Доброго времени суток, друзья. Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).

SF — очень полезная программа для анализа внутрянки сайтов. С помощью этой утилиты можно быстро выцепить технические косяки сайта, чтобы составить грамотное ТЗ на доработку. Но чтобы увидеть проблему, надо правильно настроить краулера, верно? Об этом мы сегодня с вами и поговорим.
- Примечание автора: сразу скажу — программа имеет много вкладок и настроек, которые по сути не нужны рядовому пользователю, потому я подробно опишу только наиболее важные моменты, а второстепенные пройдем вскользь… хотя кого я обманываю, когда это у меня были статьи меньше 30 к символов? *Зануда mode on*
- Примечание автора 2: при написании статьи я пользовался дополнительными материалами в виде официального мануала от разработчиков. Если что, почитать его можно тут https://www.screamingfrog.co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.
- Примечание автора 3: я люблю оставлять примечания…
- File
- Configuration
- Spider — настройки парсинга сайта
- Robots.txt — определяем каким правилам следовать при парсинге
- URL Rewriting — функция перезаписи URL
- CDNs — парсим поддомены
- Include/Exclude — сканирование/удаление определенных папок
- Speed — регулируем скорость парсинга сайта
- User-Agent — выбираем под кого маскируемся
- HTTP Header — настройка реагирования на разные http-заголовки
- Custom — дополнительные настройки поиска
- User Interface — обнуление настроек для колонок таблицы
- API Access — интеграция с разными сервисами
- Authentification — настройки аутентификации
- System — внутренние настройки самой программы
- Mode
- Bulk export
- Reports
- Sitemaps
- Visualisations
- Crawl Analysis
- License
- Help
Настройка Screaming Frog по шагам
Рассмотрим основное меню программы, для того чтобы понимать что где лежит и что за что отвечает (тавтология… Вова может в копирайт!).

Верхнее меню — управление парсингом, выгрузкой и многое другое
File
Из названия понятно, что это работа с файлами программы (загрузка проектов, конфиги, планирование задач — что-то вроде того).

- Open — открыть файл с уже проведенным парсингом.
- Open Recent — открыть последний парсинг (если вы его сохраняли отдельным файлом).
- Save — собственно, сохранить парсинг.
- Configuration — загрузка/сохранение специальных настроек парсинга вроде выведения дополнительных параметров проверки и т.д. (про то, как задавать эти настройки, я далее расскажу подробнее).
- Crawl Recent — повторно парсить один из последних сайтов, который уже проверялся в этой программе.
- Scheduling — отложенное планирование задач для программы… ни разу не пользовался этой опцией…стыдно.
- Exit — призвать к ответу Друзя… нет, ну серьезно,тут все очевидно.

Configuration
Один из самых интересных и важных пунктов меню, тут мы задаем настройки парсинга.

Ох, сейчас будет сложно — у многих пунктов есть подпункты, у этих подпунктов всплывающие окна с вкладками и кучей настроек…в общем крепитесь, ребята, будет много инфы.
Spider — собственно, настройки парсинга сайта

Вкладка Basic — выбираем что парсить
- Check Images — в отчет включаем анализ картинок.
- Check CSS — в отчет включаем анализ css-файлов (скрипты).
- Check JavaScript — в отчет включаем анализ JS-файлов (скрипты).
- Check SWF — в отчет включаем анализ Flash-анимации.
- Check External Link — в отчет включаем анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder — проверка ссылок вне стартовой папки. Т.е. отчет будет только по стартовой папке, но с учетом ссылок всего сайта.
- Follow internal “nofollow” — сканировать внутренние ссылки, закрытые в тег “nofollow”.
- Follow external “nofollow” — сканировать ссылки на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains — парсить все поддомены сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder — позволяет сканировать весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals — выведение в отчете атрибута rel=”canonical” при сканировании страниц.
- Crawl Next/Prev — выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang — при сканировании учитываются языковой атрибут hreflang и отображаются коды языка и региона страницы + формирование отчета по таким страницам.
- Extract AMP Links/Crawl AMP Links — извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap — сканирование карты сайта. Тут краулер либо берет sitemap из robots.txt (Auto Discover XML Sitemap via robots.txt), либо берет карту по указанному пользователем пути (Crawl These Sitemaps).
Ну что, сложно? На самом деле просто нужна привычка и немного практики, чтобы освоить основные настройки SF и понять что нужно использовать в конкретных случаях, а от чего можно отказаться. Все, передохнули, теперь дальше… будет проще (нет).
Вкладка Limits — определяем лимиты парсинга

- Limit Crawl Total — задаем лимиты страниц для сканирования. Сколько всего страниц выгружаем для одного проекта.
- Limit Crawl Depth — задаем глубину парсинга. До какого уровня может дойти краулер при сканировании проекта.
- Limit Max Folder Depth — можно контролировать глубину парсинга вплоть до уровня вложенности папки.
- Limit Number of Query Strings — тут, если честно, сам не до конца разобрался, потому объясню так, как понял — мы ограничиваем лимит страниц с параметрами. Другими словами, если на одной статической странице есть несколько фильтров, то их комбинация может породить огромное количество динамических страниц. Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
- Max Redirects to Follow — задаем максимальное количество редиректов, по которым паук может переходить с одного адреса.
- Max URL Length to Crawl — максимальная длина URL для обхода (указываем в символах, я так понимаю).
- Max Links per URL to Crawl — максимальное количество ссылок на URL для обхода (указываем в штуках).
- Max Page Size (KB) to Crawl — максимальный размер страницы для обхода (указываем в килобайтах).
Вкладка Rendering — настраиваем параметры рендеринга (только для JS)

На выбор три опции — “Text Only” (паук анализирует только текст страницы, без учета Аякса и JS), “Old AJAX Crawling Scheme” (проверяет по устаревшей схеме сканирования Аякса) и “JavaScript” (учитывает скрипты при рендеринге). Детальные настройки есть только у последнего, их и рассмотрим.

- Enable Rendered Page Screen Shots — SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) — лимиты таймаута. Как долго SEO Spider должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size — выбор размера окна (много их — смотрим скриншот).
- Sample — пример окна (зависит от выбранного Window Size).
- Чекбокс Rotate — повернуть окно в Sample.
Вкладка Advanced — дополнительные опции парсинга

- Allow Cookies — учитывать Cookies, как это делает поисковый бот.
- Pause on High Memory Used — тормозит сканирование сайта, если процесс забирает слишком много оперативной памяти.
- Always Follows Redirect — разрешаем краулеру идти по редиректам вплоть до финальной страницы с кодом 200, 4хх, 5хх (по факту все ответы сервера, кроме 3хх).
- Always Follows Canonicals — разрешаем краулеру учитывать все атрибуты “canonical” вплоть до финальной страницы. Полезно, если на страницах сайта бардак с настройкой этого атрибута (например, после нескольких переездов).
- Respect Noindex — страницы с “noindex” не отображаются в отчете SF.
- Respect Canonical — учет атрибута “canonical” при формировании итогового отчета. Полезно, если у сайта много динамических страниц с настроенным rel=”canonical” — позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Respect Next/Prev — учет атрибутов rel=”next”/”prev” при формировании итогового отчета. Полезно, если у сайта есть страницы пагинации с настроенными “next”/”prev”- позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Extract Images from img srscet Attribute — изображения извлекаются из атрибута srscet тега <img>. SRSCET — атрибут, который позволяет вам указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy — если чекбокс активен, SF будет выполнять все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код состояния за перенаправлением (например, постоянный редирект 301).
- Respect Self Referencing Meta Refresh — учитывать принудительную переадресацию на себя же (!) по метатегу Refresh.
- Response Timeout — время ожидания ответа страницы, перед тем как парсер перейдет к анализу следующего урла. Можно сделать больше (для медленных сайтов), можно меньше.
- 5хх Response Retries — количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML — можно сохранить статический HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть его до того, как JavaScript “вступит в игру”.
- Store Rendered HTML — позволяет сохранить отображенный HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD — извлекаем микроразметку сайта JSON-LD. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract Microdata — извлекаем микроразметку сайта Microdata. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract RDFa — извлекаем микроразметку сайта RDFa. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
Вкладка Preferences — так называемые “предпочтения”
Здесь задаем желаемые параметры для некоторых сканируемых элементов (title, description, url, H1, H2, alt картинок, размер картинок). Соответственно, если сканируемые элементы сайта не будут соответствовать нашим предпочтениям, программа нам об этом сообщит в научно-популярной форме. Совершенно необязательные настройки — каждый прописывает для себя свой идеал… или вообще их не трогает, от греха подальше (как делаю я).

- Page Title Width — оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width — оптимальная ширина описания страницы. Аналогично, как и с тайтлом, указываем желаемые размеры.
- Other — сюда входит максимальная желаемая длина урл-адреса в символах (Max URL Length Chars), максимальная длина H1 в символах (Max H1 Length Chars), максимальная длина H2 в символах (Max H2 Length Chars), максимальная длина ALT картинок в символах (Max Image Length Chars) и максимальный вес картинок в КБ (Max Image Size Kilobytes).
Robots.txt — определяем каким правилам следовать при парсинге

Вкладка Settings — настраиваем парсинг относительно правил robots.txt

- Respect robots.txt — следуем всем правилам, прописанным в robots.txt. Т.е. учитываем в анализе те папки и файлы, которые открыты для робота.
- Ignore robots.txt — не учитываем robots.txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
- Ignore robots.txt but report status — не учитываем robots.txt сайта при парсинге, однако в дополнительном меню выводится статус страницы (индексируемая или не индексируемая).
- Show internal/external URLs blocked by robots.txt — отмечаем в чекбоксах хотим ли мы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации в robots.txt. Данная опция работает только при условии выбора “Respect robots.txt”.

Вкладка Custom — ручное редактирование robots.txt в пределах текущего парсинга
Удобно, если вам нужно при парсинге сайта учитывать (или исключить) только определенные папки, либо же добавить правила для поддоменов. Кроме того, можно быстро сформировать и проверить свой рабочий robots, чтобы потом залить его на сайт.

Шаг 1. Прописать анализируемый домен в основной строке

Шаг 2. Кликнуть на Add, чтобы добавить robots.txt домена
Тут на самом деле все очень просто, поэтому я по верхам пробегусь по основным опциям (а в конце будет видео, где я бездумно прокликиваю все кнопки).

- Блок Subdomains — сюда, собственно, можно добавлять домены/поддомены, robots.txt которых мы хотим учитывать при парсинге сайта.
- Окно справа — для редактирования выгруженного robots.txt. Итоговый вариант будет считаться каноничным для парсера.
- Окошко снизу — проверка индексации url в зависимости от настроенного robots.txt. Справа выводится статус страницы (Allowed или Disallowed).
URL Rewriting — функция перезаписи URL «на лету»

Тут мы можем настроить перезапись урл-адресов домена прямо в ходе парсинга. Полезно, когда нужно заменить определенные регулярные выражения, которые засоряют итоговый отчет по парсингу.
Вкладка Remove Parameters
Вручную вводим параметры, которые нужно удалять из url при анализе сайта, либо исключить вообще все возможные параметры (чекбокс “Remove all”). Полезно, если у страниц сайта есть идентификаторы сеансов, отслеживание контекста (utm_source, utm_medium, utm_campaign) или другие фишки.

Вкладка Regex Replace
Изменяет все сканируемые урлы с использованием регулярных выражений. Применений данной настройки масса, я приведу только несколько самых распространенных примеров:

- Изменение всех ссылок с http на https (Регулярное выражение: http Заменить: https).
- Изменение всех ссылок на site.by на site.ru (Регулярное выражение: .by Заменить: .ru).
- Удаление всех параметров (Регулярное выражение: \?. * Заменить: ).
- Добавление параметров в URL (Регулярное выражение: $ Заменить: ?ПАРАМЕТР).
Вкладка Options
Вы рассчитывали увидеть здесь еще 100500 дополнительных опций для суперточной настройки URL Rewriting, я прав? Как бы странно это ни звучало, но здесь мы всего лишь определяем перезаписывать все прописные url-адреса в строчные или нет… вот как-то так, не спрашивайте, я сам не знаю почему для этой опции сделали целую отдельную вкладку.

Вкладка Test
Тут мы можем предварительно протестировать видоизменение url перед началом парсинга и, соответственно, подправить регулярные выражения, чтобы на выходе не получилось какой-нибудь ерунды.

CDNs — парсим поддомены, не отходя от кассы
Использование настройки CDNs позволяет включать в парсинг дополнительные домены/поддомены/папки, которые будут обходиться пауком и при этом считаться внутренними ссылками. Полезно, если нужно проанализировать массив сайтов, принадлежащих одному владельцу (например, крупный интернет-магазин с сетью сайтов под регионы). Также можно прописывать регулярные выражения на конкретные пути сканирования — т.е. парсить только определенные папки.

Во вкладке Test можно посмотреть как будут определяться урлы в зависимости от используемых параметров (Internal или External).
Include/Exclude — сканирование/удаление определенных папок

Можно регулярными выражениями задать пути, которые будут сканироваться внутри домена. Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.

Выбираем папки для парсинга

Удаляем папки из парсинга
Примеры регулярных выражений для Exclude:
- http://site.by/obidnye-shutki-pro-seo.html (исключение конкретной страницы).
- http://site.by/obidnye-shutki-pro-seo/.* (исключение целой папки).
- http://site.by/.*/obidnye-shutki-pro-seo/.* (исключение всех страниц, после указанной).
- .*\?price.* (исключение страниц с определенным параметром).
- .*jpg$ (исключение файлов с определенным расширением).
- .*seo.* (исключение страниц с вхождением в url указанного слова).
- .*https.* (исключение страниц с https).
- http://site.by/.* (исключение всех страниц домена/поддомена).
Speed — регулируем скорость парсинга сайта

Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов. Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.

User-Agent — выбираем под кого маскируемся

В списке user-agent можно выбрать от лица какого бота будет происходить парсинг сайта. Удобно, если в настройках сайта есть директивы, блокирующие того или иного бота (например, запрещен google-bot). Также полезно иногда прокраулить сайт гугл-ботом для смартфона, чтобы проверить косяки адаптива или мобильной версии.


Скажу сразу — это опция очень индивидуальна, лично я ее не пользую, потому что чаще всего незачем. В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.

Т.е. можно индивидуально настроить, например, какого формата контент обрабатывать, учитывать ли cookie и т.д. Нюансов там довольно много.

Custom — дополнительные настройки поиска по исходному коду

Custom Search
По сути обычный фильтр, с помощью которого можно вытягивать дополнительные данные, например, страницы, в которых вместо тега <strong> используется <bold> или еще лучше — страницы, которые НЕ содержат определенного контента (например, без кода счетчика метрики). Фактически в настройках можно задать все что угодно.

Custom Extraction
Это пользовательское извлечение любых данных из html (например, текстовое содержимое).

User Interface — обнуление настроек для колонок таблицы
Просто сбрасывает сортировку столбцов, ничего особенного, проходим дальше, граждане, не толпимся.

API Access — интеграция с разными сервисами
Для того чтобы получать больше данных по сайту, можно настроить интеграцию с разными сервисами статистики типа Google Analytics или Majestic, при условии того, что у вас есть аккаунт в этом сервисе.

При этом для каждого сервиса отдельные настройки выгрузки по типам данных.

На примере GA
Authentification — настройки аутентификации (если есть запрос от сайта)

Есть два вида аутентификации — Standart Based и Form Based. По умолчанию используется Standart Base — если при парсинге от сайта приходит запрос на аутентификацию, в программе появляется соответствующее окно.

Form Based — использование для аутентификации встроенного в SF браузера (полезно, когда для подтверждения аутентификации нужно, например, пройти капчу). В данном случае необходимо вручную вводить урл сайта и в открывшемся окне браузера вводить логин/пароль, кликать recaptcha и т.д.

System — внутренние настройки самой программы
Настройки работы самой программы — сколько оперативной памяти выделять на процесс, куда сохранять экспорт и т.д.

Давайте как обычно — подробнее о каждом пункте.
- Memory — выделяем лимиты оперативной памяти для парсинга. По дефолту стоит 2GB, но можно выделить больше (если ПК позволяет).

- Storage — выбор базы для хранения данных. Либо сохранение в ОЗУ (для этого у SF есть свой движок), либо в указанной папке на ПК пользователя.

- Proxy — подключение прокси-сервера для парсинга.

- Embedded Browser — использование встроенного в программу браузера (вкл/выкл).

Mode
- Spider (Режим паука) — классический парсинг сайта по внутренним ссылкам. Просто вводим нужный домен в адресную строку программы и запускаем работу.
- List — парсим только предварительно собранный список урл-адресов! Адреса можно выгрузить из файла (From a file), вбить вручную (Enter Manually), подтянуть их из карты сайта (Download Sitemap) и т.д. Если честно, этих трех способов получения списка урлов должно быть более чем достаточно.
- SERP Mode — в этом режиме нет сканирования, зато здесь можно загружать мета-данные сайта, редактировать их и предварительно понимать как они будут отображаться в браузере. Делать все это можно пакетно, что вполне себе удобно.
Bulk export
В этом пункте меню висят все опции SF, отвечающие за массовый экспорт данных из основного и дополнительного меню отчета…сейчас покажу на скриншоте.

В общем и целом с помощью bulk export можно вытянуть много разной полезной информации для последующей постановки ТЗ на доработки. Например, выгрузить в excel страницы, на которых найдены ссылки с 3хх ответом сервера + сами 3хх-ссылки, что позволяет сформировать задание для программиста или контент-менеджера (зависит от того, где зашиты 3хх-ссылки) на замену этих 3хх-ссылок на прямые с кодом 200. Теперь подробнее про то, что можно экспортировать при помощи Bulk Export.

- All Inlinks — получаем все входящие ссылки на каждый URI, с которым столкнулся краулер при сканировании сайта.
- All Outlinks — получаем все исходящие ссылки с каждого URI, с которым столкнулся краулер при сканировании сайта.
- All Anchor Text — выгрузка анкоров всех ссылок.
- All Images — выгрузка всех картинок (урл-адресами, естественно).
- Screenshots — экспорт снимков экрана.
- All Page Source — получаем статический HTML-код или обработанный HTML-код просканированных страниц (рендеринг HTML доступен только в режиме рендеринга JavaScript) .
- External Links — все внешние ссылки со всех просканированных страниц.
- Response Codes — все страницы в зависимости от выбранного кода ответа сервера (закрытые от индекса, с кодом 200, с кодом 3хх и т.д.).
- Directives — все страницы с директивами в зависимости от выбранной (Index Inlinks, Noindex Inlinks, Nofollow Inlinks и т.д.).
- Canonicals — страницы, содержащие канонические атрибуты, страницы без указания этих атрибутов, каноникализированные (*перекрестился*) страницы и т.д.
- AMP — страницы с AMP, ссылки с AMP (но код ответа не 200) и т.д.
- Structured Data — выгрузка страниц с микроразметкой.
- Images — выгрузка картинок без альт-текста, тяжелых картинок (в соответствии с указанным в настройках размером).
- Sitemaps — выгрузка всех страниц в карте сайта, неиндексируемых страниц в карте сайта и проч.
- Custom — выгрузка пользовательских фильтров.
Reports
Здесь содержится множество различных отчетов, которые также можно выгрузить.

- Crawl Overview — в этом отчете содержится сводная информация о сканировании, включая такие данные, как количество найденных URL-адресов, заблокированных robots.txt, число сканированных, тип контента, коды ответов и т. д.
- Redirect & Canonical Chains — отчет о перенаправлении и канонических цепочках. Здесь отображаются цепочки перенаправлений и канонических символов, показывается количество переходов по пути и идентифицируется источник, а также цикличность (если есть).
- Non-Indexable Canonicals — здесь можно получить выгрузку, в которой освещаются ошибки и проблемы с canonical. В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
- Pagination — ошибки и проблемы с атрибутами rel=”next” и rel=”prev”, которые используются для обозначения содержимого, разбитого на пагинацию.
- Hreflang — проблемы с атрибутами hreflang (некорректный ответ сервера, страницы, на которые нет гиперссылок, разные коды языка на одной странице и т.д.).
- Insecure Content — показаны любые защищенные (HTTPS) URL-адреса, на которых есть небезопасные элементы, такие как внутренние ссылки HTTP, изображения, JS, CSS, SWF или внешние изображения в CDN, профили социальных сетей и т. д.
- SERP Summary — этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и мета-описания с соответствующими длинами символов и шириной в пикселях.
- Orphan Pages — список потерянных страниц, собранных из Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными во время парсинга.
- Structured Data — отчет содержит данные об ошибках валидации микроразметки страниц.
Sitemaps
С помощью этого пункта можно сгенерировать XML-карту сайта (страницы и картинки).

