16 такта на цикл. time=0.850 sec Cortex-A53 2.016 GHz armeabi 17 инструкций в цикле. Примерно 17.1 такта на цикл.
Ниже приведу asm вырезки кода цикла, сгенерированного компиляторами.
[Intel Core i7 4 GHz x86]
Intel Core i7 4 GHz x86
00E31092 mov eax, dword ptr[ecx + esi * 4 + 0FA0h] 00E31099 imul eax, dword ptr[ecx + esi * 4] 00E3109D cdq 00E3109E add dword ptr[ecx + 1F40h], eax 00E310A4 adc dword ptr[ecx + 1F44h], edx 00E310AA inc esi 00E310AB cmp esi, edi 00E310AD jl Test::process + 22h (0E31092h)
[Intel Core i7 4 GHz x64]
Intel Core i7 4 GHz x64
00007FF70CF91015 mov ecx,dword ptr [r8+rax*4+0FA0h] 00007FF70CF9101D inc rax 00007FF70CF91020 imul ecx,dword ptr [r8+rax*4-4] 00007FF70CF91026 movsxd rcx,ecx 00007FF70CF91029 add rdx,rcx 00007FF70CF9102C mov qword ptr [r8+1F40h],rdx 00007FF70CF91033 cmp rax,r9 00007FF70CF91036 jl Test::process+15h (07FF70CF91015h)
[Cortex-A53 2.016 GHz arm64-v8a]
Cortex-A53 2.016 GHz arm64-v8a
.LBB1_2: ldrsw x11, [x10, #4000] ldrsw x12, [x10] sub x9, x9, #1 add x10, x10, #4 madd x8, x11, x12, x8 str x8, [x0, #8000] cbnz x9, .LBB1_2
[Cortex-A53 2.016 GHz armeabi-v7a]
Cortex-A53 2.016 GHz armeabi-v7a
.LBB1_1: ldr.w lr, [r0] ldr.w r4, [r0, #4000] adds r0, #4 mul r4, r4, lr adds r3, r3, r4 adc.w r2, r2, r4, asr #31 subs r1, #1 strd r3, r2, [r12] bne .LBB1_1
[Cortex-A53 2.016 GHz armeabi]
Cortex-A53 2.016 GHz armeabi
.LBB1_2: lsls r6, r3, #5 subs r6, r6, r0 ldr r6, [r6] movs r4, r3 rsbs r3, r0, #0 ldr r3, [r3] muls r3, r6, r3 ldr r6, [sp] adds r2, r2, r3 str r2, [r6] asrs r3, r3, #31 adcs r5, r3 movs r3, r4 str r5, [r6, #4] subs r0, r0, #4 subs r1, r1, #1 bne .LBB1_2
Практически по всех вариантах количество инструкций на такт попадает в интервал [0.9, 1.1], т.е. около одной инструкции на такт. Особняком стоит Intel Core i7 4 GHz x64 который вдруг разогнался неимоверно и выдает нам 3.3 инструкции на такт!!!
Делаем выводов пачку всяких.
1. Одна инструкция на такт это нормально. Так что мы со своими 0.8 инструкциями на такт не слишком отстаем от «крутых» процессоров.
2. Суперскалярный процессор это круто, но легко может случиться, что его суперскалярность сломается и будет он работать как обычный процессор с одной инструкцией на такт. Это подтверждает вариант x86 который делает одну инструкцию на такт.
3. Инструкции должны быть функциональными. Instruction set это не только про инструкции которые просто парсить. Instruction set это еще и про запаковку максимальной информации в минимальное количество инструкций. armeabi вариант нам показывает, почему 17 инструкций на цикл — это плохо.
PS: Еще парочка замечаний по сравнительному ассемблеру.
В arm64-v8a используется инструкция перехода cbnz x9, .LBB1_2 Это аналог моей инструкции if(rx!=0) goto Label. Т.е. вариант без слова состояния alu является вполне живым.
Если сравнивать rm64-v8a и armeabi-v7a код, то видно, что идет отказ от инструкций вида adds r3, r3, r4. Тоесть инструкций, в которых три разных регистра используются. Мне это тоже кажется логичным развитием событий.
![]()
направляется во внутренний кэш. Если затребованная область памяти присутствует в строке внутреннего кэша, то он обслужит этот запрос. Вторичный кэш устраняет многие промахи первого кэша. В случае промаха на обоих уровнях, минимальная задержка передачи
Основная память
КЭШ L2
Системная шина
КЭШ
Интерфейс шины
 данных
данных
Буфер упорядоч и-вания памяти
|
Блок |
КЭШ |
|
выбора команд |
команд |
Пул команд
Из устройства генерации адреса
Рис. 6.17. Кэш – память и интерфейс шины
данных из основной памяти составляет 10-15 тактов (в зависимости от попадания в страницу). К кэшу данных возможен одновременный доступ по записи и чтению, если запросы относятся к разным банкам кэш-памяти.