Все просто — выбираем что будем генерировать. В появившемся окне при необходимости выбираем нужные параметры и создаем карту сайта, которую потом заливаем в корневой каталог сайта.
Рассмотрим подробнее параметры, которые нам предлагают выбрать при генерации карты сайта.

Вкладка Pages — выбираем какие типы страниц включить в карту сайта.
- Noindex Pages — страницы, закрытые от индексации.
- Canonicalised — каноникализированные (опять это страшное слово!) страницы . Другими словами, динамика, у которой есть rel=”canonical”.
- Paginated URLs — страница пагинации.
- PDFs — PDF-документы.
- No response — страницы с кодом ответа сервера 0 (не отвечает).
- Blocked by robots.txt — страницы закрытые от индекса в robots.txt.
- 2xx — страницы с кодом 2хх (они будут в карте в любом случае).
- 3хх — страницы с кодом ответа 3хх (редиректы).
- 4хх — страницы с кодом ответа 4хх (битые ссылки на несуществующие страницы).
- 5хх — страницы с кодом ответа 5хх (проблема сервера при загрузке).
Вкладка Last Modified — выставляем дату последнего обновления карты.

- nclude <lastmod> tag — использовать в sitemap тег <lastmod> (дата последнего обновления карты).
- Use server report — использовать ответ сервера при создании карты, либо проставить дату вручную.
Вкладка Priority — выставляем приоритет ссылки в зависимости от глубины залегания страницы.

- Include <priority> tag — добавляет в карту сайта тег <priority>, показывающий приоритет страницы.
- Crawl Depth 0-5+ — в зависимости от глубины залегания страницы, можно проставить ее приоритет сканирования для поискового робота.
Вкладка Change Frequency — выставляем вероятную частоту обновления страниц.

- Include <changefreq> tag — использовать тег <changefreq> в карте сайта. Показывает частоту обновления страницы.
- Calculate from Last Modified header — рассчитать тег по последнему измененному заголовку.
- Use crawl depth settings — проставить тег в зависимости от глубины страницы.
Вкладка Images — добавляем картинки в карту сайта.

- Include Images — выводить в общей карте сайта картинки.
- Include Noindex Images — добавить картинки, закрытые от индекса.
- Include only relevant Images with up to … inlinks — добавить только картинки с заданным числом входящих ссылок.
- Regex list of CDNs hosting images to be included — честно, так и не понял что это такое… возможно настройка выгрузки в карту сайта картинок из хостинга (т.е. можно вбить списком несколько хостов и оттуда подтянуть картинки), но это всего лишь мои предположения.
Вкладка Hreflang — использовать в sitemap атрибут <hreflang> (или не использовать).

Visualisations
Это выбор интерактивной визуализации структуры сайта в программе. Можно получить отображение дерева сканирования и дерева каталогов. Основная фишка в том, что открываются эти карты и диаграммы во встроенном браузере программы, что позволяет эффективнее с ними работать (настраивать выведение, масштабировать, перескакивать к нужным урлам через поиск и т.д.).

Crawl Tree Graph — визуализация сканирования. По факту после завершения краулинга показывает текущую структуру сайта на основании анализа.

Directory Tree Graph — показывает ВСЕ каталоги после сканирования. Т.е. отличие от Crawl Tree Graph в том, что в этом отчете показываются, например, папки, закрытые от индекса.

Назначение Crawl Tree Graph и Directory Tree Graph в основном заключается в упрощении анализа структуры текущего сайта, можно глазами пробежаться по всем папкам, зацепиться за косяки (т.к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h1, h2 и т.д.).

Force Directed Crawl-Diagram — по сути то же самое, что и Crawl Tree Graph, только оформленное по-другому + показывает сканирование сайта относительно главной страницы (ну или стартовой). Кому-то покажется нагляднее, хотя по мне, выглядит гораздо сложнее для восприятия.

Force Directed Tree-Diagram — аналогично, другой тип визуализации дерева каталогов сайта.

Inlink Anchor Text Word Cloud — визуализация анкоров (ссылочного текста) внутренней ссылки. Анализирует каждую страницу по-отдельности. Помогает понять какими анкорами обозначена страница, как их много, насколько разнообразны и т.д.

Р- Разнообразие
Body Text Word Cloud — визуализация плотности отдельных слов на странице. По сути выглядит так же, как и Inlink Anchor Text Word Cloud, так что отдельный скрин делать смысла особого нет — обычное облако слов, по размеру можно определить какое слово встречается чаще, по общему числу посмотреть разнообразие слов на странице и т.д.
Каждая визуализация имеет массу настроек вывода данных, маркировки — про них я писать не буду, если станет интересно, сами поиграетесь, ок? Там ничего сложного.

Crawl Analysis

Большинство параметров сайта вычисляется пауком в ходе сбора статистики, однако некоторые данные (Link Score, некоторые фильтры и прочее) нуждаются в дополнительном анализе, чтобы попасть в финальный отчет. Данные, которые нуждаются в Crawl Analysis, помечены соответствующим образом в правом меню навигации.

Crawl Analysis запускается после основного парсинга. Перед запуском дополнительного анализа, можно настроить его (какие данные выводить в отчет).

- Link Score — присвоение оценок всем внутренним ссылкам сайта.
- Pagination — показывает петлевые пагинации, а также страницы, которые обнаружены только через атрибуты rel=”next”/”prev”.
- Hreflang — урлы hreflang без гиперссылки, битые ссылки.
- AMP — страницы без тегов “html amp”, теги не с 200 кодом ответа.
- Sitemaps — неиндексируемые страницы в карте сайта, урлы в нескольких картах сайта, потерянные страницы (например, есть в Google Analytics, есть в sitemap, не обнаружено при парсинге), страницы, которых нет в карте сайта, страницы в карте сайта.
- Analytics — потерянные страницы (есть в аналитике, нет в парсинге).
- Search Console — потерянные страницы (есть в вебмастере, нет в парсинге).
License
Исходя из названия, логично предположить, что этот пункт меню отвечает за разного рода манипуляции с активацией продукта…иии так оно и есть!

Buy a License — купить лицензию. При клике переход на соответствующую страницу официалов https://www.screamingfrog.co.uk/seo-spider/licence/. Стоимость ключа для одного ПК — 149 фунтов стерлинга. Есть пакеты для нескольких ПК, там, как обычно, идут скидки за опт.

Enter License — ввести логин и ключ лицензии, чтобы активировать полный функционал парсера.

Заметили, да? Лицензия покупается на год, не бессрочная
Help
Помощь юзеру — гайды, FAQ, связь с техподдержкой, в общем все, что связано с работой программы, ее багами и их решением.

- User Guide — мануал по работе с программой. Собственно, его я использовал, как один из источников, для написания этой статьи. При желании, можете ознакомиться, если я что-то непонятно рассказал или не донес. Еще раз оставлю ссылку https://www.screamingfrog.co.uk/seo-spider/user-guide/.
- FAQ — часто задаваемые вопросы по работе с SF и ответы на них https://www.screamingfrog.co.uk/seo-spider/faq/.
- Support — обратная связь с техподдержкой https://www.screamingfrog.co.uk/seo-spider/support/. Если программа ведет себя некрасиво (например, не принимает ключ лицензии), можно пожаловаться куда надо и все починят.
- Feedback — обратная связь. Та же самая страница, что и в Support. Т.е. можно не только жаловаться, но и вносить предложения по работе программы, предлагать партнерку, сказать банальное “спасибо” за такой крутой сервис (думаю ребятам будет приятно).
- Check for Updates и Auto Check for Updates — проверка на наличие обновлений программы. Screaming Frog нерегулярно, но довольно часто дорабатывается, поэтому есть смысл периодически проверять апдейты. Но лучше поставить галочку на Auto Check for Updates и программа сама будет автоматически предлагать обновиться при выходе нового апа.
- Debug — отчет о текущем состоянии программы. Нужно, если вы словили какой-то баг и хотите о нем сообщить разработчику. Там еще дополнительно есть настройки дебага, но я думаю, нет смысла заострять на этом внимание.
- About — собственно, краткая информация о самой программе (копирайт, сервисы, которые использовались при разработке).
Итог
Screaming Frog — очень гибкая в плане настройке утилита, с помощью которой можно вытянуть массу данных для анализа, нужно только (только… ха-ха) правильно настроить парсинг. Я надеюсь, мой мануал поможет вам в этом, хотя и не все я рассмотрел как надо, есть пробелы, но основные функции должны быть понятны.
Теперь от себя — текста много, скринов много, потому, если вы начинающий SEO-специалист, рекомендую осваивать SF поэтапно, не хватайтесь за все сразу, ибо есть шанс упустить важные нюансы.
Ну вот и все, ребята, я отчаливаю за новым материалом для нашего крутого блога. Подписывайтесь, чтобы не пропустить интересные публикации от меня и моих коллег. Всем удачи, всем пока!
Оригинал статьи взят с сайта MAXI.BY media
Attention! Много букв! Много скринов! Много смысла!
Доброго времени суток, друзья. Сегодня я хочу рассказать вам о настройке Screaming Frog (он же SF, он же краулер, он же паук, он же парсер — сразу определимся со всеми синонимами, ок?).
SF — очень полезная программа для анализа внутрянки сайтов. С помощью этой утилиты можно быстро выцепить технические косяки сайта, чтобы составить грамотное ТЗ на доработку. Но чтобы увидеть проблему, надо правильно настроить краулера, верно? Об этом мы сегодня с вами и поговорим.
- Примечание автора: сразу скажу — программа имеет много вкладок и настроек, которые по сути не нужны рядовому пользователю, потому я подробно опишу только наиболее важные моменты, а второстепенные пройдем вскользь… хотя кого я обманываю, когда это у меня были статьи меньше 30 к символов? *Зануда mode on*
- Примечание автора 2: при написании статьи я пользовался дополнительными материалами в виде официального мануала от разработчиков. Если что, почитать его можно тут https://www.screamingfrog.co.uk/seo-spider/user-guide/. Не пугайтесь английского, Google-переводчик в помощь — вполне себе сносная адаптация получается.
- Примечание автора 3: я люблю оставлять примечания…
- File
- Configuration
- Spider — настройки парсинга сайта
- Robots.txt — определяем каким правилам следовать при парсинге
- URL Rewriting — функция перезаписи URL
- CDNs — парсим поддомены
- Include/Exclude — сканирование/удаление определенных папок
- Speed — регулируем скорость парсинга сайта
- User-Agent — выбираем под кого маскируемся
- HTTP Header — настройка реагирования на разные http-заголовки
- Custom — дополнительные настройки поиска
- User Interface — обнуление настроек для колонок таблицы
- API Access — интеграция с разными сервисами
- Authentification — настройки аутентификации
- System — внутренние настройки самой программы
- Mode
- Bulk export
- Reports
- Sitemaps
- Visualisations
- Crawl Analysis
- License
- Help
Настройка Screaming Frog по шагам
Рассмотрим основное меню программы, для того чтобы понимать что где лежит и что за что отвечает (тавтология… Вова может в копирайт!).

Верхнее меню — управление парсингом, выгрузкой и многое другое
File
Из названия понятно, что это работа с файлами программы (загрузка проектов, конфиги, планирование задач — что-то вроде того).

- Open — открыть файл с уже проведенным парсингом.
- Open Recent — открыть последний парсинг (если вы его сохраняли отдельным файлом).
- Save — собственно, сохранить парсинг.
- Configuration — загрузка/сохранение специальных настроек парсинга вроде выведения дополнительных параметров проверки и т.д. (про то, как задавать эти настройки, я далее расскажу подробнее).
- Crawl Recent — повторно парсить один из последних сайтов, который уже проверялся в этой программе.
- Scheduling — отложенное планирование задач для программы… ни разу не пользовался этой опцией…стыдно.
- Exit — призвать к ответу Друзя… нет, ну серьезно,тут все очевидно.

Configuration
Один из самых интересных и важных пунктов меню, тут мы задаем настройки парсинга.

Ох, сейчас будет сложно — у многих пунктов есть подпункты, у этих подпунктов всплывающие окна с вкладками и кучей настроек…в общем крепитесь, ребята, будет много инфы.
Spider — собственно, настройки парсинга сайта

Вкладка Basic — выбираем что парсить
- Check Images — в отчет включаем анализ картинок.
- Check CSS — в отчет включаем анализ css-файлов (скрипты).
- Check JavaScript — в отчет включаем анализ JS-файлов (скрипты).
- Check SWF — в отчет включаем анализ Flash-анимации.
- Check External Link — в отчет включаем анализ ссылок с сайта на другие ресурсы.
- Check Links Outside of Start Folder — проверка ссылок вне стартовой папки. Т.е. отчет будет только по стартовой папке, но с учетом ссылок всего сайта.
- Follow internal “nofollow” — сканировать внутренние ссылки, закрытые в тег “nofollow”.
- Follow external “nofollow” — сканировать ссылки на другие сайты, закрытые в тег “nofollow”.
- Crawl All Subdomains — парсить все поддомены сайта, если ссылки на них встречаются на сканируемом домене.
- Crawl Outside of Start Folder — позволяет сканировать весь сайт, однако проверка начинается с указанной папки.
- Crawl Canonicals — выведение в отчете атрибута rel=”canonical” при сканировании страниц.
- Crawl Next/Prev — выведение в отчете атрибутов rel=”next”/”prev” при сканировании страниц пагинации.
- Extract hreflang/Crawl hreflang — при сканировании учитываются языковой атрибут hreflang и отображаются коды языка и региона страницы + формирование отчета по таким страницам.
- Extract AMP Links/Crawl AMP Links — извлечение в отчет ссылок с атрибутом AMP (определение версии контента на странице).
- Crawl Linked XML Sitemap — сканирование карты сайта. Тут краулер либо берет sitemap из robots.txt (Auto Discover XML Sitemap via robots.txt), либо берет карту по указанному пользователем пути (Crawl These Sitemaps).
Ну что, сложно? На самом деле просто нужна привычка и немного практики, чтобы освоить основные настройки SF и понять что нужно использовать в конкретных случаях, а от чего можно отказаться. Все, передохнули, теперь дальше… будет проще (нет).
Вкладка Limits — определяем лимиты парсинга

- Limit Crawl Total — задаем лимиты страниц для сканирования. Сколько всего страниц выгружаем для одного проекта.
- Limit Crawl Depth — задаем глубину парсинга. До какого уровня может дойти краулер при сканировании проекта.
- Limit Max Folder Depth — можно контролировать глубину парсинга вплоть до уровня вложенности папки.
- Limit Number of Query Strings — тут, если честно, сам не до конца разобрался, потому объясню так, как понял — мы ограничиваем лимит страниц с параметрами. Другими словами, если на одной статической странице есть несколько фильтров, то их комбинация может породить огромное количество динамических страниц. Вот чтобы такие “полезные” страницы не парсились (увеличивает время анализа в разы, а толковой информации по сути ноль), мы и выводим лимиты по Query Strings. Пример динамики — site.ru/?query1&query2&query3&queryN+1.
- Max Redirects to Follow — задаем максимальное количество редиректов, по которым паук может переходить с одного адреса.
- Max URL Length to Crawl — максимальная длина URL для обхода (указываем в символах, я так понимаю).
- Max Links per URL to Crawl — максимальное количество ссылок на URL для обхода (указываем в штуках).
- Max Page Size (KB) to Crawl — максимальный размер страницы для обхода (указываем в килобайтах).
Вкладка Rendering — настраиваем параметры рендеринга (только для JS)

На выбор три опции — “Text Only” (паук анализирует только текст страницы, без учета Аякса и JS), “Old AJAX Crawling Scheme” (проверяет по устаревшей схеме сканирования Аякса) и “JavaScript” (учитывает скрипты при рендеринге). Детальные настройки есть только у последнего, их и рассмотрим.

- Enable Rendered Page Screen Shots — SF делает скриншоты анализируемых страниц и сохраняет их в папке на ПК.
- AJAX Timeout (secs) — лимиты таймаута. Как долго SEO Spider должен разрешать выполнение JavaScript, прежде чем проверять загруженную страницу.
- Window Size — выбор размера окна (много их — смотрим скриншот).
- Sample — пример окна (зависит от выбранного Window Size).
- Чекбокс Rotate — повернуть окно в Sample.
Вкладка Advanced — дополнительные опции парсинга

- Allow Cookies — учитывать Cookies, как это делает поисковый бот.
- Pause on High Memory Used — тормозит сканирование сайта, если процесс забирает слишком много оперативной памяти.
- Always Follows Redirect — разрешаем краулеру идти по редиректам вплоть до финальной страницы с кодом 200, 4хх, 5хх (по факту все ответы сервера, кроме 3хх).
- Always Follows Canonicals — разрешаем краулеру учитывать все атрибуты “canonical” вплоть до финальной страницы. Полезно, если на страницах сайта бардак с настройкой этого атрибута (например, после нескольких переездов).
- Respect Noindex — страницы с “noindex” не отображаются в отчете SF.
- Respect Canonical — учет атрибута “canonical” при формировании итогового отчета. Полезно, если у сайта много динамических страниц с настроенным rel=”canonical” — позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Respect Next/Prev — учет атрибутов rel=”next”/”prev” при формировании итогового отчета. Полезно, если у сайта есть страницы пагинации с настроенными “next”/”prev”- позволяет убрать из отчета дубли по метаданным (т.к. на страницах настроен нужный атрибут).
- Extract Images from img srscet Attribute — изображения извлекаются из атрибута srscet тега <img>. SRSCET — атрибут, который позволяет вам указывать разные типы изображений для разных размеров экрана/ориентации/типов отображения.
- Respect HSTS Policy — если чекбокс активен, SF будет выполнять все будущие запросы через HTTPS, даже если перейдет по ссылке на URL-адрес HTTP (в этом случае код ответа будет 307). Если же чекбокс неактивен, краулер покажет «истинный» код состояния за перенаправлением (например, постоянный редирект 301).
- Respect Self Referencing Meta Refresh — учитывать принудительную переадресацию на себя же (!) по метатегу Refresh.
- Response Timeout — время ожидания ответа страницы, перед тем как парсер перейдет к анализу следующего урла. Можно сделать больше (для медленных сайтов), можно меньше.
- 5хх Response Retries — количество попыток “достучаться” до страниц с 5хх ответом сервера.
- Store HTML — можно сохранить статический HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть его до того, как JavaScript “вступит в игру”.
- Store Rendered HTML — позволяет сохранить отображенный HTML-код каждого URL-адреса, просканированного SEO Spider, на диск и просмотреть DOM после обработки JavaScript.
- Extract JSON-LD — извлекаем микроразметку сайта JSON-LD. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract Microdata — извлекаем микроразметку сайта Microdata. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
- Extract RDFa — извлекаем микроразметку сайта RDFa. При выборе — дополнительные чекбоксы с типами валидации микроразметки (Schema.org, Google Validation, Case-Sensitive).
Вкладка Preferences — так называемые “предпочтения”
Здесь задаем желаемые параметры для некоторых сканируемых элементов (title, description, url, H1, H2, alt картинок, размер картинок). Соответственно, если сканируемые элементы сайта не будут соответствовать нашим предпочтениям, программа нам об этом сообщит в научно-популярной форме. Совершенно необязательные настройки — каждый прописывает для себя свой идеал… или вообще их не трогает, от греха подальше (как делаю я).

- Page Title Width — оптимальная ширина заголовка страницы. Указываем желаемые размеры от и до в пикселях и в символах.
- Meta Description Width — оптимальная ширина описания страницы. Аналогично, как и с тайтлом, указываем желаемые размеры.
- Other — сюда входит максимальная желаемая длина урл-адреса в символах (Max URL Length Chars), максимальная длина H1 в символах (Max H1 Length Chars), максимальная длина H2 в символах (Max H2 Length Chars), максимальная длина ALT картинок в символах (Max Image Length Chars) и максимальный вес картинок в КБ (Max Image Size Kilobytes).
Robots.txt — определяем каким правилам следовать при парсинге

Вкладка Settings — настраиваем парсинг относительно правил robots.txt

- Respect robots.txt — следуем всем правилам, прописанным в robots.txt. Т.е. учитываем в анализе те папки и файлы, которые открыты для робота.
- Ignore robots.txt — не учитываем robots.txt сайта при парсинге. В отчет попадают все папки и файлы, относящиеся к домену.
- Ignore robots.txt but report status — не учитываем robots.txt сайта при парсинге, однако в дополнительном меню выводится статус страницы (индексируемая или не индексируемая).
- Show internal/external URLs blocked by robots.txt — отмечаем в чекбоксах хотим ли мы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации в robots.txt. Данная опция работает только при условии выбора “Respect robots.txt”.