Использование кэш-памяти в мультипроцессорных системах требуют специальных мер предосторожности. Дело в том, что когда один из процессоров обращается к фрагменту памяти, с которым другой процессор работает через свою кэш-память, первый может получить неправильные данные. Процессор Р6 (а также Pentium) обеспечивает специальные механизмы, которые гарантируют соблюдение кэш-согласования. Кэш-согласование означает, что если один из процессоров, входящий в систему из нескольких процессоров, и, возможно, нескольких внешних устройств кэш-памяти, изменяет какие-либо данные, то все процессоры при обращении к этим данным получает эти изменения.
Кэш-согласование достигается с помощью использования протокола MESI (modified/exclusive/ shared/invalid). Согласно этому протоколу, каждой строке в кэш-памяти данных присваивается одно из четырех состояний. Это означает, что в тег адреса строки вводятся два дополнительных бита тега состояния. Эти теги состояния строки могут быть изменены как процессором, содержащим эту кэш-память, так и другими устройствами, подключенными к внешней шине.
Состояние строк для каждого процессора определяется следующим образом:
М– состояние (изменённая). Строка доступна только в одном устройстве кэш-памяти
ибыла изменена (его содержимое отлично от содержимого соответствующего ей фрагмента основной памяти). Доступ к М-строке (и чтение и запись) может быть осуществлен без обращения к основной памяти через внешнюю шину;
Е– состояние (исключительная). Строка так же доступна в одном устройстве кэшпамяти, но она не изменялась (ее копия в основной памяти действительна). Доступ к Е- строке (чтение или запись) также может быть осуществлен без обращения к внешней шине. Запись в Е-строку переводит её в М-состояние;
S – состояние (разделённая). Возможно, эта строка присутствует более чем в одном устройстве кэш-памяти. Чтение S-строки не приводит к действиям на шине, но запись в S- строку генерирует цикл записи через внешнюю шину в основную память. При этом та же строка в других устройствах кэш-памяти становится недействительной.
I – состояние (недействительная). Строка недоступна в кэш-памяти. Чтение I-строки приводит к считыванию фрагмента в кэш из основной памяти. Запись в I-строку генерирует цикл записи через внешнюю шину в основную память.
Кэш-согласование для кэш-памяти команд первого уровня поддерживается с помощью подмножества MESI-протокола. Строки в кэш-памяти команд могут находиться только в двух состояниях: S- и I- состояниях. Это связано с тем, что запись в кэш-память команд запрещена во избежание некорректного изменения кода.
Интерфейс шины генерирует два типа обращения к основной памяти: чтение из памяти в регистр и запись из регистра в память. При чтении из памяти задаются адрес памяти, размер блока считываемых данных и регистр — назначение. Команда чтения кодируется одной микрокомандой. При записи задаются адрес памяти, размер блока записываемых данных и сами данные. Поэтому команда записи кодируется двумя микрокомандами: первая генерирует адрес, вторая готовит данные. Микрокоманды чтения и записи планируются независимо и могут выполняться параллельно. Они могут переупорядочиваться в буфере записи.
В процессоре Р6 реализована архитектура подсистемы памяти, позволяющая командам чтения опережать команды записи и другие команды чтения. Записи из буферов производятся в память всегда в порядке, предписанном программным кодом. Процессор поддерживает логическое соответствие порядка физических операций чтения и записи памяти их порядку в программном коде. При этом операции чтения могут иметь любой порядок, они могут пропускать буферизованные записи, а записи в память идут всегда в порядке, предписанном программой. Буфер упорядочивания памяти служит в качестве диспетчера и буфера переупорядочивания. В нем хранятся отложенные команды чтения и записи, и он осуществляет их повторное диспетчирование, когда блокирующее условие (зависимость по данным, недоступность ресурсов) исчезает.
Динамическое выполнение команд в процессоре Р6 резко повышает частоту запросов процессорного ядра к шине за данными и командами, поскольку ядро одновременно обрабатывает несколько команд. Для обхода узкого места — внешней шины — процессорное ядро использует архитектуру независимой двойной шины (рис.5.50.). Одна из этих шин используется только для связи с вторичной кэш-памятью, расположенной в том же корпусе микросхемы. Эта шина является локальной и в геометрическом смысле — проводники имеют длину порядка единиц сантиметров, что позволяет использовать ее на частоте ядра процессора. Значительный объем вторичного кэша позволяет удовлетворять большинство запросов к памяти, при этом коэффициент загрузки локальной шины достигает 90 %. Вторая шина процессорного кристалла выходит на внешние выводы микросхемы и является системной шиной процессора Р6. Эта шина работает на внешней частоте независимо от внутренней шины.