Вкладка Custom — ручное редактирование robots.txt в пределах текущего парсинга
Удобно, если вам нужно при парсинге сайта учитывать (или исключить) только определенные папки, либо же добавить правила для поддоменов. Кроме того, можно быстро сформировать и проверить свой рабочий robots, чтобы потом залить его на сайт.

Шаг 1. Прописать анализируемый домен в основной строке

Шаг 2. Кликнуть на Add, чтобы добавить robots.txt домена
Тут на самом деле все очень просто, поэтому я по верхам пробегусь по основным опциям (а в конце будет видео, где я бездумно прокликиваю все кнопки).

- Блок Subdomains — сюда, собственно, можно добавлять домены/поддомены, robots.txt которых мы хотим учитывать при парсинге сайта.
- Окно справа — для редактирования выгруженного robots.txt. Итоговый вариант будет считаться каноничным для парсера.
- Окошко снизу — проверка индексации url в зависимости от настроенного robots.txt. Справа выводится статус страницы (Allowed или Disallowed).
URL Rewriting — функция перезаписи URL «на лету»

Тут мы можем настроить перезапись урл-адресов домена прямо в ходе парсинга. Полезно, когда нужно заменить определенные регулярные выражения, которые засоряют итоговый отчет по парсингу.
Вкладка Remove Parameters
Вручную вводим параметры, которые нужно удалять из url при анализе сайта, либо исключить вообще все возможные параметры (чекбокс “Remove all”). Полезно, если у страниц сайта есть идентификаторы сеансов, отслеживание контекста (utm_source, utm_medium, utm_campaign) или другие фишки.

Вкладка Regex Replace
Изменяет все сканируемые урлы с использованием регулярных выражений. Применений данной настройки масса, я приведу только несколько самых распространенных примеров:

- Изменение всех ссылок с http на https (Регулярное выражение: http Заменить: https).
- Изменение всех ссылок на site.by на site.ru (Регулярное выражение: .by Заменить: .ru).
- Удаление всех параметров (Регулярное выражение: \?. * Заменить: ).
- Добавление параметров в URL (Регулярное выражение: $ Заменить: ?ПАРАМЕТР).
Вкладка Options
Вы рассчитывали увидеть здесь еще 100500 дополнительных опций для суперточной настройки URL Rewriting, я прав? Как бы странно это ни звучало, но здесь мы всего лишь определяем перезаписывать все прописные url-адреса в строчные или нет… вот как-то так, не спрашивайте, я сам не знаю почему для этой опции сделали целую отдельную вкладку.

Вкладка Test
Тут мы можем предварительно протестировать видоизменение url перед началом парсинга и, соответственно, подправить регулярные выражения, чтобы на выходе не получилось какой-нибудь ерунды.

CDNs — парсим поддомены, не отходя от кассы
Использование настройки CDNs позволяет включать в парсинг дополнительные домены/поддомены/папки, которые будут обходиться пауком и при этом считаться внутренними ссылками. Полезно, если нужно проанализировать массив сайтов, принадлежащих одному владельцу (например, крупный интернет-магазин с сетью сайтов под регионы). Также можно прописывать регулярные выражения на конкретные пути сканирования — т.е. парсить только определенные папки.

Во вкладке Test можно посмотреть как будут определяться урлы в зависимости от используемых параметров (Internal или External).
Include/Exclude — сканирование/удаление определенных папок

Можно регулярными выражениями задать пути, которые будут сканироваться внутри домена. Также можно запретить парсинг определенных папок. Единственный нюанс в настройках — при использовании Include будут парситься только УКАЗАННЫЕ папки, если же мы добавляем урлы в Exclude, сканироваться будут все папки, КРОМЕ УКАЗАННЫХ.

Выбираем папки для парсинга

Удаляем папки из парсинга
Примеры регулярных выражений для Exclude:
- http://site.by/obidnye-shutki-pro-seo.html (исключение конкретной страницы).
- http://site.by/obidnye-shutki-pro-seo/.* (исключение целой папки).
- http://site.by/.*/obidnye-shutki-pro-seo/.* (исключение всех страниц, после указанной).
- .*\?price.* (исключение страниц с определенным параметром).
- .*jpg$ (исключение файлов с определенным расширением).
- .*seo.* (исключение страниц с вхождением в url указанного слова).
- .*https.* (исключение страниц с https).
- http://site.by/.* (исключение всех страниц домена/поддомена).
Speed — регулируем скорость парсинга сайта

Можно выставить как количество потоков (по умолчанию 5), так и число одновременно сканируемых адресов. Влияет на скорость парсинга и вероятность бана бота, так что тут лучше не усердствовать.

User-Agent — выбираем под кого маскируемся

В списке user-agent можно выбрать от лица какого бота будет происходить парсинг сайта. Удобно, если в настройках сайта есть директивы, блокирующие того или иного бота (например, запрещен google-bot). Также полезно иногда прокраулить сайт гугл-ботом для смартфона, чтобы проверить косяки адаптива или мобильной версии.


Скажу сразу — это опция очень индивидуальна, лично я ее не пользую, потому что чаще всего незачем. В любом случае, настройка реагирования на http-заголовки позволяет определить, как паук будет их обрабатывать (если указаны нюансы в настройках). По крайней мере я так это понял.

Т.е. можно индивидуально настроить, например, какого формата контент обрабатывать, учитывать ли cookie и т.д. Нюансов там довольно много.

Custom — дополнительные настройки поиска по исходному коду

Custom Search
По сути обычный фильтр, с помощью которого можно вытягивать дополнительные данные, например, страницы, в которых вместо тега <strong> используется <bold> или еще лучше — страницы, которые НЕ содержат определенного контента (например, без кода счетчика метрики). Фактически в настройках можно задать все что угодно.

Custom Extraction
Это пользовательское извлечение любых данных из html (например, текстовое содержимое).

User Interface — обнуление настроек для колонок таблицы
Просто сбрасывает сортировку столбцов, ничего особенного, проходим дальше, граждане, не толпимся.

API Access — интеграция с разными сервисами
Для того чтобы получать больше данных по сайту, можно настроить интеграцию с разными сервисами статистики типа Google Analytics или Majestic, при условии того, что у вас есть аккаунт в этом сервисе.

При этом для каждого сервиса отдельные настройки выгрузки по типам данных.

На примере GA
Authentification — настройки аутентификации (если есть запрос от сайта)

Есть два вида аутентификации — Standart Based и Form Based. По умолчанию используется Standart Base — если при парсинге от сайта приходит запрос на аутентификацию, в программе появляется соответствующее окно.

Form Based — использование для аутентификации встроенного в SF браузера (полезно, когда для подтверждения аутентификации нужно, например, пройти капчу). В данном случае необходимо вручную вводить урл сайта и в открывшемся окне браузера вводить логин/пароль, кликать recaptcha и т.д.

System — внутренние настройки самой программы
Настройки работы самой программы — сколько оперативной памяти выделять на процесс, куда сохранять экспорт и т.д.

Давайте как обычно — подробнее о каждом пункте.
- Memory — выделяем лимиты оперативной памяти для парсинга. По дефолту стоит 2GB, но можно выделить больше (если ПК позволяет).

- Storage — выбор базы для хранения данных. Либо сохранение в ОЗУ (для этого у SF есть свой движок), либо в указанной папке на ПК пользователя.

- Proxy — подключение прокси-сервера для парсинга.

- Embedded Browser — использование встроенного в программу браузера (вкл/выкл).

Mode
- Spider (Режим паука) — классический парсинг сайта по внутренним ссылкам. Просто вводим нужный домен в адресную строку программы и запускаем работу.
- List — парсим только предварительно собранный список урл-адресов! Адреса можно выгрузить из файла (From a file), вбить вручную (Enter Manually), подтянуть их из карты сайта (Download Sitemap) и т.д. Если честно, этих трех способов получения списка урлов должно быть более чем достаточно.
- SERP Mode — в этом режиме нет сканирования, зато здесь можно загружать мета-данные сайта, редактировать их и предварительно понимать как они будут отображаться в браузере. Делать все это можно пакетно, что вполне себе удобно.
Bulk export
В этом пункте меню висят все опции SF, отвечающие за массовый экспорт данных из основного и дополнительного меню отчета…сейчас покажу на скриншоте.

В общем и целом с помощью bulk export можно вытянуть много разной полезной информации для последующей постановки ТЗ на доработки. Например, выгрузить в excel страницы, на которых найдены ссылки с 3хх ответом сервера + сами 3хх-ссылки, что позволяет сформировать задание для программиста или контент-менеджера (зависит от того, где зашиты 3хх-ссылки) на замену этих 3хх-ссылок на прямые с кодом 200. Теперь подробнее про то, что можно экспортировать при помощи Bulk Export.

- All Inlinks — получаем все входящие ссылки на каждый URI, с которым столкнулся краулер при сканировании сайта.
- All Outlinks — получаем все исходящие ссылки с каждого URI, с которым столкнулся краулер при сканировании сайта.
- All Anchor Text — выгрузка анкоров всех ссылок.
- All Images — выгрузка всех картинок (урл-адресами, естественно).
- Screenshots — экспорт снимков экрана.
- All Page Source — получаем статический HTML-код или обработанный HTML-код просканированных страниц (рендеринг HTML доступен только в режиме рендеринга JavaScript) .
- External Links — все внешние ссылки со всех просканированных страниц.
- Response Codes — все страницы в зависимости от выбранного кода ответа сервера (закрытые от индекса, с кодом 200, с кодом 3хх и т.д.).
- Directives — все страницы с директивами в зависимости от выбранной (Index Inlinks, Noindex Inlinks, Nofollow Inlinks и т.д.).
- Canonicals — страницы, содержащие канонические атрибуты, страницы без указания этих атрибутов, каноникализированные (*перекрестился*) страницы и т.д.
- AMP — страницы с AMP, ссылки с AMP (но код ответа не 200) и т.д.
- Structured Data — выгрузка страниц с микроразметкой.
- Images — выгрузка картинок без альт-текста, тяжелых картинок (в соответствии с указанным в настройках размером).
- Sitemaps — выгрузка всех страниц в карте сайта, неиндексируемых страниц в карте сайта и проч.
- Custom — выгрузка пользовательских фильтров.
Reports
Здесь содержится множество различных отчетов, которые также можно выгрузить.

- Crawl Overview — в этом отчете содержится сводная информация о сканировании, включая такие данные, как количество найденных URL-адресов, заблокированных robots.txt, число сканированных, тип контента, коды ответов и т. д.
- Redirect & Canonical Chains — отчет о перенаправлении и канонических цепочках. Здесь отображаются цепочки перенаправлений и канонических символов, показывается количество переходов по пути и идентифицируется источник, а также цикличность (если есть).
- Non-Indexable Canonicals — здесь можно получить выгрузку, в которой освещаются ошибки и проблемы с canonical. В частности, этот отчет покажет любые канонические файлы, которые не отдают корректного ответа сервера — заблокированы файлом robots.txt, с перенаправлением 3хх, ошибкой 4хх или 5хх (вообще все что угодно, кроме ответа «ОК» 200).
- Pagination — ошибки и проблемы с атрибутами rel=”next” и rel=”prev”, которые используются для обозначения содержимого, разбитого на пагинацию.
- Hreflang — проблемы с атрибутами hreflang (некорректный ответ сервера, страницы, на которые нет гиперссылок, разные коды языка на одной странице и т.д.).
- Insecure Content — показаны любые защищенные (HTTPS) URL-адреса, на которых есть небезопасные элементы, такие как внутренние ссылки HTTP, изображения, JS, CSS, SWF или внешние изображения в CDN, профили социальных сетей и т. д.
- SERP Summary — этот отчет позволяет быстро экспортировать URL-адреса, заголовки страниц и мета-описания с соответствующими длинами символов и шириной в пикселях.
- Orphan Pages — список потерянных страниц, собранных из Google Analytics API, Google Search Console (Search Analytics API) и XML Sitemap, которые не были сопоставлены с URL-адресами, обнаруженными во время парсинга.
- Structured Data — отчет содержит данные об ошибках валидации микроразметки страниц.
Sitemaps
С помощью этого пункта можно сгенерировать XML-карту сайта (страницы и картинки).

Все просто — выбираем что будем генерировать. В появившемся окне при необходимости выбираем нужные параметры и создаем карту сайта, которую потом заливаем в корневой каталог сайта.
Рассмотрим подробнее параметры, которые нам предлагают выбрать при генерации карты сайта.

Вкладка Pages — выбираем какие типы страниц включить в карту сайта.
- Noindex Pages — страницы, закрытые от индексации.
- Canonicalised — каноникализированные (опять это страшное слово!) страницы . Другими словами, динамика, у которой есть rel=”canonical”.
- Paginated URLs — страница пагинации.
- PDFs — PDF-документы.
- No response — страницы с кодом ответа сервера 0 (не отвечает).
- Blocked by robots.txt — страницы закрытые от индекса в robots.txt.
- 2xx — страницы с кодом 2хх (они будут в карте в любом случае).
- 3хх — страницы с кодом ответа 3хх (редиректы).
- 4хх — страницы с кодом ответа 4хх (битые ссылки на несуществующие страницы).
- 5хх — страницы с кодом ответа 5хх (проблема сервера при загрузке).
Вкладка Last Modified — выставляем дату последнего обновления карты.

- nclude <lastmod> tag — использовать в sitemap тег <lastmod> (дата последнего обновления карты).
- Use server report — использовать ответ сервера при создании карты, либо проставить дату вручную.
Вкладка Priority — выставляем приоритет ссылки в зависимости от глубины залегания страницы.

- Include <priority> tag — добавляет в карту сайта тег <priority>, показывающий приоритет страницы.
- Crawl Depth 0-5+ — в зависимости от глубины залегания страницы, можно проставить ее приоритет сканирования для поискового робота.
Вкладка Change Frequency — выставляем вероятную частоту обновления страниц.

- Include <changefreq> tag — использовать тег <changefreq> в карте сайта. Показывает частоту обновления страницы.
- Calculate from Last Modified header — рассчитать тег по последнему измененному заголовку.
- Use crawl depth settings — проставить тег в зависимости от глубины страницы.
Вкладка Images — добавляем картинки в карту сайта.

- Include Images — выводить в общей карте сайта картинки.
- Include Noindex Images — добавить картинки, закрытые от индекса.
- Include only relevant Images with up to … inlinks — добавить только картинки с заданным числом входящих ссылок.
- Regex list of CDNs hosting images to be included — честно, так и не понял что это такое… возможно настройка выгрузки в карту сайта картинок из хостинга (т.е. можно вбить списком несколько хостов и оттуда подтянуть картинки), но это всего лишь мои предположения.
Вкладка Hreflang — использовать в sitemap атрибут <hreflang> (или не использовать).

Visualisations
Это выбор интерактивной визуализации структуры сайта в программе. Можно получить отображение дерева сканирования и дерева каталогов. Основная фишка в том, что открываются эти карты и диаграммы во встроенном браузере программы, что позволяет эффективнее с ними работать (настраивать выведение, масштабировать, перескакивать к нужным урлам через поиск и т.д.).

Crawl Tree Graph — визуализация сканирования. По факту после завершения краулинга показывает текущую структуру сайта на основании анализа.

Directory Tree Graph — показывает ВСЕ каталоги после сканирования. Т.е. отличие от Crawl Tree Graph в том, что в этом отчете показываются, например, папки, закрытые от индекса.

Назначение Crawl Tree Graph и Directory Tree Graph в основном заключается в упрощении анализа структуры текущего сайта, можно глазами пробежаться по всем папкам, зацепиться за косяки (т.к. они выделены цветом). При наведении на папку, показывается ее данные (url, title, h1, h2 и т.д.).

Force Directed Crawl-Diagram — по сути то же самое, что и Crawl Tree Graph, только оформленное по-другому + показывает сканирование сайта относительно главной страницы (ну или стартовой). Кому-то покажется нагляднее, хотя по мне, выглядит гораздо сложнее для восприятия.

Force Directed Tree-Diagram — аналогично, другой тип визуализации дерева каталогов сайта.

Inlink Anchor Text Word Cloud — визуализация анкоров (ссылочного текста) внутренней ссылки. Анализирует каждую страницу по-отдельности. Помогает понять какими анкорами обозначена страница, как их много, насколько разнообразны и т.д.

Р- Разнообразие
Body Text Word Cloud — визуализация плотности отдельных слов на странице. По сути выглядит так же, как и Inlink Anchor Text Word Cloud, так что отдельный скрин делать смысла особого нет — обычное облако слов, по размеру можно определить какое слово встречается чаще, по общему числу посмотреть разнообразие слов на странице и т.д.
Каждая визуализация имеет массу настроек вывода данных, маркировки — про них я писать не буду, если станет интересно, сами поиграетесь, ок? Там ничего сложного.

Crawl Analysis

Большинство параметров сайта вычисляется пауком в ходе сбора статистики, однако некоторые данные (Link Score, некоторые фильтры и прочее) нуждаются в дополнительном анализе, чтобы попасть в финальный отчет. Данные, которые нуждаются в Crawl Analysis, помечены соответствующим образом в правом меню навигации.

Crawl Analysis запускается после основного парсинга. Перед запуском дополнительного анализа, можно настроить его (какие данные выводить в отчет).

- Link Score — присвоение оценок всем внутренним ссылкам сайта.
- Pagination — показывает петлевые пагинации, а также страницы, которые обнаружены только через атрибуты rel=”next”/”prev”.
- Hreflang — урлы hreflang без гиперссылки, битые ссылки.
- AMP — страницы без тегов “html amp”, теги не с 200 кодом ответа.
- Sitemaps — неиндексируемые страницы в карте сайта, урлы в нескольких картах сайта, потерянные страницы (например, есть в Google Analytics, есть в sitemap, не обнаружено при парсинге), страницы, которых нет в карте сайта, страницы в карте сайта.
- Analytics — потерянные страницы (есть в аналитике, нет в парсинге).
- Search Console — потерянные страницы (есть в вебмастере, нет в парсинге).
License
Исходя из названия, логично предположить, что этот пункт меню отвечает за разного рода манипуляции с активацией продукта…иии так оно и есть!

Buy a License — купить лицензию. При клике переход на соответствующую страницу официалов https://www.screamingfrog.co.uk/seo-spider/licence/. Стоимость ключа для одного ПК — 149 фунтов стерлинга. Есть пакеты для нескольких ПК, там, как обычно, идут скидки за опт.

Enter License — ввести логин и ключ лицензии, чтобы активировать полный функционал парсера.

Заметили, да? Лицензия покупается на год, не бессрочная
Help
Помощь юзеру — гайды, FAQ, связь с техподдержкой, в общем все, что связано с работой программы, ее багами и их решением.

- User Guide — мануал по работе с программой. Собственно, его я использовал, как один из источников, для написания этой статьи. При желании, можете ознакомиться, если я что-то непонятно рассказал или не донес. Еще раз оставлю ссылку https://www.screamingfrog.co.uk/seo-spider/user-guide/.
- FAQ — часто задаваемые вопросы по работе с SF и ответы на них https://www.screamingfrog.co.uk/seo-spider/faq/.
- Support — обратная связь с техподдержкой https://www.screamingfrog.co.uk/seo-spider/support/. Если программа ведет себя некрасиво (например, не принимает ключ лицензии), можно пожаловаться куда надо и все починят.
- Feedback — обратная связь. Та же самая страница, что и в Support. Т.е. можно не только жаловаться, но и вносить предложения по работе программы, предлагать партнерку, сказать банальное “спасибо” за такой крутой сервис (думаю ребятам будет приятно).
- Check for Updates и Auto Check for Updates — проверка на наличие обновлений программы. Screaming Frog нерегулярно, но довольно часто дорабатывается, поэтому есть смысл периодически проверять апдейты. Но лучше поставить галочку на Auto Check for Updates и программа сама будет автоматически предлагать обновиться при выходе нового апа.
- Debug — отчет о текущем состоянии программы. Нужно, если вы словили какой-то баг и хотите о нем сообщить разработчику. Там еще дополнительно есть настройки дебага, но я думаю, нет смысла заострять на этом внимание.
- About — собственно, краткая информация о самой программе (копирайт, сервисы, которые использовались при разработке).
Итог
Screaming Frog — очень гибкая в плане настройке утилита, с помощью которой можно вытянуть массу данных для анализа, нужно только (только… ха-ха) правильно настроить парсинг. Я надеюсь, мой мануал поможет вам в этом, хотя и не все я рассмотрел как надо, есть пробелы, но основные функции должны быть понятны.
Теперь от себя — текста много, скринов много, потому, если вы начинающий SEO-специалист, рекомендую осваивать SF поэтапно, не хватайтесь за все сразу, ибо есть шанс упустить важные нюансы.
Ну вот и все, ребята, я отчаливаю за новым материалом для нашего крутого блога. Подписывайтесь, чтобы не пропустить интересные публикации от меня и моих коллег. Всем удачи, всем пока!