По статистическим данным загрузка процессором внешней шины для обычных применений составляет 10 % от ее пропускной способности (528 Кбайт/сек. при 66 МГц и 800 Кбайт/сек. при 100 МГц), а для серверных применений может достигать 60 % при четырехпроцессорной конфигурации.
Таким образом, снижение нагрузки на внешнюю шину, за счет введения локальной шины, позволяет эффективно использовать процессор Р6 в многопроцессорных системах.
Как видно из организации процессора Р6, его основное вычислительное ядро выполнено по технологии RISC−процессоров с применением архитектурных методов, используемых при их построении. Следующим фактором повышения производительности процессора является применение принципа многоуровневой конвейеризации, позволяющего увеличить пропускную способность конвейера. Операции, выполняемые на каждой ступени процессора Pentium, все еще остаются достаточно сложными, и требуется их дальнейшее разбиение. Так как пропускная способность конвейера определяется самой медленной стадии, то при разработке конструкции конвейера необходимо обеспечить равенство скоростей обработки на всех стадиях. Для системы команд х86, имеющие в своем составе
простые (от 1 до 7 байт), сложные (7-11 байт) и очень сложные команды, обеспечить данное условие невозможно. В этом случае для повышения пропускной способности конвейера применяют метод межстадийной буферизации. Межстадийная буферизация в процессоре Р6 используется во многих местах конвейера, но, особенно, полезна в интерфейсах памяти, поскольку ее быстродействие относительно невелико. Буферизация также используется между двумя основными функциями исполнения команды: выборки и выполнения. Роль буфера на этой стадии выполняет пул команд, который позволяет реализовывать принцип динамического исполнения команд.
Разбиение сложных команд х86 на более простые операции (микрокоманды) привело к увеличению числа ступеней конвейера. При этом конвейер процессора Р6 выглядит следующим образом:
1.Выборка команд из кэша (IF0);
2.Выравнивание по границам параграфа (IF1,IF0);
3.Декодирование, определение формата команд (ID0);
4.Декодирование команд (ID1 – три декодера);
5.Определение адресов перехода (BTB0, BTB1);
6.Переименование регистров (RAT);
7.Загрузка микрокоманд в пул (ROB R);
8.Загрузка микрокоманд в буфер станции RS;
9.Диспетчирование (распределение по портам);
10.Выполнение (работа ФИУ);
11.Запись результатов в пул (ROB W);
12.Переупорядочивание (RRF).
Здесь показаны основные стадии выполнения команд на процессоре Р6. Этап выборки, в свою очередь, разбиваются на две стадии, где на первой стадии происходит выборка двух строк кэша команд, а на второй стадии из выбранных байтов выделяются команды. Эти команды помечаются и направляются в устройство декодирования.
Н а третьей стадии происходит определение формата команд блоком ID0 и подготовка их передачи в блок ID1, содержащий три параллельно работающих декодера, либо планировщику последовательности микрокоманд (MIS).
На четвертой стадии три параллельных декодера позволяют в лучшем случае декодировать 3 команды за 1 такт с соотношением 4-1-1. Для декодирования сложных (7-11 байт) и сверхсложных команд (11-16 байт) семейства х86 требуются от 1 до 2 дополнительных машинных тактов соответственно, и используется планировщик последовательности микрокоманд (MIS). Следовательно, эта ступень конвейера исполняется за три такта.
На пятой стадии (после декодирования инструкций ветвлений) процессор осуществляет вычисление адресов перехода с помощью блоков BTB0 и BTB1 и формирует два потока микрокоманд (один поток помечается — при отрицательном исходе условия, другой – при положительном).
На шестой стадии осуществляется процедура переименования регистров.
На седьмой стадии микрокоманды с выхода устройства декодирования записываются в пул команд (ROB R), и в этой точке заканчивается упорядоченная часть конвейера.
На восьмой и девятой стадиях происходит загрузка микрокоманд в буфер станции RS и диспетчирование их по исполнительным устройствам.
На десятой стадии производится выполнение микрокоманд в исполнительных устройствах. Алгоритм планирования выполнения микрокоманд, реализованный в процессоре Р6, может запустить до 5 микрокоманд за такт.
На 11 стадии после выполнения микрокоманд на исполнительных устройствах их результаты возвращаются в пул команд (ROB W). На операции диспетчирования, выполнения, сохранения результатов выполненных микрокоманд, процессор затрачивает по одному машинному такту.
На заключительной стадии происходит упорядочивание потоков команд и данных, реализуемое устройством отката и выполняется за два машинных такта. На этой стадии конвейера происходит сохранение результатов выполнения команд в памяти машины. При отсутствии промаха эти результаты сохраняются в кэш-памяти данных, а при промахе — они записываются в память системы в режиме отложенной записи. Этот режим обеспечивает буфер упорядочивания памяти (RRF).
Большинство основных операций (целочисленная арифметика и логика, умножение с плавающей точкой) могут конвейеризироваться с производительностью исполнения в одну, две операции за такт. Делитель FPU неконвейеризирован. Длительные операции могут выполняться параллельно с короткими командами.
Основные, функциональные устройства Р6 выполнены в виде конвейеров и в совокупности образуют 12-ти ступенчатый конвейер, реализующий трех потоковую модель обработки данных.
Таким образом, наряду с новыми введенными архитектурными методами использование многоуровневой конвейеризации с параллельной обработкой на всех стадиях позволяет дополнительно увеличить производительность на 30% относительно процессора
Pentium.
6.4.2.Сравнительные характеристики Pentium и Р6
Втаблице 6.3 приведены архитектурные особенности микропроцессоров пятого и шестого поколений.
Процессор MMX базируется на ядре Pentium и представляет собой расширение
набора команд с использованием технологий OKMД (SIMD − Singes Instruction Multiple Data), предназначенное для ускорения мультимедийных и коммуникационных программ за счет параллельной обработки. Набор команд MMX содержит 57 новых операций и новые типы 64-битных данных. Эти новые типы данных хранят упакованные целочисленные
Таблица 6.3
|
Процессор |
Технология, мкм |
Частота системной шины, МГц |
Частота ядра, МГц |
Кэш команд / данных,Кбайт L1 |
Кэш L2, Кбайт |
Предсказание переходов |
Опережающее исполнение |
(спекулятивное) |
Переименование регистров |
Внеочередное исполнение |
Поддержка ММХ |
Многопроцессорные системы |
Сокет (слот) |
||
|
Pentium |
поколение |
0.8 |
60 |
60 |
16 |
— |
+ |
— |
— |
— |
FRC** |
Сокет4 |
|||
|
66 |
66 |
8/8 |
|||||||||||||
|
1 |
|||||||||||||||
|
0.6 |
50 |
75 |
16 |
— |
+ |
— |
— |
— |
— |
||||||
|
90 |
8/8 |
||||||||||||||
|
100 |
|||||||||||||||
|
Pentium |
поколение2 |
120 |
FRC |
Сокет5,7 |
|||||||||||
|
0,35 |
60 |
133 |
2SMP* |
||||||||||||
|
66 |
150 |
||||||||||||||
|
166 |
|||||||||||||||
|
180 |
|||||||||||||||
|
200 |
|||||||||||||||
|
Pentium |
0.35 |
66 |
166 |
32 |
— |
+ |
— |
— |
+ |
+ |
Сокет7 |
|||
|
ММХ |
200 |
16/16 |
2SMP |
|||||||||||
|
233 |
||||||||||||||
|
Pentium |
0.6 |
66 |
150 |
16 |
256 |
+ |
+ |
+ |
+ |
— |
Сокет 8 |
|||
|
Pro |
0.35 |
166 |
8/8 |
512 |
FRC, |
|||||||||
|
180 |
4SMP |
|||||||||||||
|
Pentium II |
OverDrive |
0.35 |
66 |
333 |
32 |
512 |
+ |
+ |
+ |
+ |
+ |
FRC, |
Сокет 8 |
|
|
16/ 16 |
2SMP |
|||||||||||||
|
0.35 |
66 |
233 |
32 |
512 |
+ |
+ |
+ |
+ |
+ |
|||||
|
II |
266 |
16/16 |
Слот 1 |
|||||||||||
|
Pentium |
300 |
FRC, |
||||||||||||
|
0.25 |
100 |
350 |
2SMP |
|||||||||||
|
400 |
||||||||||||||
|
II |
0.25 |
100 |
400 |
32 |
512 |
+ |
+ |
+ |
+ |
+ |
FRC, |
Слот 2 |
||
|
Pentium |
Xeon |
|||||||||||||
|
16/16 |
1024 |
8SMP |
||||||||||||
|
2048 |
||||||||||||||
|
0.25 |
66 |
266 |
32 |
+ |
+ |
+ |
+ |
+ |
− |
|||||
|
Celeron |
300 |
16/ 16 |
Слот 1 |
|||||||||||
|
300A |
128 |
|||||||||||||
|
333 |
||||||||||||||
|
Pentium III |
0.18 |
133 |
< 1 |
16/16 |
256 |
+ |
+ |
+ |
+ |
+ |
2SMP |
Слот 1 |
||
|
ГГц |
||||||||||||||
|
Pentium 4 |
0.18 |
400 |
>1.4 |
8/8 |
256 |
+ |
+ |
+ |
+ |
+ |
— |
Сокет 423 |
||
|
ГГц |
||||||||||||||
**FRC – контроль с помощью функциональной избыточности *SMP – симметричные мультипроцессорные системы
значения во время выполнения операций MMX. Дополнительно введены восемь новых 64битных регистров. Одновременно обрабатываемое 64-битное слово может содержать как одну единицу обработки, так и восемь однобайтных, четыре двухбайтных или два четырехбайтных операндов.