Владимир Еленский
Практикующий SEO-специалист MAXI.BY media. Опыт работы более 5-ти лет. Хороший человек и просто красавчик.
Инструкция по настройке Лягушки (Screaming Frog) для сканирования сайтов. Активируем и настраиваем программу для работы в ручном и из пред файла готовой конфигурации в пару кликов.
Делюсь одной из частей регламента для сотрудников, которая посвященна работе с программой Screamig Frog.
Всем привет. Меня зовут Толстенко Александр. Я частный специалист по продвижению сайтов в Яндекс/Google.
Работаю в сфере создания и продвижения сайтов с 2009 года (уже более 13 лет).
Кейсы продвижения и другие статьи, подтверждающие экспертизу, можно посмотреть на сайте marketing-digital.ru или в профиле на vc.ru.
Провожу в месяц 10 бесплатных консультации длительностью 10-15 минут. Если актуально, бронируйте место, контакты в конце.
Настраиваем параметры программы Screaming Frog SEO Spider
Запускам программу и сразу вводим ключь активации
Важно! Программа должна быть активированная, чтобы просканировать весь сайт, а не только первые 500 страниц.
Далее, переходим к одному из методов настройке самой программы.
1. Загрузка настроек из готового файла конфигурации
Чтобы не разбираться в деталях настройки программы, загружаем скачанную конфигурацию на ПК и импортимуем настройки, которые подойдут в 90% случаев для сканирования практически всех сайтов.
- Готовая конфигурация для скачивания на ПК
Инструкция по импорту
1.1. Открываем меню: File → Configuration → load
1.2. Импортируем скаченный файл выше
1.3. Сохраняем загруженные настройки по умолчанию (будут применены при каждем открытии программы)
1.4. Проверяем, где будут храниться данные сканирования в ОЗУ или на жестком (System → Storage Mode) (могло снести при импорте)
1.5. Проверить сколько у вас установилось оперативной памяти для сканирования (могло снести при импорте)
Разработчики заявляют, что для хранения базы данных 4 ГБ ОЗУ позволят вам сканировать 2-3 миллиона URL-адресов, 8 ГБ ОЗУ позволят сканировать до 5 миллионов URL-адресов и 16 ГБ для 10 миллионов. Но, все это — приблизительные значения, так как зависит от типа сайта.
Рекомендуемое значение программой, будет указано в скобках (пример на скрние ниже в скобках: 14GB maximum allowed). Задать самостоятельно можно будет в окошке (у себя указал 10 GB)
Я отдаю ~60% от общего объема, чтобы не зависал компьютер. Пример на скрине. После указанных значений, нажимаем ОК.
1.3. Сохраняем загруженные настройки по умолчанию (будут применены при каждем открытии программы)
1.5. Перезагружаем программу, запускаем парсинг нужного сайта.
💡 Проверка задачи (самопроверка)
- Скачали файл конфигурации программы и импортировали его
- Проверили на всякий случай п. 1.4 и 1.5., если импорт снес, установлии свои значения
- Сохранили импортированные настройки, чтобы каждый раз не настраивать
- Перезагрузили программу, запустили парсинг нужного сайта
2) Ручная настройка (если нужно настроить под себя)
2.1. Запускам программу и открываем настройки: Configuration
2.2. Выбираем где хранить данные в ОЗУ или на жестком (System → Storage Mode)
2.3. Выбираем место, где будут храниться данные сканирования
Выбрать:
1) Database Store
2) Указать путь, где будут на жестком диске храниться данные парсинга (при желании)
3) Нажать кнопку: Ок, для сохранения изменений
2.4. Увеличиваем оперативную память для сканирования, чтобы не тупила программа
В зависимости от объема оперативной памяти на вашем компьтере (у меня 16 GB), вы можете задать значение самостоятельно.Чем больше объем, тем меньше будет тупить программа.Рекомендуемое значение программой, будет указано в скобках (пример на скрние ниже в скобках: 14GB maximum allowed).Задать самостоятельно можно будет в окошке (у себя указал 10 GB)
Я отдаю ~60% от общего объема, чтобы не зависал компьютер. Пример как у меня на скрине.После указанных значений, нажимаем ОК.
2.5. Сохраняем сделанные настройки конфигураци, чтобы открывались по умолчанию
2.6. Перезагружаем программу, она готова к работе
Важно! Если у вас очень большой проект (больше полу миллиона страниц), можно отключить ненужные параметры для сканирования. Пример настроек на скринах ниже. Поигравшись с настройками самостояльно, можно просканировать весь сайт.
💡 Проверка задачи (самопроверка)
- Программа настроена для сканирования сайтов
- Сохранили настройки, чтобы каждый раз не настраивать программу
- Перезагрузили программу, запустили парсинг нужного сайта
✌ Нужна консультация?
👉 Пишите в личные сообщения сюда:
Screaming Frog SEO spider — незаменимый помощник SEO-оптимизатора при внутреннем техническом анализе веб-сайтов.
В программе есть множество функций, о которых мы расскажем в этой статье. Также в конце приведем конкретные
примеры, как можно применять разные опции в работе.
Прочитав инструкцию, вы научитесь использовать нужные инструменты, предоставляемые сервисом, для технического
аудита сайтов. В будущем это может пригодиться при выявлении технических ошибок и составлений ТЗ на доработку
сайта.
Для начала рассмотрим по порядку все вкладки интерфейса программы.
Содержание:
- File
- Mode
- Configuration
- Spider
- Crawl
- Extraction
- Limits
- Rendering
- Advanced
- Preferences
- Content
- Robots.txt
- URL Rewriting
- CDNs
- Include/Exclude
- Speed
- User-Agent
- HTTP Header
- Custom
- User Interface
- API Access
- Authentication
- System
- Spider
- Bulk export
- Reports
- Sitemaps
- Visualizations
- Crawl Analysis
- License
- Help
- FAQ
File
Раздел, предназначенный для работы с файлами — загрузкой проектов и конфигураций, планирования будущих проверок
и т.д.
Доступные опции:
- Open — используется для загрузки и открытия файла с ранее проводившимся парсингом.
- Open Recent — похожая функция, но открывает последний проведенный парсинг. То есть, Open можно использовать
для открытия любых файлов, а Open Recent — для последнего файла. - Save — сохранение парсинга.
- Configuration — важный параметр, позволяющий загружать и/или сохранять конфигурации — специальные
предварительно заданные настройки с параметрами парсинга. Подробнее расскажем в разделе про Configuration. - Crawl Recent — используется для повторного парсинга последнего сайта, который ранее проверялся. Удобно, если
нужно быстро провести второй технический аудит. - Scheduling — применяется для планирования будущих парсингов и других задач программы.
- Exit — очевидный выход.
Mode
Устанавливает режим, в котором будет проводиться парсинг. Можно выбрать 1 из 3 опций:
- Spider — режим по-умолчанию. Парсинг будет проводиться по внутренним линкам. Для старта достаточно
ввести в адресную строку приложения нужный домен. - List — парсинг предварительно собранных URL. Сами веб-адреса можно загрузить из файла (опция From a
file), указать вручную (Enter Manually) или воспользоваться картой сайта (Download Sitemap). - SERP Mode — позволяет загрузить мета-данные с сайта и редактировать их, посмотреть, как они будут
отображаться в браузере. Сканирование при этом не проводится.
Configuration
Одна из самых обширных вкладок — в ней расположены основные настройки «паука» и опции по парсингу сайтов. Всего
в ней доступно 13 пунктов подменю. Рассмотрим каждый подробнее.
Spider
В этом подпункте расположены основные настройки парсингов сайта. Включает в себя 5 вкладок: Crawl, Limits,
Rendering, Advanced и Preferences.
Crawl
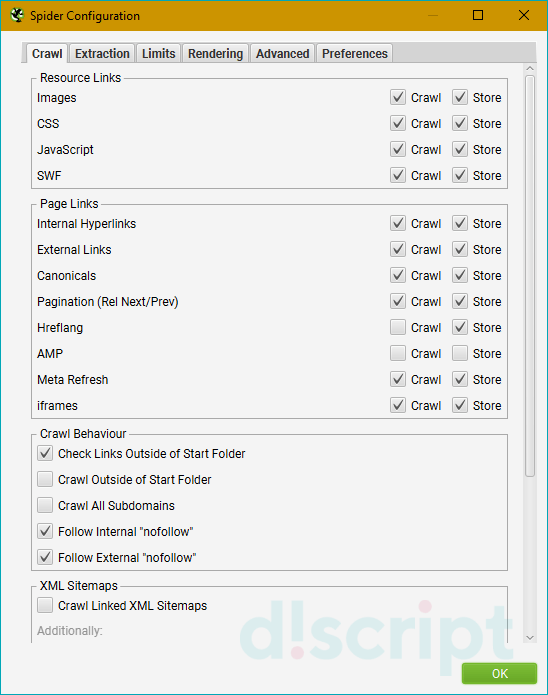
Позволяет выбрать, что именно и как вы хотите парсить. Основные опции вкладки разделены на 4 блока:
Resource Links — определяют, какие файлы и элементы будут парситься. Включают в себя 4 опции:
- Check Images — парсит картинки.
- Check CSS — парсит подключенные к сайту файлы CSS.
- Check JavaScript — парсит JS-скрипты.
- Check SWF — применяется, когда нужно включить в отчет анализ Flash-анимаций.
Page Links — определяют, какие ссылки будут парситься. В этом разделе доступны следующие опции:
- Internal Hyperlinks — добавляет в отчет внутренние ссылки.
- External Links — добавляет в отчет внешние ссылки.
- Canonicals — при сканировании веб-страниц будут анализироваться канонические (canonical) параметры.
- Pagination (Rel Next/Prev) — используется для анализа страниц с атрибутами rel = next и rel = prev.
- Hreflang — извлекает атрибут hreflang.
- AMP — извлекает с сайта и добавляет в отчет AMP-ссылки.
- Meta Refresh — сканирует и сохраняет URL-адреса, содержащиеся в мета-обновлениях
(например, такие: <meta http-equiv=»refresh» content=»5; url=https://example.com/&quot; />.). - iframes — сканирует и сохраняет адреса, содержащиеся в теге <iframe> (например, такие: <iframe
src=»htttps://example.com»>.
Crawl Behaviour — определяет поведение краулера. Доступные опции:
- Check Links Outside of Start Folder — активируйте эту опцию, если хотите получить анализ всех линков,
а не только тех, что расположены в стартовой папке. - Crawl Outside of Start Folder — стандартно программа будет сканировать только указанную пользователем
подпапку. Включение этой опции позволяет сканировать весь сайт. При этом парсинг все равно начнется с
поддомена. - Crawl All Subdomains — активируйте эту опцию, если хотите сканировать все поддомены веб-сайта.
- Follow internal «nofollow» — позволяет сканировать ссылки с тегом nofollow.
- Follow external «nofollow» — по принципу действия почти та же опция, что и предыдущая, но вместо внутренних
ссылок анализирует внешние.
XML Sitemaps — отвечает за сканирование карты сайта. Здесь доступна всего 1 опция и 2 подпункта для неё:
- Crawl Linked XML Sitemap — сканирует карту сайта. Поисковый робот может либо взять ее из файла robots.txt
(опция Auto Discover SML Sitemaps via robots.txt), либо по ручному пути, указанному пользователем — тогда
вам нужно будет выбрать опцию «Crawl These Sitemaps» и указать нужные.
Также все опции имеют 2 опции — «Crawl» и «Store». Первая отвечает за сканирование. Если отключить ее в
каком-либо элементе, он не будет анализироваться пауком. Например, сняв флажок со сканирования ссылок, вы
позволите поисковому роботу обнаруживать их и хранить, но не переходить по ним и не получать коды ответов
сервера.
Поначалу может показаться, что опций слишком много, но главное в освоении этой программы — практика и
умеренность. Выбирайте те, которые могут пригодиться вам в работе, а с остальными познакомитесь по ходу
использования приложения.
Extraction
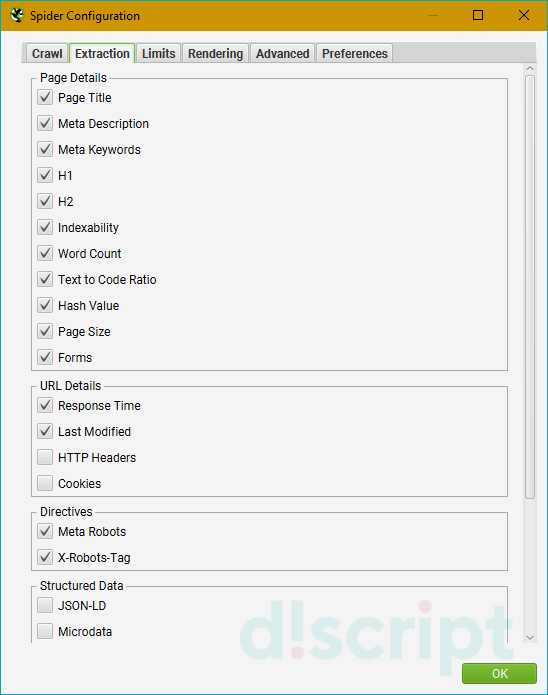
Вкладка отвечает за то, какие элементы будут извлекаться парсером и добавляться в отчет. Разделена на 5 секций:
Page Details
Отвечает за извлечение следующих элементов:
- Page Title — метатег title.
- Meta Description — метатег description.
- Meta Keywords — метатег keywords.
- H1 — заголовок 1 уровня.
- H2 — заголовок 2 уровня.
- Indexability — статус индексируемости.
- Word Count — количество слов.
- Text to Code Ratio — соотношение текста к коду.
- Hash Value — хэш-значение.
- Page Size — размер страницы.
- Forms — формы.
URL details
- Response Time — время в секундах для загрузки URL-адреса.
- Last Modified — чтение из заголовка Last-Modified в HTTP-ответе сервера. Если сервер не предоставит ответ,
поле останется пустым. - HTTP Headers — полные заголовки запросов и ответов HTTP.
- Cookies — файлы cookie, найденные во время сканирования. Будут храниться на нижней вкладке отчета «Cookies
files».
Directives
- Meta Robots — сохраняет директиву мета-роботов.
- X-Robots Tag — добавляет в отчет директиву X-Robots-Tag.
Structred Data
- JSON-LD — используется для извлечения микроразметки JSON-LD.
- Microdata — извлекает микроразметку сайта Microdata.
- RDFa — извлекает RDF микроразметку.
- Schema.org Validation —настраивает проверку микроразметки по механизму Schema Validation.
- Google Rich Result Feature Validation — включает проверку по Google Validation.
- Case-Sensitive — активирует проверку по Case-Sensitive методу.
HTML
- Store HTML — позволяет хранить статический HTML каждого URL, просканированного парсером. Полезно, если нужно
изучить его до того, как будет подключен JavaScript. - Store Rendered HTML — похожая опция, но хранится уже отображенный HTML после обработки JS.
Limits
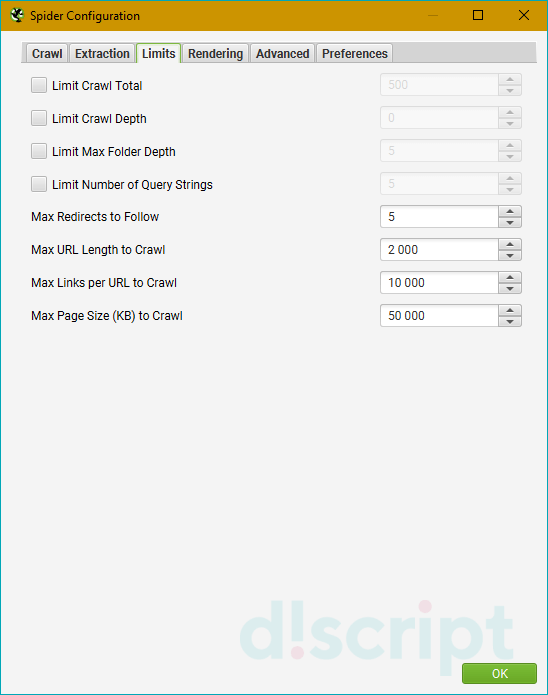
Применяется для установки лимитов парсинга. Содержит пункты:
- Limit Crawl Total — задает общий лимит веб-страниц для сканирования. С помощью этой опции можно установить
точное количество страниц, которые будут выгружены в отчет. - Limit Crawl Depth — определяет, насколько глубоко может зайти поисковый робот во время сканирования.
Например, если указать число «0», краулер просканирует только указанный документ и остановится. Если указать
«1», паук проанализирует документ, перейдет по ссылкам из него и остановится на следующей странице. Указав
«2», робот продвинется на 3 страницы (первичный документ > переход на следующую страницу по ссылкам >
переход на последующую веб-страницу по ссылкам из предыдущей). - Limit Max Folder Depth — более специфический параметр, в котором можно установить глубину до конкретной