Кроме ММХ-расширения в архитектуре Pentium MMX имеется ряд усовершенствований, повышающих его производительность.
В целочисленный конвейер после ступени PF введена дополнительная ступень F, на которой производится синтаксический разбор команд. Для увеличения точности предсказания переходов увеличены в два раза размер кэш-памяти команд и данных (16*16 Кбайт) и размер буфера адресов переходов (512 вхождений). Улучшена возможность параллельных вычислений (процессор способен выполнять две ОКМД команды с 16битными данными за 1 такт).
Суперскалярная архитектура Pentium MMX позволяет выполнять команды парами, с
учетом следующих ограничений:
1)АЛУ исполняет арифметические и логические операции. Наличие двух АЛУ позволяет выполнять эти команды парами на обоих конвейерах;
2)Устройство умножения исполняет все операции умножения за 3 такта, оно конвейеризовано, что позволяет получать результат от очередного запроса в каждом такте. Процессор имеет одно устройство умножения, так что операции умножения не могут исполняться парами. Однако они могут исполняться в паре с любыми другими командами. Умножения могут исполняться как на U, так и на V конвейерах.
3)Сдвиговое устройство выполняет все операции сдвигов, упаковки и распаковки. Так как это устройство одно, то эти команды могут выполняться в паре только с другими командами.
4)Команды ММХ-расширения, требующие доступа к памяти или к регистрам, могут выполняться только U конвейером и не могут выполняться в паре не с ММХ-командами.
Процессор Pentium2 основан на архитектуре Pentium Pro, в которую добавлено несколько исполнительных устройств для операций ММХ. Теперь порт0 дополнительно
содержит АЛУ ММХ и устройство умножения ММХ, а порт1− АЛУ ММХ и устройство сдвигов ММХ.
6.5.Процессор Pentium 4
Внастоящее время микропроцессоры Intel Pentium 4 имеют наивысшие тактовые частоты среди всех серийно выпускаемых процессоров. Сейчас в процессоре Pentium 4 частота достигла рубежа в 1,5 ГГц, в не столь отдаленном будущем можно ожидать рост частоты до 15 ГГц.
Первый Pentium 4 изготавливался по 0,18 – микронной технологии и содержал 42 млн. транзисторов. Однако площадь его кристалла вдвое больше, чем у Pentium 3. Он поставляется в защищенном корпусе FC – PGA и устанавливается в разъем Socket 423 с 423 контактами. Применение Pentium 4 требуют более дорогую память Rambus и интерфейсные БИС серии i850, которые используют 6-слойные материнские платы. Кроме этого, он имеет повышенное электропитание 52-55 Вт.
В2001 году был выпущен Pentium 4 с тактовой частотой 2 ГГц (2,26., 2,4., 2,53 ГГц). Он был реализован по 0,13 – микронной технологии, поддерживает системную шину на частоте 533 МГц. Объем кэш-памяти L2 доведен до 512 Кбайт. Чуть больше года потребовалось Intel, чтобы увеличить тактовую частоту процессора для ПК на 50% и преодолеть рубеж в 3 ГГц.
Главным достоинством Pentium 4 с частотой 3,06 ГГц заключается в том, что новый процессор – первый из семейства изделий, предназначенных для настольных ПК – поддерживает технологию Hyper Threading (многопоточная), которая дает заметный выигрыш в производительности (до 25%).
Суть технологии Hyper Threading состоит в том, что один физический процессор воспринимается операционной системой (ОС) как два логических процессора, благодаря чему эффективнее используются ресурсы компьютера. Эта технология специально разработана для применения в многозадачных средах многопоточных приложений. В перспективе тактовая частота микропроцессора для настольных систем к 2010 году достигнет 15 ГГц. Это в пять раз будет превышать частоту Pentium 4 и будет содержать около 1 млрд. транзисторов.
Для достижения высшей производительности Pentium 4 использовали два подхода: совершенствование микроархитектуры процессора и увеличение его тактовой частоты. Микроархитектура процессора Pentium 4 получила название NetBurst. Основной задачей микроархитектуры NetBurst состоит в том, чтобы обеспечить возможность дальнейшего роста тактовой частоты.
Одним из основных факторов увеличения тактовой частоты является совершенствование технологии изготовления. Здесь, несмотря на прогресс в технологии (прежде всего за счет уменьшения размеров элементов), приходится учитывать конечность скорости распространения сигнала (задержки, связанные с его распространением), которая накладывает определенные ограничения на рост тактовой частоты. Другим фактором увеличения тактовой частоты является использование гиперконвейера, как основного элемента микроархитектуры NetBurst.
Гиперконвейерный подход основан на уменьшение показателя, равного произведению числа стадий конвейера на время такта. Увеличение числа стадий конвейера приводит к тому, что каждая из них становится более простой и может быть выполнена за более короткое время такта.
Недостатком гиперконвейерного подхода является, как было рассмотрено ранее, проблема заполнения конвейера (перезагрузки при неверном предсказании перехода и наличие взаимозависимостей между командами).
Усовершенствования микроархитектуры NetBurst по сравнению с процессором P6 являются не столь кардинальными, как это было при переходе от Pentium к P6. Основные архитектурные идеи процессора P6, связанные с декодированием x86 – команд во внутренние RISCподобные микрооперации, их постановкой в очередь и внеочередным опережающим (спекулятивным) выполнением с последующим упорядочиванием завершившихся микроопераций, сохранились и в NetBurst.
Основные отличительные особенности архитектуры NetBurst следующие:
1)гиперконвейерная технология;
2)кэш трассировки исполнения (TC — Execution Trace Cache);
3)400-мегагерцовая системная шина;
4)механизм ускоренного выполнения (целочисленных АЛУ);
5)расширенное динамическое выполнение (одновременно до 126 команд);
6)потоковые расширения SSE2 (Streaming SIMD Extensions2);
7)усовершенствования функционального исполнительного устройства с плавающей запятой (мультимедийной обработки);
 усовершенствованная кэш-память.
усовершенствованная кэш-память.
6.5.1. Организация Pentium 4
Основные элементы микроархитектуры Pentium 4 представлены на рис. 6.18.
Вобщем случае логическая схема Pentium 4 соответствует структуре процессоров P6.
Внем можно выделить следующие логические блоки:
—устройство выборки/декодирования, называемое фронтальной частью Pentium 4;
—устройство планирования/выполнения, образующее исполнительное ядро процессора;
—устройство отката, соответствующее завершающей части процессора. Фронтальная часть является упорядоченным устройством процессора Pentium 4 и
состоит из следующих блоков: кэш-памяти первого и второго уровней (L1,L2); кэша трассировки ТС; ПЗУ микроопераций (постоянное запоминающее устройство — ROM); устройства предсказания переходов совместно с буфером адресов переходов (ВТВ) и декодера команд.
Фронтальная часть процессора обеспечивает предварительную выборку (Prefetch), декодирование команд (Instruction Decode), кэширование микроопераций в ТС и предсказание переходов.
Исполнительное ядро является неупорядоченной частью процессора и представляет собой базовый конвейер, который отвечает за выполнение микроопераций с элементами механизмов внеочередного и спекулятивного их исполнения. Он состоит из блока

распределения и переименования регистров, очереди микроопераций, планировщика, исполнительных устройств и файла регистров.
D — кэш L1 и D — TLB
|
АЛУ0 2xAЛУ1 2xAЛУ2 |
2xAGU1 2xAGU2 |
|
FP1 |
FP2 |
|
|
(ST, пересылка) |
(x,+,MMX, SSE) |
|
|
Файл целочисленных |
Файл регистров |
|
|
регистров |
с плавающей запятой |
|
Планировщик с плавающей запятой |
|
|
Общие |
FP — операции |
|
FP — операции |
с памятью |
|
Очередь целочисленных операций |
Очередь операций с памятью |
|||||||||||||||
|
и операций с плавающей |
||||||||||||||||
|
запятой |
||||||||||||||||
|
Переименование |
||||||||||||||||
|
и распределение |
||||||||||||||||
|
ВТВ |
ТС |
ROM микроопераций |
||||||||||||||
|
Декодер команд |
||||||||||||||||
|
кэш L2 |
I — TLB |
Динамическое предсказание переходов |
||||||||||||||
|
Системная шина |
Рис. 6.18. Основные элементы архитектуры Pentium 4
Блок распределения регистров в зависимости от типа микроопераций служит для выделения необходимых регистров для загрузки или записи в память. В Pentium 4 имеются 48 буферов для команд загрузки (L) и 24 буфера для команд записи (ST).