папки. Работает по принципу, схожему с предыдущим пунктом, только указывать нужно конкретные папки. Пример:
URL site.com/folder-1/folder-2/folder-3. Где цифры — глубина проверки. - Limit Number of Query Strings — задает глубину парсинга для страниц с параметрами. Может быть полезно, если
у вас на статической странице есть пара фильтров, которые могут создать большое количество динамических
веб-страниц. Если не задать этот лимит, парсер будет сканировать все страницы, что увеличит время проверки,
при этом полезной информации вы получите по-минимуму. - Max Redirects to Follow — используется, чтобы задать максимальное количество редиректов с 1 веб-адреса.
- Max URL Length to Crawl — устанавливает максимальную длину URL в символах.
- Max Links per URL to Crawl — определяет максимальное количество ссылок в сканируемых страницах. Например,
если на странице 5 ссылок, но параметр установлен на «4», то робот проанализирует 4 ссылки и добавит их в
отчет. - Max Page Size (KB) to Crawl — максимальный размер страницы для сканирования, указывается в килобайтах.
Rendering
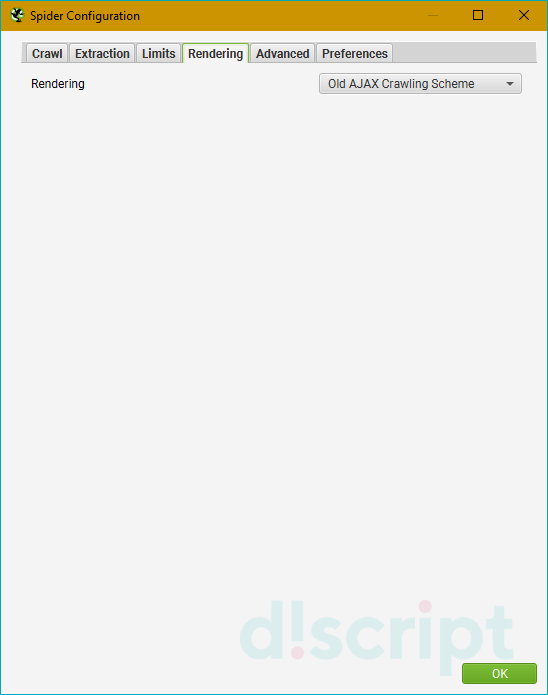
Эта вкладка понадобится вам, если вы включили сканирование JavaScript в отчет и хотите настроить параметры
рендеринга. На выбор доступно 3 режима:
- Text Only — анализ только текста страницы, без учета JS/AJAX.
- Old AJAX Crawling Scheme — использование устаревшей схемы сканирования AJAX.
- JavaScript — учитывает JS-скрипты при рендеринге.
Последний режим также имеет несколько дополнительных опций:
- Enable Rendered Page Screen Shots — позволяет включить сохранение скриншотов анализируемых страниц в папку
на вашем компьютере. - AJAX Timeout (secs) — устанавливает лимиты таймаута.
- Window Size — выбирает размер окна. На выбор их представлено много, от больших экранов (Large Desktop) до
iPhone старых и новых версий. - Sample — показывает пример окна, выбранный в пункте Window Size.
- Rotate — позволяет повернуть демонстрацию окна из Sample.
Advanced
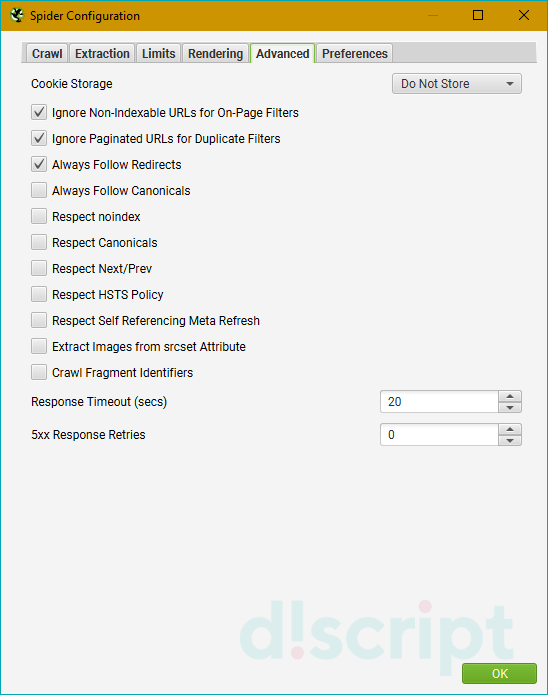
Позволяет настроить продвинутые опции парсинга. Доступные опции:
- Cookie Storage — выбирает, где будут храниться куки-файлы во время сканирования.
- Ignore Paignated URL for Duplicate Filters
- Always Follow Redirects — разрешает поисковому роботу всегда следовать по редиректам вплоть до финальной
страницы с учетом всех ответов сервера. - Always Follow Canonicals — позволяет краулеру учитывать все атрибуты canonical. Может пригодиться, если вы
несколько раз переезжали и еще не навели порядок с этим атрибутом. - Respect noindex — запрещает сканировать страницы, обернутые в тег noindex.
- Respect Canonical — исключает канонические страницы из отчета. Полезная опция, если нужно убрать дубли по
метаданным. - Respect Next/Prev — исключает страницы с rel=”next/prev” из отчета. Так же, как и предыдущий пункт,
позволяет убрать дубли по метаданным. - Respect HSTS Policy — указывает поисковому боту, что все запросы должны выполняться через протокол HTTPS.
- Respect Self Referencing Meta Refresh — позволяет учитывать принудительную переадресацию на ту же страницу
по метатегу Refresh. - Extract Images from img srcset Attribute — извлекает и добавляет в отчет изображения из атрибута srscet,
который прописывается в теге .
. - Crawl Fragment Identifiers — позволяет сканировать URL-адреса с хэш-фрагментами и считать их за уникальные
URL. - Response Timeout — устанавливает время ожидания ответа страницы перед тем, как краулер перейдет к анализу
следующего URL. Для медленных сайтов рекомендуем устанавливать большее число. - 5xx Response Retries — определяет, сколько раз парсер будет пытаться проанализировать страницы с ответом
сервера 5хх. Например, если установлен параметр «5», то поисковый робот будет посылать запросы веб-странице
5 раз, после чего остановится.
Preferences
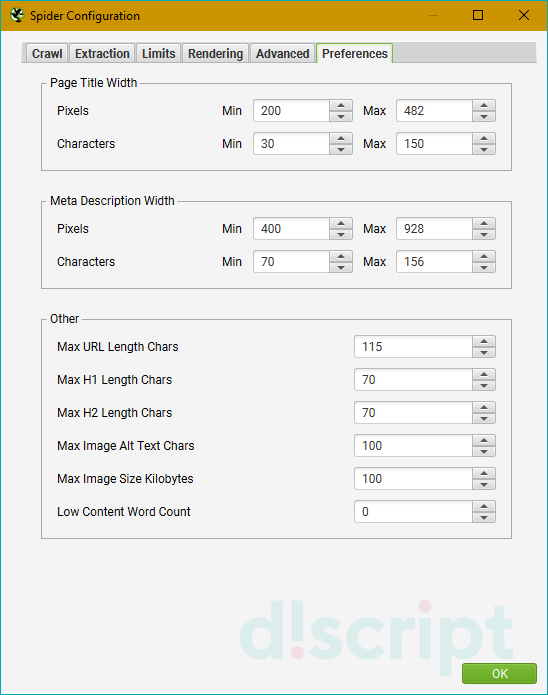
Позволяет задать предпочтения для сканируемых мета-тегов и тегов (title, description, URL, H1-H2, alt и размеры
картинок). Если размеры будут не соответствовать заданным в этой вкладке, Screaming Frog об этом сообщит.
Доступные опции:
- Page Title Width — ширина заголовка страницы. Можно указать в пикселях или символах.
- Meta Description Width — аналогично предыдущему пункту, только вместо заголовка указывается метатег title.
- Other — все остальные пункты, включая URL, заголовки 1 и 2 уровней, изображения и атрибуты alt к ним.
Не обязательная вкладка, в ней можно оставить параметры по умолчанию.
Content
Подпункт меню, отвечающий за поведение краулера при сканировании контента. Имеет 3 вкладки:
- Area — отвечает за область контента, которая будет учитываться при сканировании. Используйте эту
функцию, если хотите сфокусировать анализ на какой-либо конкретной области страницы.
- Duplications — позволяет найти точные дубликаты страниц или веб-страницы, контент на которых
совпадает в некоторых местах. Помогает в поиске дублей.
- Spelling & Grammar — проверяет правописание и грамматику. Поддерживает 39 языков, включая
русский. По-умолчанию эта функция отключена.
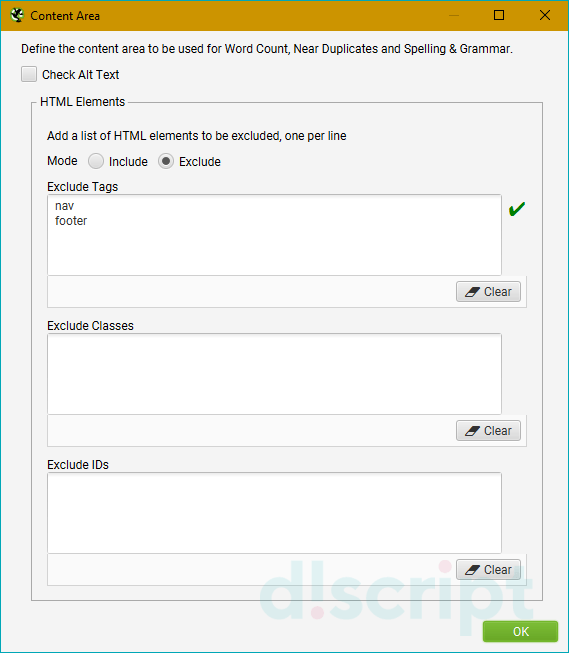
Robots.txt
Позволяет определить, каким правилам должен следовать краулер при парсинге. Имеет 2 вкладки: Settings и Custom.
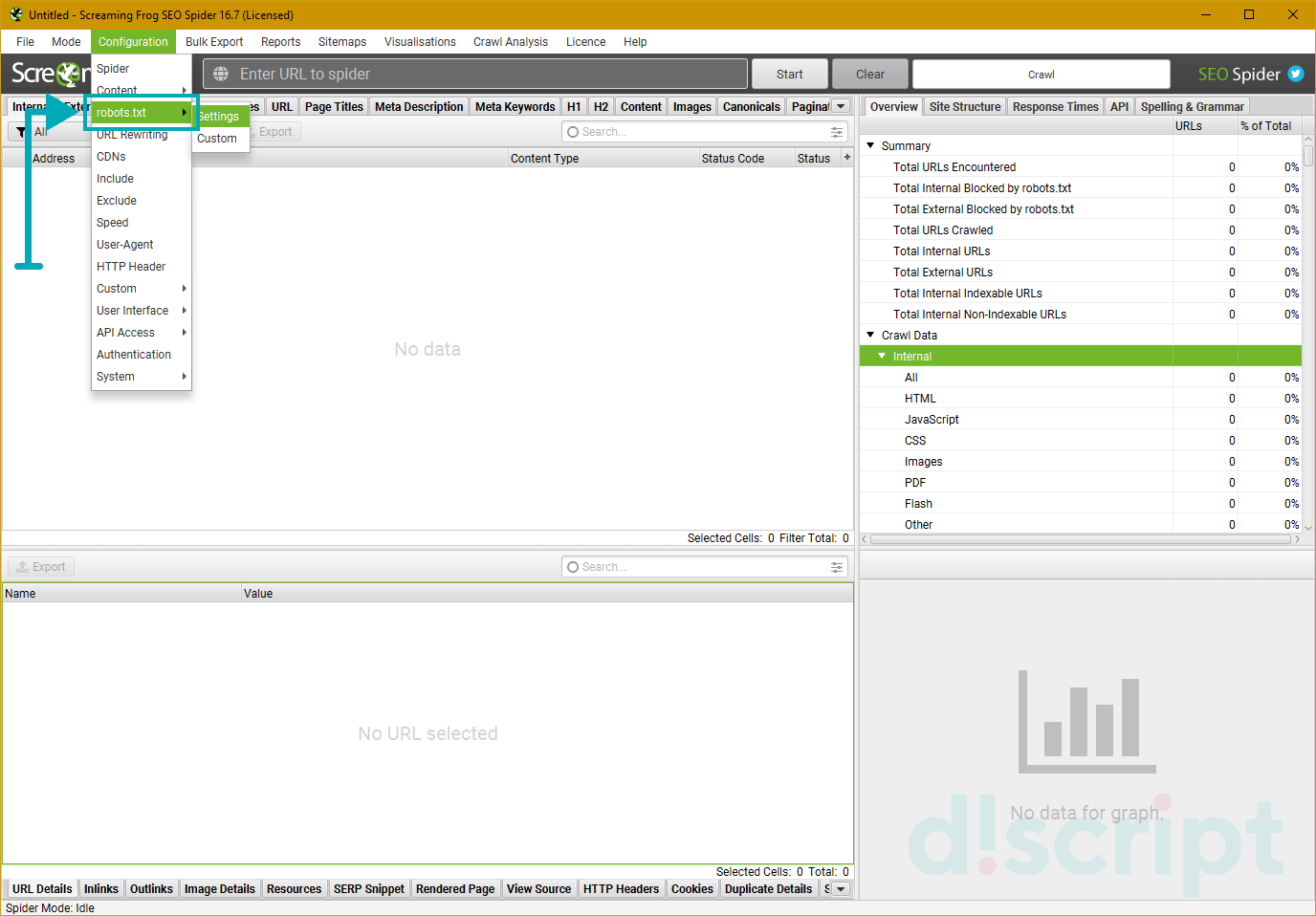
Settings — используется для настройки парсинга с учетом (или игнорированием) правил Robots.txt. На выбор
предоставляется 3 режима:
- Respect robots.txt — парсер будет полностью следовать правилам, прописанным в файле для роботов, и
учитывать только те папки и файлы, которые были открыты. - Ignore robots.txt — позволяет игнорировать правила, прописанные в robots. В таком случае, в отчет
попадут все папки и файлы сайта. - Ignore robots.txt but report status — игнорирует правила, но выводит статус страницы (индексируемая
или закрытая от индексации).
Также можно указать, хотите ли вы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации.
Эти опции будут работать, только если вы выбрали 1-й режим парсинга (respect robots.txt).
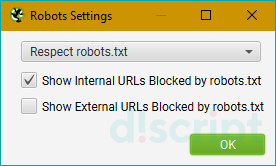
Custom — позволяет вручную отредактировать robots.txt для текущего парсинга. Удобно, если нужно добавить
или исключить только конкретные папки, или добавить дополнительные правила для поддоменов сайта. Также с помощью
этого режима можно сформировать собственный файл robots.txt, проверить его и потом при необходимости загрузить
на веб-сайт.
Чтобы добавить собственный файл, нажмите кнопку «Add» в нижнем меню. Для проверки используйте кнопку «Test»,
расположенную справа внизу.
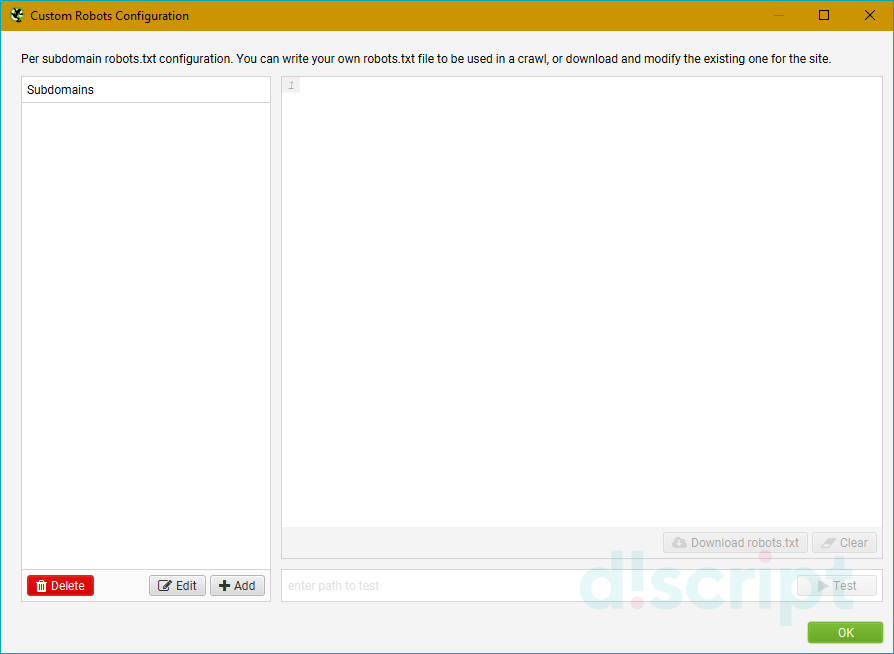
URL Rewriting
Используется для перезаписи сканируемых URL во время парсинга. Если вам надо изменить какие-либо URL во время
работы, этот раздел может пригодиться.
Имеет 4 вкладки:
- Remove Parameters — позволяет указать параметры, которые будут удаляться из URL при анализе сайта.
Также можно исключить сразу все, если поставить галочку в чекбоксе «Remove all».
- Regex Replace — позволяет изменить сканируемые URL с использованием регулярных выражений.
Применяется, например, для изменения ссылок с HTTP на HTTPS.
- Options — здесь можно активировать перезапись прописных URL в строчные.
- Test — позволяет сразу увидеть, как будет выглядеть URL при использовании опции Regex Replace.
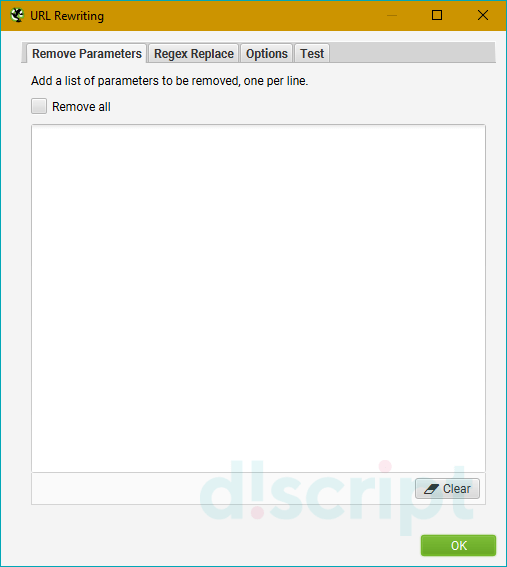
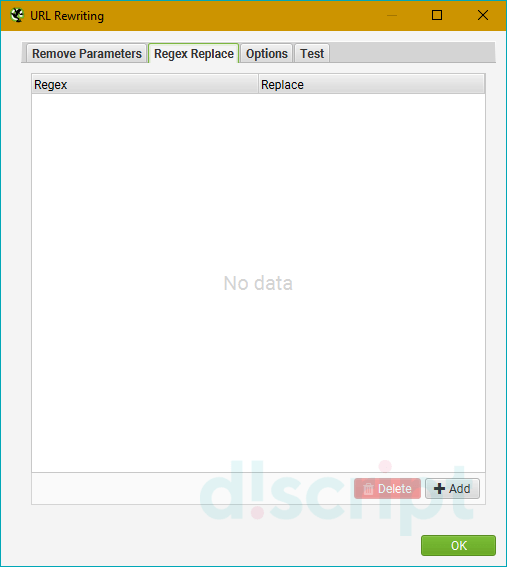
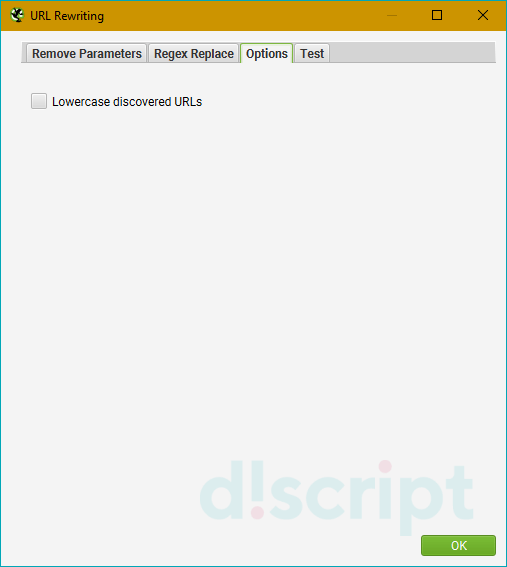
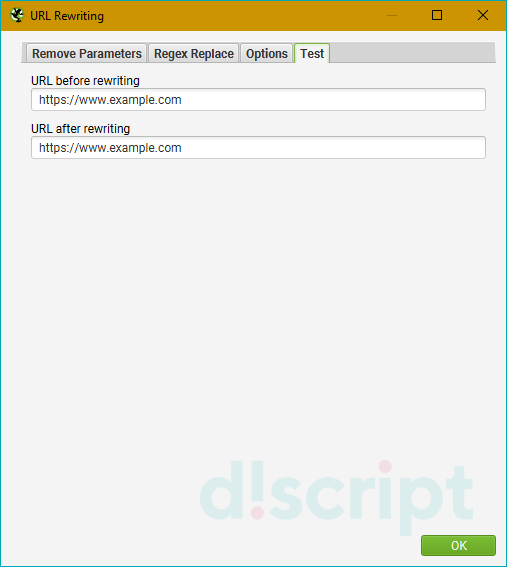
CDNs
В этой вкладке можно включать дополнительные домены и папки в процесс парсинга. Они будут считаться за
внутренние ссылки. Также можно указать только конкретные папки для сканирования. Указывать нужные папки и файлы
необходимо во вкладке «Config»:
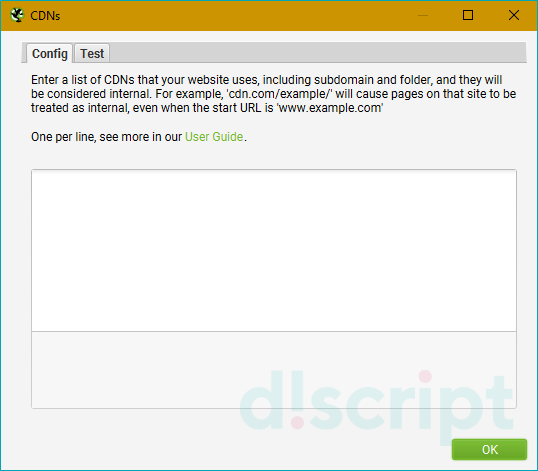
Последняя вкладка «Test» позволяет увидеть, как будут изменяться URL. Итог будет выводиться в виде параметра
Internal или External. Если, например, в результате показывает External, то ссылка будет считаться внешней:
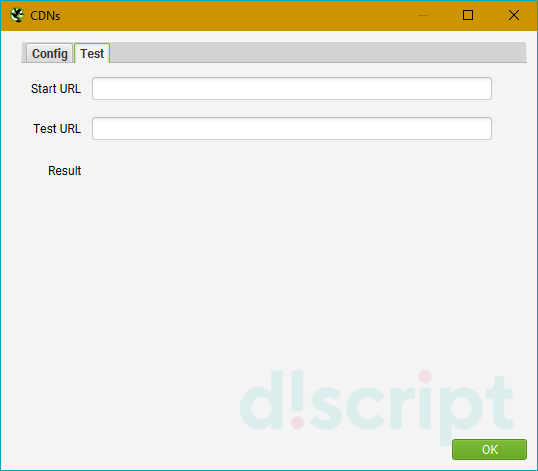
Include/Exclude
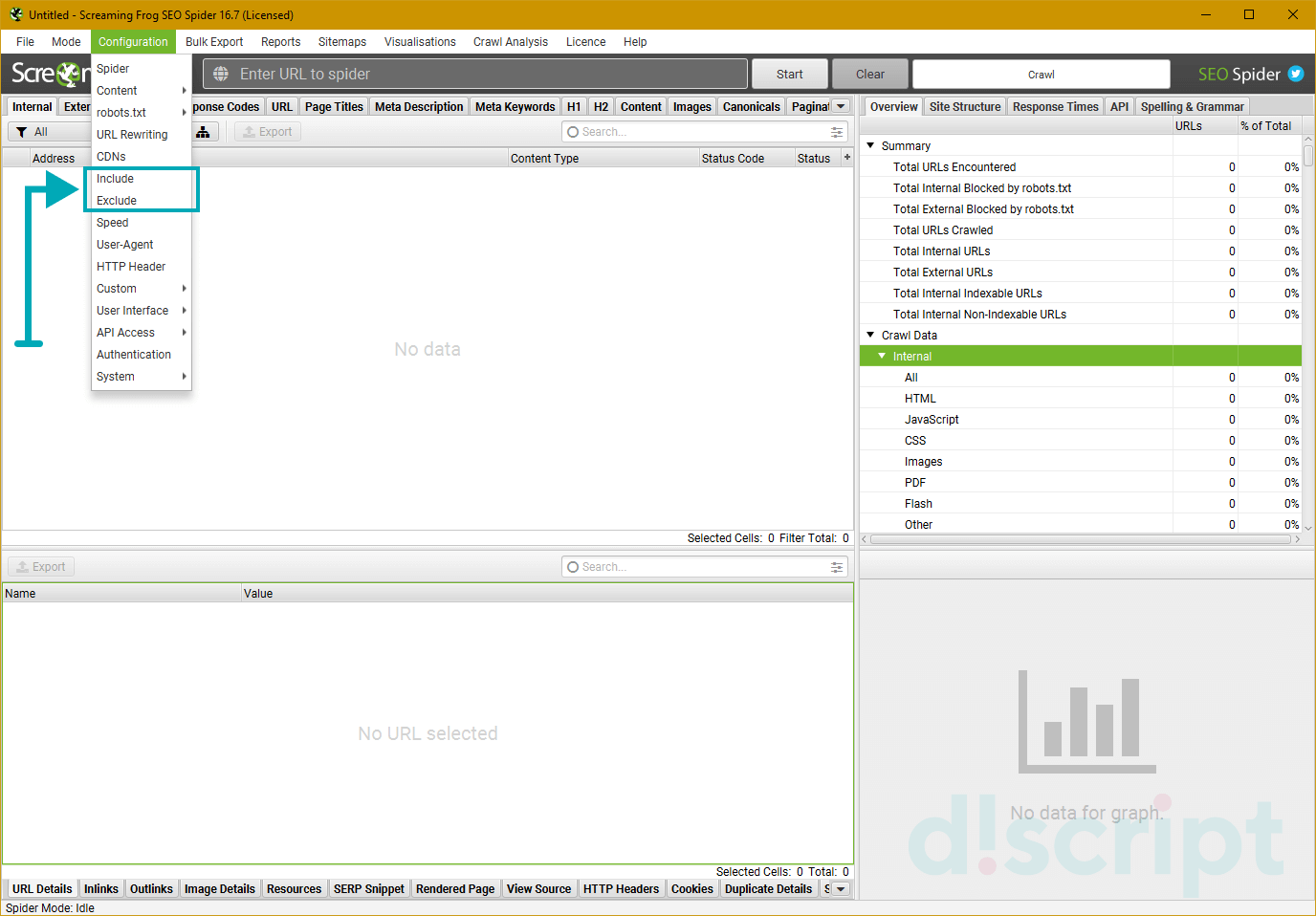
Используется для включения или исключения конкретных папок, ссылок, файлов или страниц при парсинге.
Например, во вкладке Exclude будут указаны исключения парсинга для всех папок, кроме указанных.
К примеру, вы можете запретить парсинг конкретного домена. Проверить результат можно во вкладке Test — вместо
указанного URL там будет указано, что этот веб-адрес был исключен из парсинга. Также эта опция поддерживает
регулярные выражения.
Speed
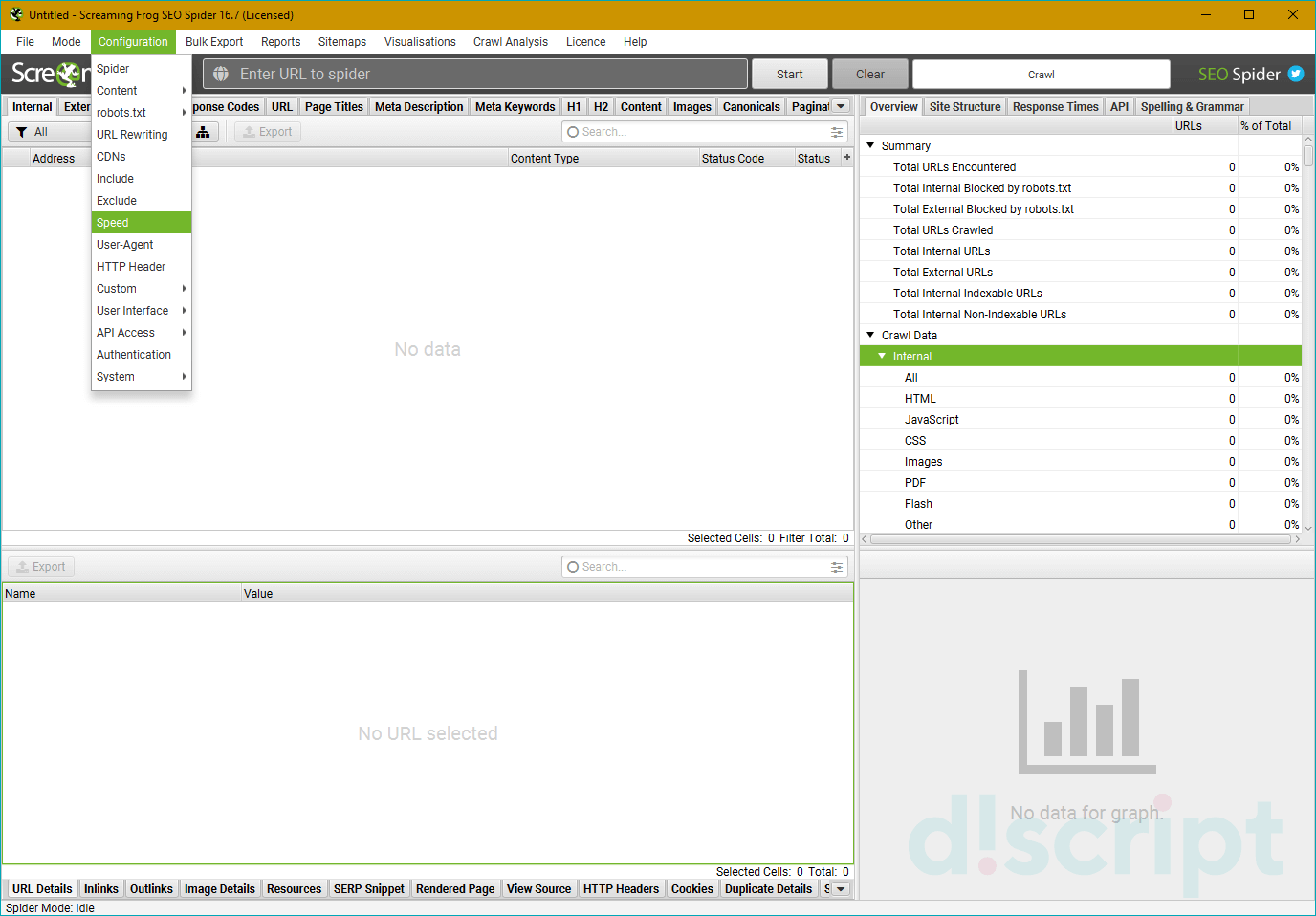
Используется для установки лимитов на количество потоков и одновременно сканируемых адресов. Меняйте параметры
аккуратно — если установить слишком низкие лимиты, поискового бота могут забанить, даже если скорость парсинга
существенно повысится.
User-Agent
В этой вкладке можно задать тип поискового бота, который будет использоваться для сканирования. Может
пригодиться, если, например, в настройках сайта запрещена индексация Yandex-ботам.
Также можно указать версии ботов для смартфонов, чтобы найти технические ошибки в мобильных версиях.
HTTP Header
Позволяет указать реакции краулера на HTTP-заголовки, если таковые будут найдены на сайте. Можно указать, будет
ли учитываться контент и cookie-файлы, как именно они будут обрабатываться и т.д.
Custom
Включает в себя 2 вкладки: Search и Extraction. В них можно указать с помощью собственного кода дополнительные
правила для парсинга. Например, если у вас на какой-то странице используется тег <i> вместо
тега <em>, вы можете указать это в Custom Search.
Во вкладке Extraction можно указывать пользовательские настройки для извлечения любой информации из HTML-кода.
User Interface
Довольно простой раздел, с помощью которого можно сбросить сортировку столбцов и вкладок программы. Также в нем
можно изменить тему со светлой на темную. На этом функции заканчиваются.
API Access
Позволяет подключить сторонние сервисы типа Google Analytics или Majestic. Вам потребуется войти в свою учетную
запись в приложении. Для каждого варианта будут свои отдельные настройки по выгрузки данных, которые будут
различаться от приложения к приложению.
Authentication
Если сайт будет запрашивать аутентификацию, вы можете указать настройки для них тут. Во вкладке есть 2 подпункта
— Standards Based и Forms Based. Стандартно используется первый вариант — если придет запрос, он отобразится в
соответствующем окне в программном обеспечении.
Если вам нужен встроенный браузер для указания данных, используйте опцию Forms Based. С ее помощью можно,
например, пройти капчу, указав логин и пароль.
System
Позволяет задать настройки самой программе. Насчитывает 5 пунктов:
- Memory — указание лимитов оперативной памяти для парсинга. Стандартно стоит 2ГБ.
- Storage — выбирает режим сохранения информации. Ее можно хранить либо в оперативной памяти, либо в
указанной пользователем папки. - Proxy — при использовании позволяет указать данные подключенного прокси-сервера для парсинга.
- Embedded Browser — включает или выключает встроенный браузер приложения.
- Language — выбор языка. Русский не поддерживается.
Bulk Export
Здесь можно настроить массовый экспорт данных из отчетов. В целом, этот раздел можно использовать, чтобы
вытягивать нужную информацию и затем составить ТЗ для доработок сайта.
Доступные подпункты меню экспорта:
- Queued URLs — все ссылки, которые были обнаружены и находятся в очереди на сканирование.
- Пункт Links
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время
парсинга. - All Outlinks — все исходящие ссылки.
- All Anchor Text — экспорт анкоров со всех ссылок
- External Links — все внешние ссылки
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время
- Пункт Web
- Screenshots — все сделанные скриншоты.
- All Page Source — статистический или визуализированный (rendered) HTML код просканированных страниц.
- All HTTP Headers
- All Cookies
- Path Type — позволяет экспортировать ссылки определенного типа со страницами, к которым они привязаны. Можно
указать абсолютные, относительные, корневые и путевые (path-relative) ссылки. - Security — страницы сайта с потенциально опасным контентом. Например, таким образом можно организовать
экспорт ссылок, ведущие на страницы сайта с небезопасными линками. - Response Codes — все страницы в зависимости от нужного кода ответа. Например, так можно выгрузить URL,
ведущие на страницы с ошибкой 404. - Content — весь контент. Может пригодиться, если нужно организовать экспорт дубликатов и составления
последующего ТЗ на их удаление. - All Images — выгрузка картинок без атрибута alt, слишком тяжелых изображений.
- Canonicals — все страницы-первоисточники.
- Directives — все директивы.
- AMP — все линки на AMP-контент.
- Structured Data — все ссылки из фильтра структурированных данных.
- Sitemaps — все страницы в карте сайта, неиндексируемые страницы в карте сайта и т.п.