Блок переименования регистров служит для преобразования ссылок логических регистров процессора типа EAX в ссылки на физические регистры, количество которых в Pentium 4 равно 128. Работа с большим числом физических регистров позволяет снять взаимозависимости между микрооперациями типа WAW и WAR. Процессор Pentium 4 позволяет разрешать и зависимость типа RAW, используя метод одновременного использования данных (data forwarding). В этом случае, данные, которые команда ST записывает в память, обнаруживаются и направляются в команду L напрямую.
Очередь микроопераций Pentium 4 разбивается на две части: очереди операций с памятью и очереди целочисленных операций и операций с плавающей запятой. Существует 2 типа очередей микроопераций – один для операций с памятью (загрузка и хранение) и один для остальных операций. Каждые из этих двух типов очередей хранят микрооперации в структуре FIFO (First-In, First-Out). Микрооперации из каждой очереди могут быть прочитаны неупорядочено. Это позволяет планировщикам производить динамическое планирование (переупорядочивание) микроопераций.
Устройство планирования или планировщик служит для управления работой функциональных исполнительных устройств. Планировщик осуществляет прием потока
микроопераций, определяет зависимость между микрооперациями с последующим их разрешением и распределяет исполнительные устройства для выполнения микроопераций. Планировщик состоит из двух частей в зависимости от типа обрабатываемых данных: целочисленного планировщика и планировщика с плавающей запятой.
Целочисленный планировщик обрабатывает четыре потока данных поступающих из очереди микроопераций (рис. 6.18) среди них: один поток «медленных» целочисленных операций блока А (сложные, число микроопераций для одной инструкции превышает четырех); два потока «быстрых» целочисленных операций блока В (число микроопераций меньше 4 – это характерно для простых инструкций подчиняющих правилу сдваивания) и поток операций с памятью блока С для целочисленных данных.
Планировщик с плавающей запятой работает с двумя потоками данных: операциями с плавающей запятой и операциями с памятью для данных с плавающей запятой. Планировщик содержит четыре выходных порта, с помощью которых происходит взаимодействие с функциональными исполнительными устройствами.
Основу базового конвейера составляют функциональные исполнительные устройства конвейерного типа, количество которых равно семи. Устройства АЛУ1, АЛУ2 являются высокоскоростными и используются для обработки простых целочисленных инструкций, которые подключаются к портам 0 и 1 соответственно.
Устройства выполнения АЛУ1, АЛУ2 процессора Pentium 4 разрабатывались для оптимизации выполнения простых операций. Процессор Pentium 4 может выполнять простые, часто встречающиеся целочисленные операции АЛУ, на двойной тактовой частоте процессора. Устройства, позволяющие осуществлять такие вычисления, называются высокоскоростными АЛУ (Fast ALU). Процессор выполняет операции АЛУ на двойной частоте процессора за три быстрых цикла (быстрый цикл равен двойной частоте цикла процессора). Выполнение операций на двойной частоте процессора позволяет увеличить скорость выполнения для большинства программ почти в 2 раза.
Сложные целочисленные операции поступают на отдельный аппаратный узел, называемый медленное целочисленное АЛУ0 (Slow Integer ALU). Устройство АЛУ0 предназначено для обработки сложных целочисленных инструкций и подключается к порту 1. К сложным операциям относится большинство целочисленных сдвиговых операций, такие инструкции как shift и rotate. Эти операции выполняются за четыре такта процессора. Целочисленное умножение и деление также имеет большое время выполнения. Типичное умножение и деление выполняются за 14 и 60 тактов соответственно.
Для операций с памятью Pentium 4 располагает двумя исполнительными устройствами AGU1 и AGU2 (Address Generation Unit), которые подключаются к портам 2 и3 соответственно. Блок генерации адреса AGU1 служит для загрузки операндов из памяти, а блок AGU2 – для записи операндов в память.
Для обработки инструкций с плавающей запятой имеются два независимых конвейера FP1 и FP2. Устройство FP1 предназначено для обработки простых инструкций с плавающей точкой (FXCH, SSE Move, Store и др.) и подключено к порту 0. Для обработки сложных инструкций (сложение/умножение/деление, инструкции MMX и т.п.) служит устройство FP2, которое связано с портом 1. Кроме того, устройство FP2 дополнено специальными аппаратными средствами для реализации мультимедийного расширения SSE2.