- Custom Search — выгрузка всех элементов из пользовательского поиска.
- Custom Extraction — все элементы, заранее настроенные по фильтру пользовательского извлечения.
Reports
Вкладка, отвечающая за отчеты. Доступные подпункты меню:
- Crawl Overview — содержит всю сводку сканирования, включая обнаруженные URL-адреса, заблокированные файлом
robots.txt, количество просканированных ссылок, типы контента, коды ответов и т.д. - Redirects — описывает найденные перенаправления и URL-адреса, через которые удалось найти редиректы. Также
здесь отображаются канонические цепочки перенаправлений и канонические символы, указывается количество
переходов и цикличность (если она присутствует). - Canonicals — в этом разделе показываются ошибки и проблемы, найденные с каноническими цепочками или
элементами. В ответе канонических цепочек отображаются все URL, имеющие больше 2 канонических линков. - Pagination — отображает ошибки и проблемы, связанные с атрибутами rel=next/prev, которые применяются для
обозначения содержимого, разбитого на страницы. - Hreflang — сообщает о возможных проблемах с атрибутами hreflang, например: некорректных ответах серверов,
страниц без гиперссылок, разных кодах языка на 1 веб-странице и т.п. - Insecure Content — содержит HTTPS URL-адреса, на которых были обнаружены небезопасные элементы. Например,
внутренние ссылки без SSL-сертификата. - SERP summary — позволяет быстро выгрузить URL-адреса, title и description страниц. Их длина будет
указываться в символах, а ширина в пикселях. - Orphan Pages — отображает список потерянных страниц, собранных при помощи Google Analytics API и Search
Console, а также XML Sitemap, которые не были сопоставлены с URL, обнаруженными во время сканирования. - Structured Data — показывает отчет об обнаруженных ошибках валидации микроразметки веб-страниц.
- PageSpeed — содержит отчет о скорости загрузки каждой страницы. Работает, только если была подключена
интеграция PageSpeed Insights. - HTTP Headers — содержит отчет по заголовкам HTTP, обнаруженных во время сканирования. Показывает каждый
уникальный заголовок и количество URL, ответивших этим заголовком. - Cookies — содержит отчет о файлах cookie, обнаруженных во время сканирования, с указанием имени, домена,
срока действия, безопасности и значения HttpOnly.
Sitemaps
Через этот пункт меню можно создавать свои карты сайта в формате XML. На выбор предлагается 2 пункта:
- XML Sitemap — генерация XML-карты сайта
- Images Sitemap — генерация XML-карты сайта для определенного изображения.
После выбора нужного варианта откроется всплывающее окно, в котором можно будет задать нужные параметры —
например, создание карты для закрытых от индексации страниц, URL, разбитых на пагинацию и т.п.
Страница имеет 6 вкладок.
Pages — отвечает за тип страниц, которые будут включены в карту сайта.
- Noindex Pages — закрытые от индексации страницы.
- Canonicalised — каноникализированные страницы, говоря простым языком с атрибутом rel=canonical.
- Paginated URLs — страницы пагинации.
- PDFs — PDF-файлы.
- No response — не отвечающие страницы.
- Blocked by robots.txt — страницы, закрытые от индексации файлом robots.txt.
- 2xx — страницы с кодом ответа сервера 2хх (работающие страницы).
- 3xx — страницы с редиректами.
- 4xx — битые ссылки.
- 5xx — страницы с проблемами сервера при загрузке.
Last Modified — необязательная опция, позволяет выставить дату последнего обновления карты. Можно
установить использование тега lastmod, либо применять ответ сервера при создании карты. Также возможно ручное
указание даты.
Priority — используется для выставления приоритета ссылки в зависимости от глубины страницы.
Change Frequency — используется для выставления вероятной частоты обновления веб-страниц с помощью тега
changefreq. Рассчитать тег можно либо по последнему измененному заголовку, либо по глубине страницы.
Images — позволяет добавить картинки в карту сайта, включая закрытые от индексации картинки или
изображения с конкретным числом входящих ссылок.
Hreflang — отвечает за использование или не использование атрибута hreflang в карте сайта.
Visualisations
С помощью этого пункта меню можно получить визуализированную структуру сайта, которая будет отображаться в
программе.
Пользователю на выбор предоставляется несколько вариантов визуализации, которые отображаются во встроенном
браузере — это повышает эффективность работы с ними. Например, их можно масштабировать прямо в Screaming Frog.
Доступные режимы:
- Crawl Tree Graph — визуализирует структуру сайта на основании сканирования в виде дерева каталогов.
- Directory Tree Graph — показывает все каталоги, найденные после сканирования. В отличие от
первого режима, показывает даже папки, закрытые от индексации - Force Directed Crawl-Diagram — похожий вариант на 2 других, только оформленный в виде кружков.
- Force Directed Tree-Diagram — похожий, но более масштабный способ визуализации.
- Inlink Anchor Text Word Cloud — визуализирует анкоры внутренних ссылок. Каждая страница отображается
по отдельности. Помогает в анализе анкоров. - Body Text Word Cloud — визуализирует плотность слов на веб-странице. Помогает понять, какие слова
встречаются чаще других и нет ли переспама ими на странице.
Crawl Analysis
Помогает проанализировать и включить в отчет данные, которые не попадают в основную статистику в ходе
сканирования. Это могут быть параметры Link Score, Orphan URLs (потерянные URL) и , и т.п.
Дополнительное сканирование запускается после основного парсинга. Во вкладке Configure можно настроить,
какие данные будут добавляться в отчет.
Возможные опции:
- Link Score — присваивает оценки всем внутренним линкам веб-сайта.
- Pagination — показывает неправильно настроенные пагинации и страницы, которые были найдены только благодаря
атрибуту rel next/prev. - Hreflang — отображает URL с атрибутом hreflang без гиперссылок.
- AMP — показывает страницы без тегов HTML amp.
- Sitemaps — вносит в отчет неидексируемые страницы, найденные в карте сайта, дубли URL в нескольких sitemap,
потерянные страницы. - Analytics — потерянные страницы, найденные в аналитике.
- Search Console — потерянные страницы, найденные в консоли веб-мастера.
Licence
Раздел, в котором можно купить лицензию и ввести лицензионный ключ.
Help
Пункт меню, в котором собрана информация, полезная пользователю.
Доступные подпункты:
- User Guide — супер-подробное руководство по работе с программой.
- FAQ — часто задаваемые вопросы.
- Support — техническая поддержка.
- Feedback — предложения по работе или новым функциям.
- Check for Updates — ручная проверка на наличие обновлений.
- Auto Check for Updates — автоматическая проверка на наличие обновлений.
- Debug — сообщить о каком-либо баге разработчику.
- About — краткая информация о программе.
FAQ
Как включить русский язык?
К сожалению, официально это сделать никак нельзя — программа не поддерживает русскоязычную локализацию.
Но вы можете поискать русификаторы в интернете. Мы не рекомендуем их использовать. Помните, что вы устанавливаете на свой страх и риск.
Как посмотреть структуру сайта?
Воспользуйтесь вкладкой «Visualisations» — в ней наглядно можно будет посмотреть примерную
структуру сайта, основываясь на отчете. Программа предлагает несколько видов графиков, например,
древовидный и в виде «кружков».
Как включить rendering?
Воспользуйтесь следующим путем: configuration > spider > rendering > выбрать нужный пункт
(например, Rendered Page Screenshots).
Как игнорировать Robots.txt?
Во вкладке configuration перейдите в подпункт меню robots.txt и выберите режим «Ignore robots.txt».
Как ограничить скорость сканирования?
Если вы хотите ограничить скорость сканирования, рекомендуем воспользоваться пунктом Limits во вкладке
Configuration > Spider. Также можно выделить меньше RAM для программы — тогда сканирование будет идти
медленнее.
Парсинг сайта может отнимать немало времени, даже если вы работаете через специальные сервисы. Однако многие из них можно адаптировать под собственные задачи с помощью соответствующих настроек. Рассмотрим это на примере сервиса Screaming Frog.
- Место хранения данных;
- User Agent;
- Скорость парсинга;
- Разделы парсинга;
- Что парсить;
- Доступы к аккаунту;
- robots.txt;
- Сохраняем настройки.
Видеоинструкция
Настраиваем где будут храниться данные сканирования Screaming Frog
Первое, что нам необходимо – настроить тип хранения данных. Для этого переходим в пункт меню File (Файл) и выбираем пункт Настройки (Settings) в выпадающем списке.
В новом выпадающем списке выбираем Storage Mode (Тип хранения данных). Здесь их два:
- В оперативной памяти (Memory Storage). При выборе этого режима скачивание происходит быстро, и если оперативной памяти много, а места на жестком диске мало, то он вполне подойдет. Однако для работы с большим сайтом его может быть недостаточно.
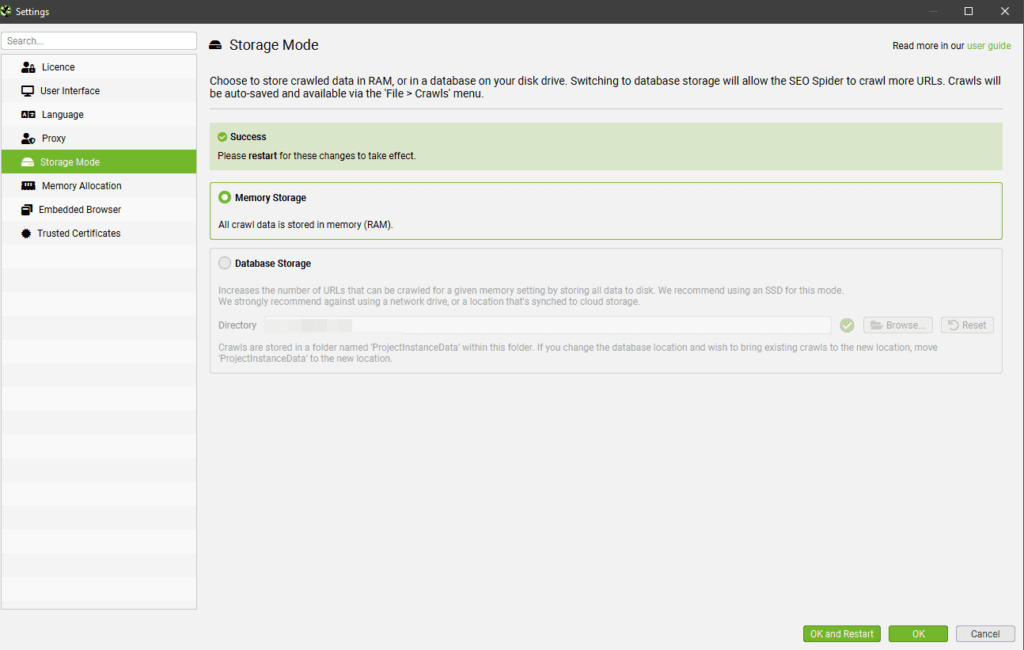
- На жестком диске (Database Storage). Здесь потребуется выбрать путь хранения, где будут размещаться все данные. Однако парсинг в данном случае идет медленнее, а скачиваемые файлы занимают намного больше места, чем при хранении в оперативной памяти.
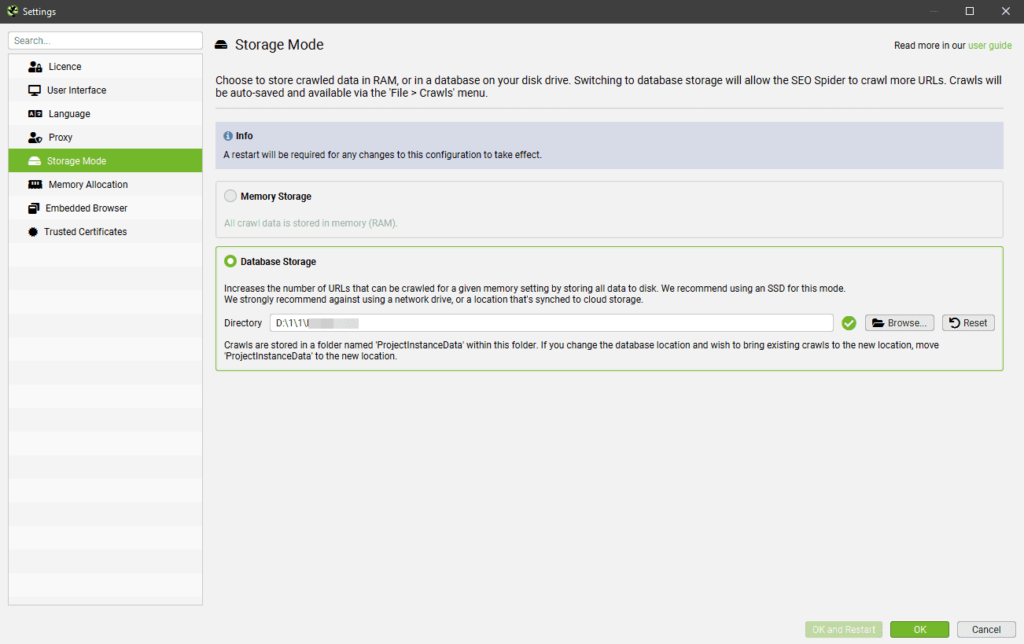
Далее возвращаемся в пункт Settings и выбираем Memory Allocation. Здесь вы можете установить количество оперативной памяти, которую система может использовать для хранения. Это пригодится, если параллельно вы работаете над чем-то еще.
Настраиваем User Agent
Теперь переходим во вкладку Configurations в верхнем меню и кликаем по пункту User-Agent. Его необходимо настроить для парсинга сайтов.
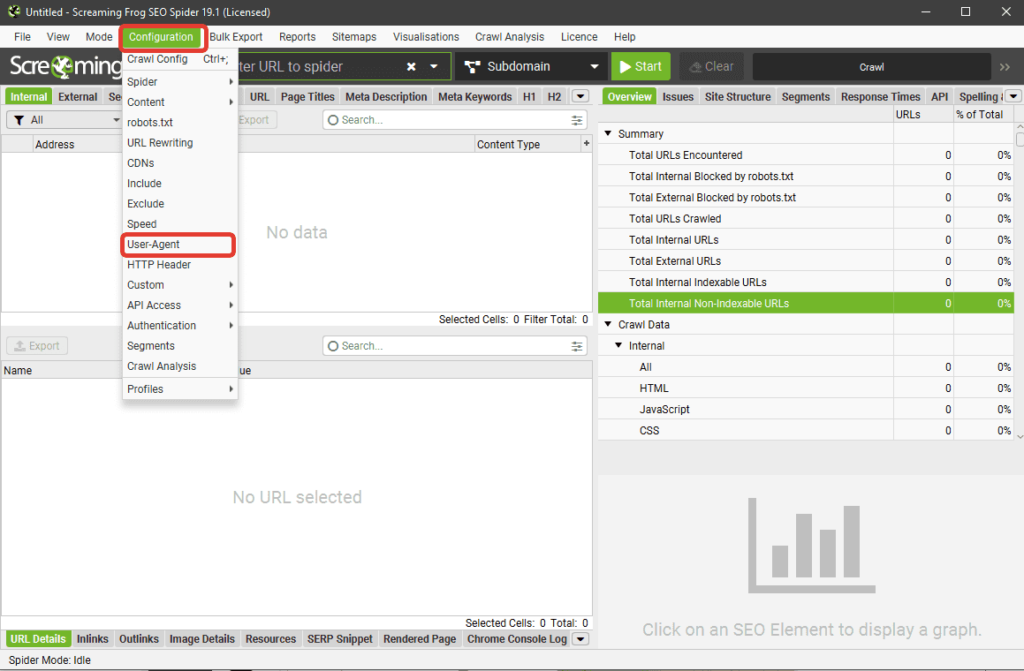
В выпадающем списке можно выбрать любого юзер-агента – к примеру, Гугл-бот для смартфонов особенно удобен. Screaming Frog в этом случае маскируется под бота, и сайт отдает всю нужную информацию без блокировки.
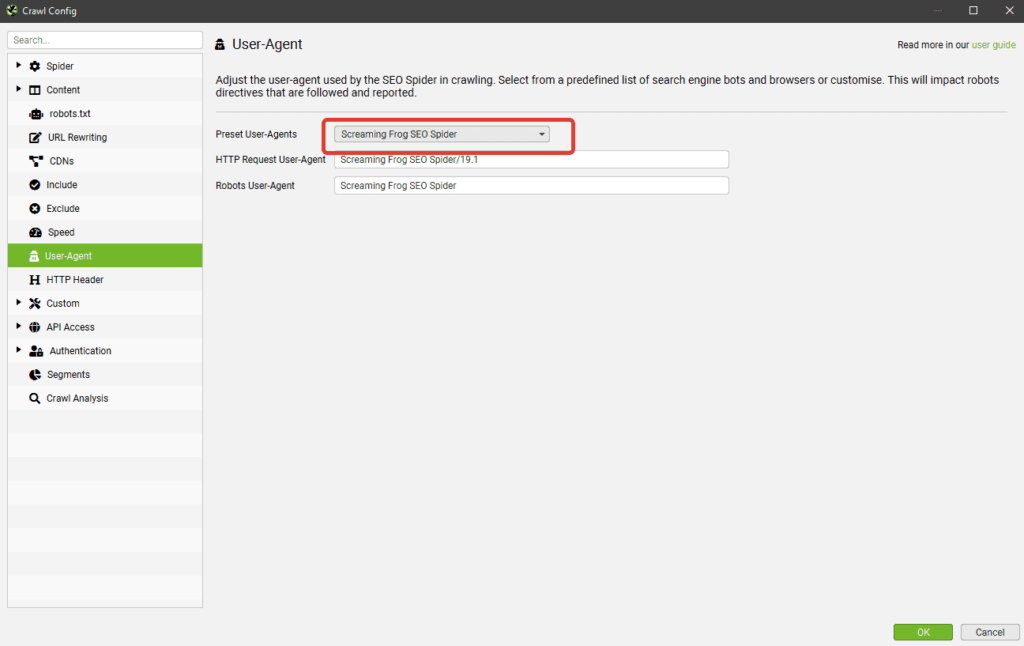
Настройка скорости парсинга
После настройки юзер-агента возвращаемся в Configurations и выбираем пункт Speed. Здесь можно задать до 20 потоков. Однако для не слишком мощного компьютера может быть достаточно и пяти.
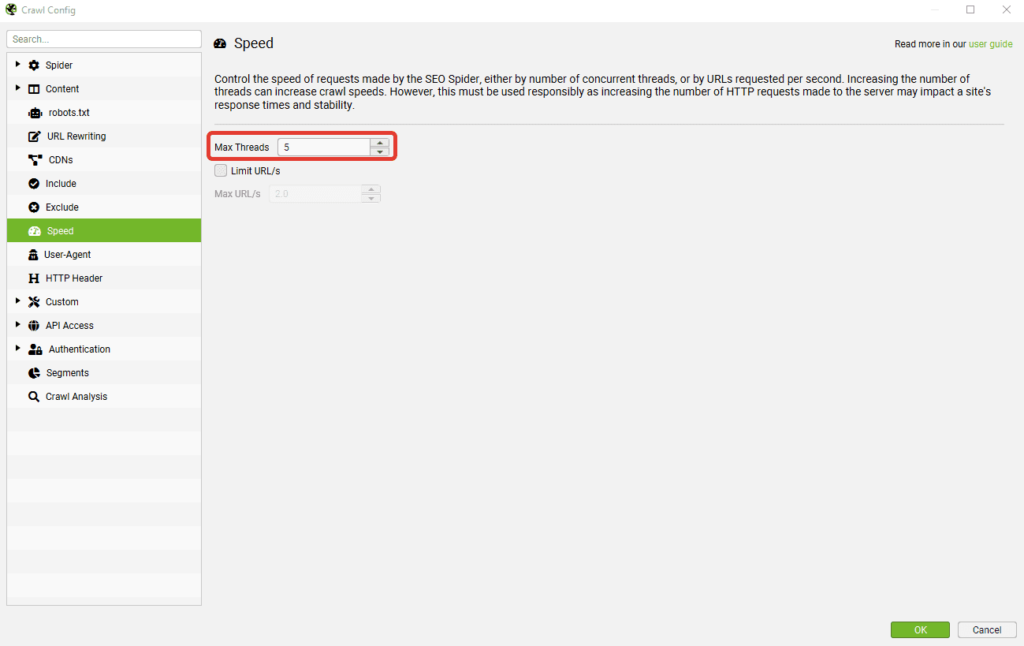
Настраиваем выборку разделов для парсинга
Далее нам может потребоваться задать настройки парсинга. Если нужен технический аудит всего сайта, делать это необязательно. Однако если в приоритете анализ каких-то определенных разделов, сузить поиск все же стоит.
Делается это через вкладку Configurations, пункт меню – Include.
Здесь мы можем ввести данные раздела или страницы товара, чтобы посмотреть, будет ли он попадать в парсинг. Например, вводим «/razdel1» и проверяем будет ли при этом сканироваться интересующий нас URL «https://www.example.com/razdel1/123123».
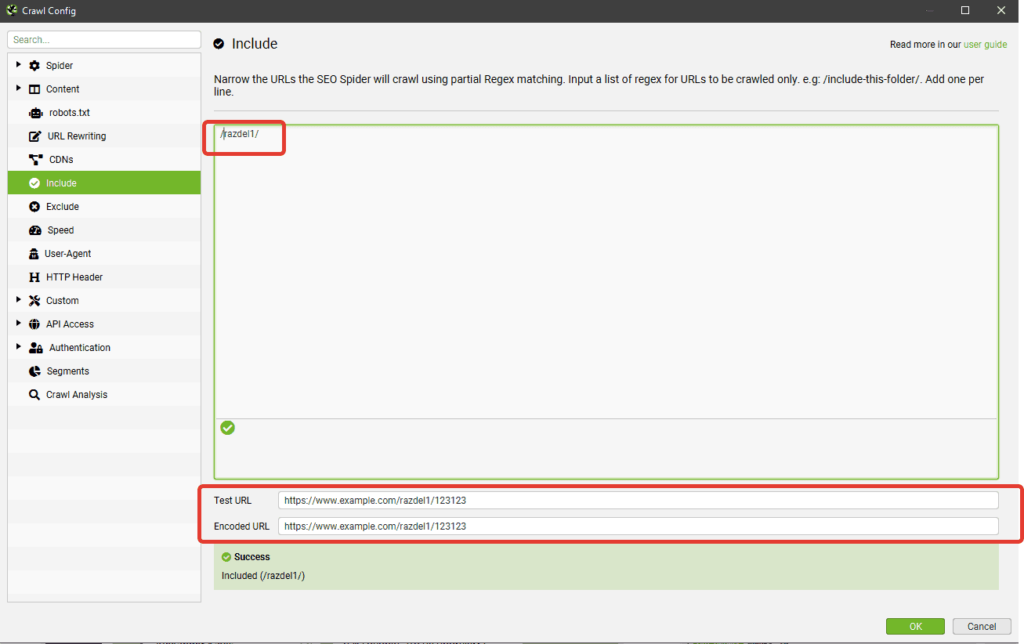
Если же URL не попадает под сканирование, то будет указана следующая проблема.
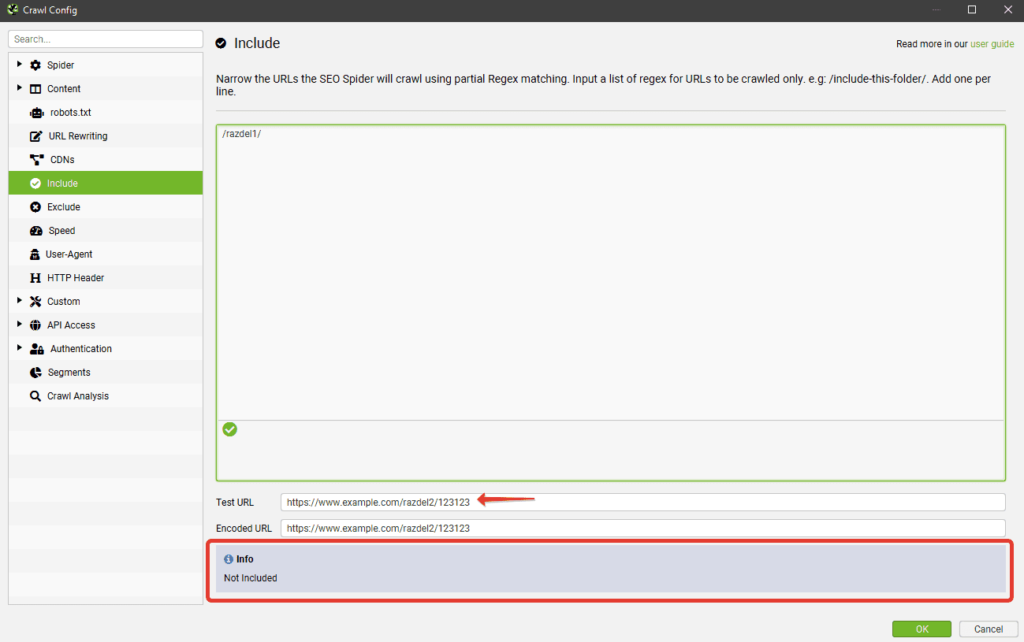
Если, напротив, требуется исключить какой-либо раздел из парсинга, действуем так же, но через пункт Exclude.
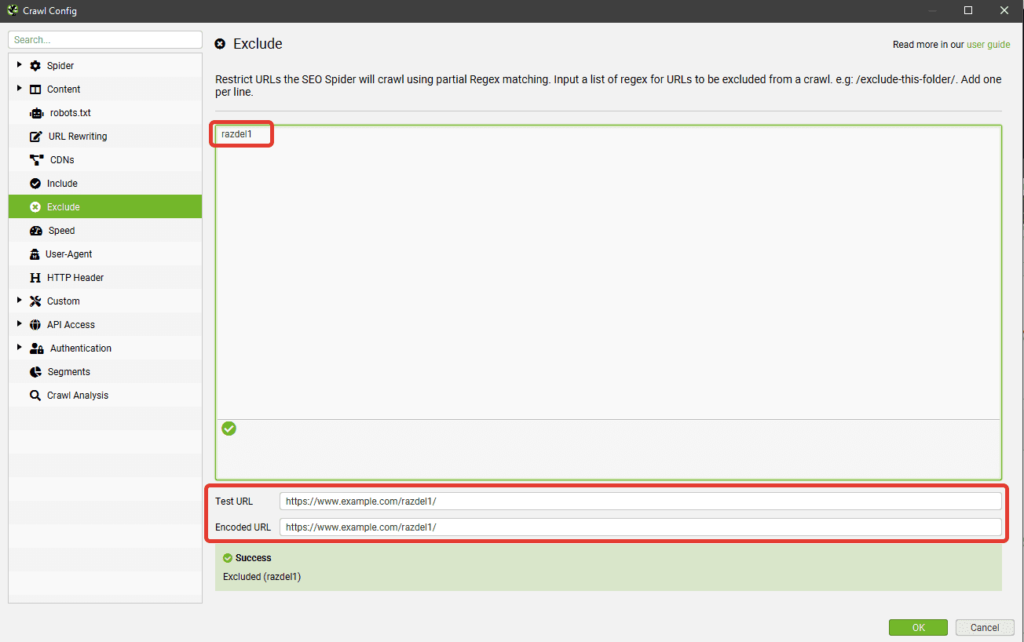
Настраиваем Spider Crawl
На этом этапе мы выбираем тип сканирования данных. Для этого переходим в Configurations, выбираем пункт Spider и кликаем по Crawl в выпадающем списке.
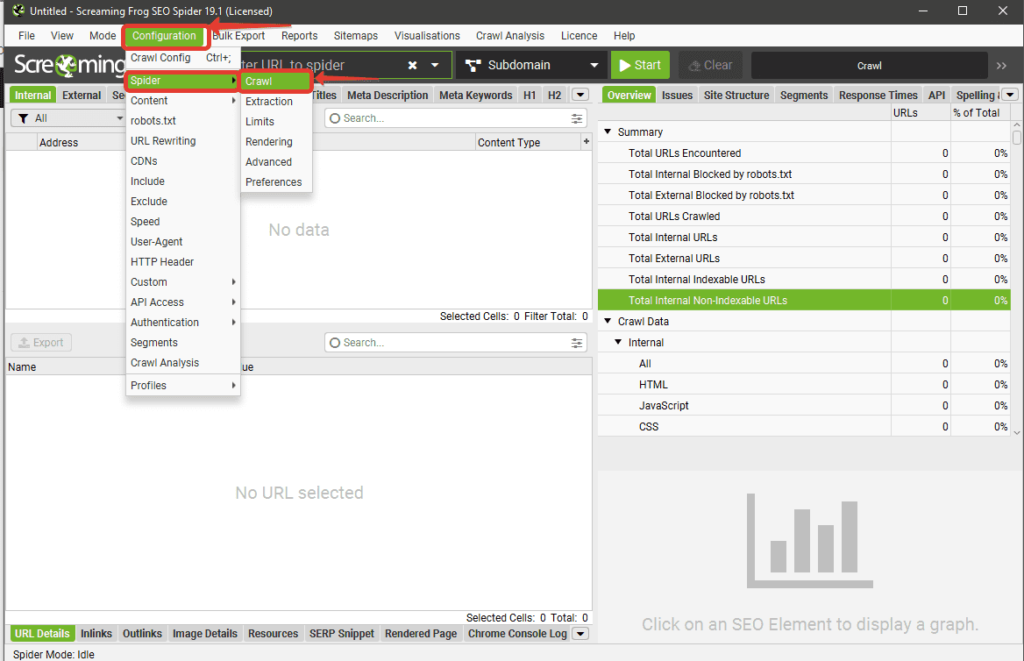
Далее устанавливаем флажки напротив данных, которые нам нужны и отключаем парсинг ненужных типов данных. Если сайт небольшой, эти настройки можно оставить по умолчанию – в этом случае лучше просканировать все.
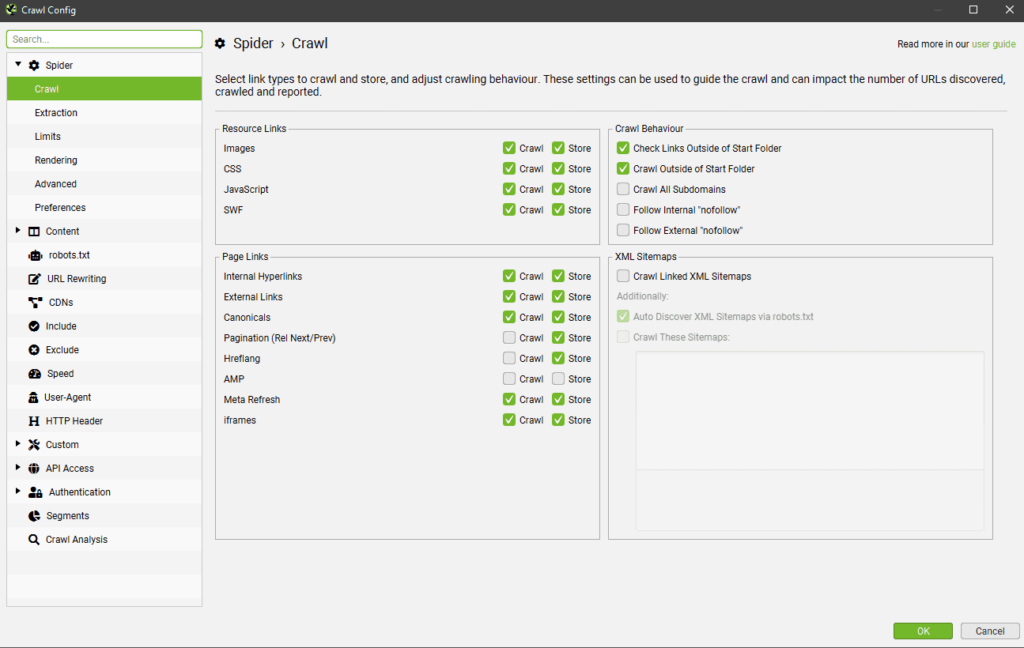
После этого переходим в раздел Extraction здесь же и выбираем, что именно будет сканироваться – тайтлы, дескрипшены, структурированные данные и так далее. Все ненужное можно исключить.
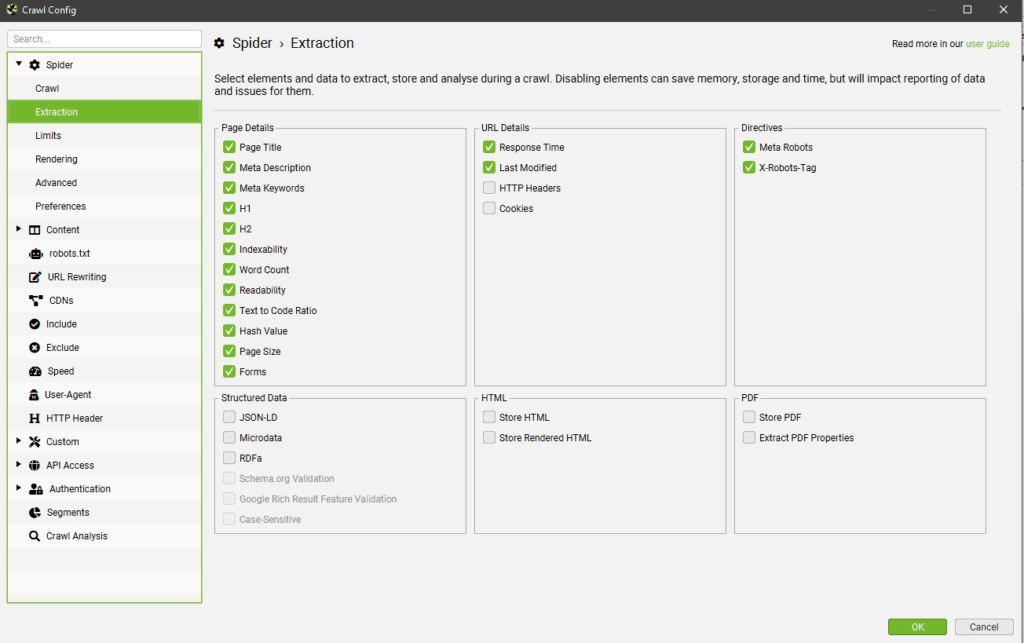
Подключаем доступ к сайту через аккаунт Google
Теперь снова возвращаемся в Configurations, пункт API Access. Здесь выбираем Google Search Console. Это требуется для поиска проблемных страниц, на которые не ведет ни одна ссылка – так называемых Orphan Pages или Orphan URLs. В этом случае их можно быстро найти и сделать необходимую перелинковку.
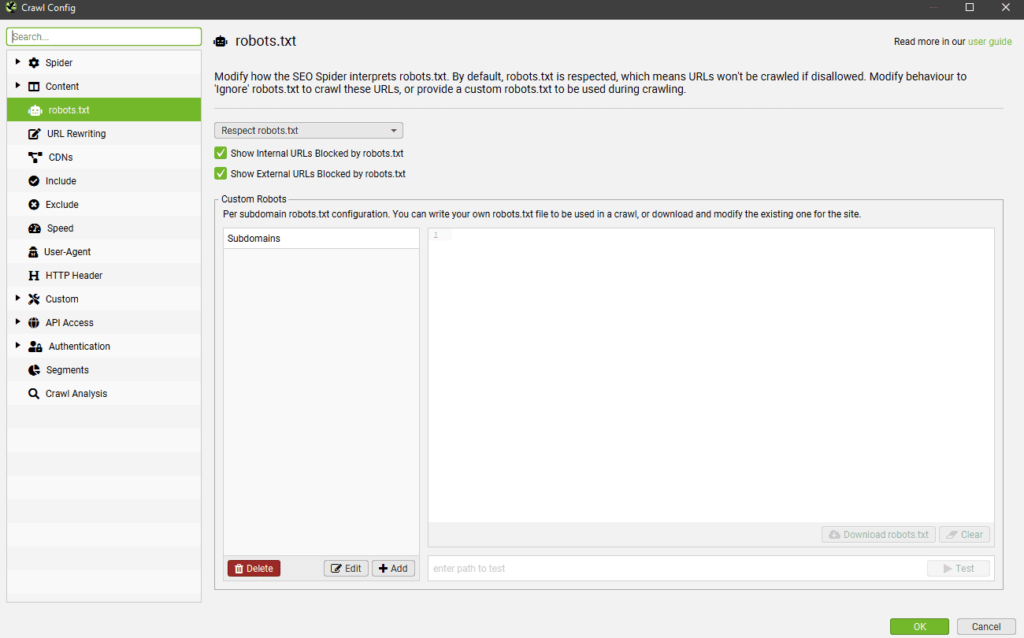
Настраиваем работу с robots.txt
Теперь мы еще раз переходим в меню Configuration и выбираем соответствующий пункт. Далее мы выбираем, в каком режиме работать с robots.txt:
- Ignore – если необходимо видеть весь сайт целиком.
- Respect – с участием функционала robots.txt.
- Ignore robots.txt but report status – если нужны данные о смене статуса страниц.
Сохраняем настройки как базовые в Screaming Frog
Если все указанные выше настройки требуются вам постоянно, стоит сохранить их соответствующим образом, поскольку Screaming Frog всегда открывается с базовых параметров. Для этого переходим в пункт Profile в меню Configuration и выбираем Save Current Configuration as Default («сохранить текущие настройки по умолчанию»).
Здесь же вы можете создать несколько соответствующих профилей для различных задач и просто менять пакет настроек под приоритетную.

Для большинства людей общий аудит сайта – задача достаточно сложная и трудоемкая, однако с такими инструментами, как Screaming Frog SEO Spider (СЕО Паук) задача может стать значительно более простой как для профессионалов, так и для новичков. Удобный интерфейс Screaming Frog обеспечивает легкую и быструю работу, однако многообразие вариантов конфигурации и функциональности может затруднить знакомство с программой, первые шаги в общении с ней.
Нижеследующая инструкция призвана продемонстрировать различные способы использования Screaming Frog в первую очередь для аудита сайтов, но также и других задач.
Базовые принципы сканирования сайта
-
Как сканировать весь сайт.
По умолчанию Screaming Frog сканирует только поддомен, на который вы заходите. Любой дополнительный поддомен, с которым сталкивается Spider, рассматривается как внешняя ссылка. Для того чтобы сканировать дополнительные поддомены, необходимо внести корректировки в меню конфигурации Spider. Выбрав опцию «Crawl All Subdomains», вы можете быть уверены в том, что Паук проанализирует любые ссылки, которые встречаются на поддоменах вашего сайта.
Чтобы ускорить сканирование не используйте картинки, CSS, JavaScript, SWF или внешние ссылки.
-
Как сканировать один каталог.
Если вы хотите ограничить сканирование конкретной папкой, то просто введите URL и нажмите на кнопку «старт», не меняя параметры, установленные по умолчанию. Если вы внесли изменения в предустановленные настройки, то можно сбросить их при помощи меню «File».