Инструкции, включенные в SSE2 – расширение, позволяют ускорить работу таких приложений, как трехмерная графика, распознавание речи, обработка изображений и другие мультимедийные программы. В SSE2 включены 144 новых инструкций (дополнительно к 70 инструкциям SSE-расширения), которые работают с операндами, расположенными в памяти или XMM – регистрах.
Инструкции SSE позволяли оперировать с восемью 128-битными регистрами XMM0..XMM7, в которых хранились по четыре вещественных числа одинарной точности. При этом все SSE операции проводились одновременно над четверками чисел, в результате чего специально оптимизированные программы, в которых производилось большое
количество однотипных вычислений (а к ним, помимо обработки потоков данных в какой-то мере относятся и 3D-игры), получали существенный прирост производительности.
SSE2 же оперирует с теми же самыми регистрами XMM и обратно совместим с SSE процессора Pentium III. А расширение набора команд Pentium 4 вызвано тем, что теперь операции со 128-битными регистрами могут выполняться не только с четверками вещественных чисел одинарной точности, но и с парами вещественных чисел двойной точности. Процессор может работать также с шестнадцатью однобайтовыми целыми, с восемью короткими двухбайтовыми целыми, с четырьмя четырехбайтовыми целыми, с двумя восьми байтовыми целыми. То есть, теперь SSE2-расширение представляет собой симбиоз MMX и SSE и позволяет работать с любыми типами данных, вмещающимися в 128битные регистры.
Блок SSE2 инструкций реализован по архитектуре OKMD (SIMD) и относится к классу векторных конвейеров. Он поддерживает операции над двумерными векторами, элементами которых являются 64-разрядные числа с плавающей запятой двойной точностью. Использование этого блока позволяет Pentium 4 выполнять две операции с плавающей запятой двойной точности за 1 такт.
К недостаткам реализации SSE2 Pentium 4 можно отнести следующее: 80-разрядное представление чисел с плавающей точкой, используемые в x87-инструкциях, заменяется на 64-разрядное. Такая замена диктует необходимость перекомпиляции программного кода x87 инструкций. Неполная конвейеризация арифметических операций (64-разрядное умножение, сложение) приводит к пропуску одного такта между соседними инструкциями.
Файл регистров Pentium 4 играет роль накопителя, где хранятся операнды, участвующие при выполнении микроопераций и их результаты. Он содержит 128 регистров и разделяется на два файла: файла целочисленных регистров и файла регистров с плавающей запятой. Из них 48 регистров служат для загрузки операндов, 24 регистра для записи в память, а остальные для хранения результатов и переименования регистров. Завершающая часть процесса обеспечивает изымание результатов закончивших выполнение микроопераций из файла регистров и «сборку» из них результатов в порядке, задаваемом исходными программными кодами в соответствии с правилами архитектуры IA-32.
Фронтальная часть
Увеличение эффективной частоты системной шины до 400 МГц повысило максимальную, допустимую пропускную способность оперативной памяти до 3,2 Гбайт/сек. Это связано с увеличением тактовой частоты процессора и предполагает использование более дорогой быстродействующей памяти Rambus.
От системной шины данные и команды попадают в интегрированный в Pentium 4 кэш второго уровня емкостью 256 Кбайт, который по своим техническим характеристикам близок к используемому в Pentium III. Оба кэша работают на частоте ядра и являются 8- канальными наборно-ассоциативными, реализующий алгоритм обратной записи. Однако в Pentium 4 увеличена длина строки кэш L2-до 128 байт (2 сектора по 64 байт).
Задержка по обращению в кэш второго уровня составляет 7 тактов. Пропускная способность кэш L2 при частоте 1,5 ГГц составляет 48 Гбайт/сек. Для замещения информации в кэш L2 используется алгоритм псевдо-LRU. При непопадании в кэш L2 требуется 12 тактов процессора на организацию взаимодействия с системной шиной, и еще не менее 6-12 тактов шины (если она свободна) на доступ в подсистему оперативной памяти.
Кэш первого уровня является 4-канальным наборно-ассоциативным, использующий алгоритм сквозной записи, и имеет длину строки 64 байт. Емкость его уменьшилась вдвое по сравнению с Pentium III и составляет 8 Кбайт. Это уменьшение вызвано тем, чтобы обеспечить задержку выборки из кэша L2, равную 2 тактам (в предыдущих процессорах Intel она равнялась 3 тактам).