Если вы хотите начать сканирование с конкретной папки, а после перейти к анализу оставшейся части поддомена, то перед тем, как начать работу с нужным вам URL, перейдите сначала в раздел Spider под названием «Configuration» и выберите в нем опцию «Crawl Outside Of Start Folder».
-
Как сканировать набор определеных поддоменов или подкатологов.
Чтобы взять в работу конкретный список поддоменов или подкатологов вы можете использовать RegEx, чтобы задать правила включения (Include settings) или исключения (Exclude settings) определенных элементов в меню «Configuration».

На показанном ниже примере были выбраны для сканирования все страницы сайта havaianas.com, кроме страниц «About» в каждом отдельном поддомене (исключение). Следующий пример показывает как можно просканировать именно англоязычные страницы поддоменов этого же сайта (включение).
-
Если требуется просканировать список всех страниц моего сайта.
По умолчанию, Screaming Frog сканирует все изображения JavaScript, CSS и флеш-файлы, с которыми сталкивается Паук. Чтобы анализировать исключительно HTML, вам нужно снять галочку с опций «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider. Запуск Паука будет совершаться без учета указанных позиций, что позволит вам получить список всех страниц сайта, на которые имеются внутренние ссылки. После завершения сканирования перейдите во вкладку «Internal» и отфильтруйте результаты по стандарту HTML. Кликните по кнопке «Export», чтобы получить полный список в формате CSV.
Совет: Если вы намерены использовать заданные настройки для последующих сканирований, то Screaming Frog предоставит вам возможность сохранить заданные опции.
-
Если требуется просканировать список всех страниц в определенном подкаталоге.
В дополнение к «Check Images», «Check CSS», «Check JavaScript» и «Check SWF» в меню «Configuration» Spider вам нужно будет выбрать «Check Links Outside Folder». То есть вы исключите данные опции из Паука, что предоставит вам список всех страниц выбранной папки.
-
Если требуется просканировать список доменов, которые ваш клиент только что перенаправил на свой коммерческий сайт.
В ReverseInter.net добавьте URL этого сайта, после нажмите ссылку в верхней таблице, чтобы найти сайты, использующие те же IP-адрес, DNS-сервер, или код GA.
Далее используя расширение для Google Chrome под названием Scraper, вы сможете найти список всех ссылок с анкором «посетить сайт». Если Scraper уже установлен, то вы можете запустить его, кликнув кнопкой мыши в любом месте страницы и выбрав пункт «Scrape similar». Во всплывающем окне вам нужно будет изменить XPath-запрос на следующее:
//a[text()=’visit site’]/@href.
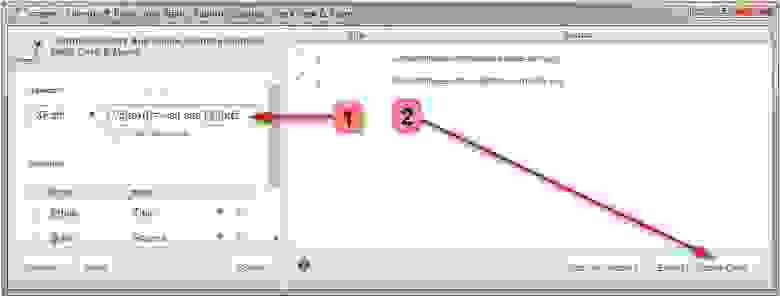
Далее кликните «Scrape» и после «Export to Google Docs». Из вордовского документа вы после сможете сохранить список в качестве файла .csv.
Далее этот список вы сможете загрузить в Spider и запустить сканирование. Когда Spider закончит работу, вы увидите соответствующий статус во вкладке «Internal». Либо же вы можете зайти в «Response Codes» и при помощи позиции «Redirection» отфильтровать результаты, чтобы увидеть все домены, которые были перенаправлены на коммерческий сайт или куда-либо еще.
Обратите внимание на то, что загружая файлы формата .csv в Screaming Frog вы должны выбрать соответственно тип формата «CSV», иначе программа даст сбой.
Совет: Данный метод вы также можете использовать для того, чтобы идентифицировать домены ссылающиеся на конкурентов и выявить, каким образом они были использованы.
-
Как найти все поддомены сайта и проверить внутренние ссылки.
Внесите в ReverseInternet корневой URL-адрес домена, после кликните по вкладке «Subdomains», чтобы увидеть список поддоменов.
После этого задействуйте Scrape Similar, чтобы собрать список URL, используя запрос XPath:
//a[text()=’visit site’]/@href.
Экспортируйте полученные результаты в формате .csv, после загрузите файл CSV в Screaming Frog, используя режим «List». Когда Spider закончит работу, вы сможете просмотреть коды состояния, равно как и любые ссылки на страницах поддоменов, анкорные вхождения и даже повторяющиеся заголовки страниц.
-
Как сканировать коммерческий или любой другой большой сайт.
Screaming Frog не предназначена для того, чтобы сканировать сотни тысяч страниц, однако имеется несколько мер, позволяющих предотвратить сбои в программе при сканировании больших сайтов. Во-первых, вы можете увеличить объем памяти, используемой Пауком. Во-вторых, вы можете отключить сканирование подкаталога и работать лишь с определенными фрагментами сайта, задействуя инструменты включения и исключения. В-третьих, вы можете отключить сканирование изображений, JavaScript, CSS и флеш-файлов, сделав акцент на HTML. Это сбережет ресурсы памяти.
Совет: Если раньше при сканировании больших сайтов требовалось ждать весьма долго окончания выполнения операции, то Screaming Frog позволяет ставить паузу на процедуру использования больших объемов памяти. Эта ценнейшая опция позволяет вам сохранить уже полученные результаты до того момента, когда программа предположительно готова дать сбой, и увеличить размеры памяти.
На данный момент такая опция подключена по умолчанию, но если вы планируете сканировать большой сайт, то лучше все же убедиться, что в меню конфигурации Паука, во вкладке «Advanced» стоит галочка в поле «Pause On High Memory Usage».
-
Как сканировать сайт, размещенный на старом сервере.
В некоторых случаях старые серверы могут оказаться неспособны обрабатывать заданное количество URL-запросов в секунду. Чтобы изменить скорость сканирования в меню «Configuration» откройте раздел «Speed» и во всплывающем окне выберите максимальное число потоков, которые должны быть задействованы одновременно. В этом меню вы также можете выбрать максимальное количество URL-адресов, запрашиваемых в секунду.
Совет: Если в результатах сканирования вы обнаружите большое количество ошибок сервера, перейдите во вкладку «Advanced» в меню конфигурации Паука и увеличите значение времени ожидания ответа (Response Timeout) и число новых попыток запросов (5xx Response Retries). Это позволит получать лучшие результаты.
-
Как сканировать сайт, который требует cookies.
Хотя поисковые роботы не принимают cookies, если при сканировании сайта вам требуется разрешить cookies, то просто выберите «Allow Cookies» во вкладке «Advanced» меню «Configuration».
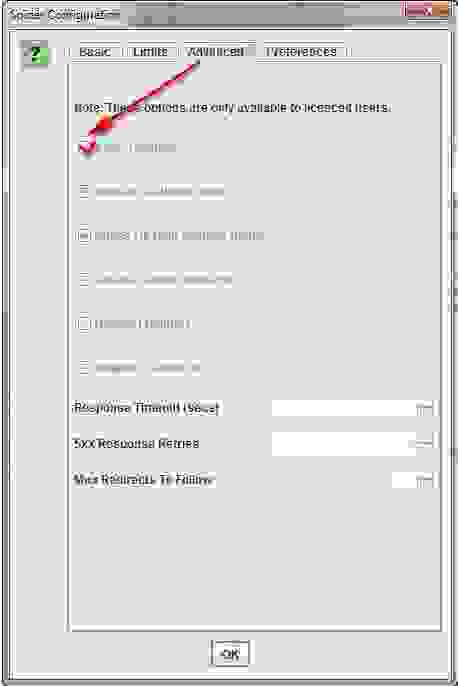
-
Как сканировать сайт, используя прокси или другой пользовательский агент.
В меню конфигурации выберите «Proxy» и внесите соответствующую информацию. Чтобы сканировать, задействуя иной агент, выберите в меню конфигурации «User Agent», после из выпадающего меню выберите поисковый бот или введите его название.
-
Как сканировать сайты, требующие авторизации.
Когда Паук Screaming Frog заходит на страницу, запрашивающую идентификацию, всплывает окно, в котором требуется ввести логин и пароль.
Для того чтобы впредь обходиться без данной процедуры, в меню конфигурации, во вкладке «Advanced» снимите флажок с опции «Request Authentication».
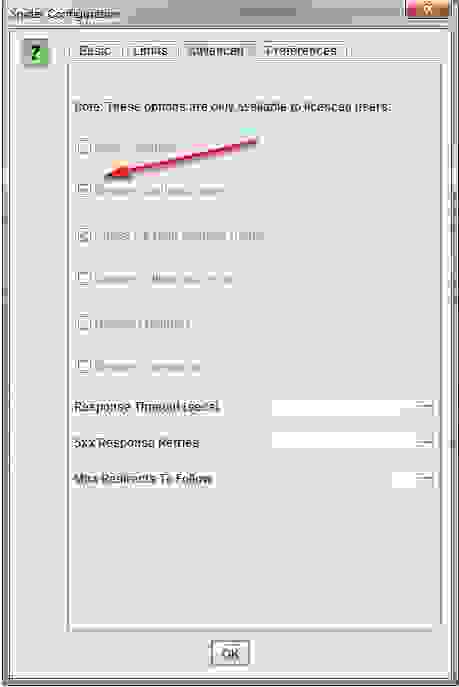
Внутренние ссылки
-
Что делать, когда требуется получить информацию о внешних и внутренних ссылках сайта (анкорах, директивах, перелинковке и пр.).
Если вам не нужно проверять на сайте изображения, JavaScript, Flash или CSS, то исключите эти опции из режима сканирования, чтобы сберечь ресурсы памяти.
После завершения Пауком сканирования, используйте меню «Advanced Export», чтобы из базы «All Links» экспортировать CSV. Это предоставит вам все ссылочные локации и соответствующие им анкорные вхождения, директивы и пр.
Для быстрого подсчета количества ссылок на каждой странице перейдите во вкладку «Internal» и отсортируйте информацию через опцию «Outlinks». Все, чтобы будет выше 100-ой позиции, возможно, потребует дополнительного внимания.
-
Как найти неработающие внутренние ссылки на страницу или сайт.
Как и всегда, не забудьте исключить изображения, JavaScript, Flash или CSS из объектов сканирования, дабы оптимизировать процесс.
После окончания сканировния Пауком, отфильтруйте результаты панели «Internal» через функцию «Status Code». Каждый 404-ый, 301-ый и прочие коды состояния будут хорошо просматриваться.
При нажатии на каждый отдельный URL в результатах сканирования в нижней части окна программы вы увидите информацию. Нажав в нижнем окне на «In Links», вы найдете список страниц, ссылающихся на выбранный URL-адрес, а также анкорные вхождения и директивы, используемые на этих страницах. Используйте данную функцию для выявления внутренних ссылок, требующих обновления.
Чтобы экспортировать в CSV формате список страниц, содержащих битые ссылки или перенаправления, используйте в меню «Advanced Export» опцию «Redirection (3xx) In Links» или «Client Error (4xx) In Links», либо «Server Error (5xx) In Links».
-
Как выявить неработающие исходящие ссылки на странице или сайте (или все битые ссылки одновременно).
Аналогично делаем сначала акцент на сканировании HTML-содержимого, не забыв при этом оставить галочку в пункте «Check External Links».
По завершении сканирования выберите в верхнем окне вкладку «External» и при помощи «Status Code» отфильтруйте содержимое, чтобы определить URL с кодами состояния, отличными от 200. Нажмите на любой отдельный URL-адрес в результатах сканирования и после выберите вкладку «In Links» в нижнем окне – вы найдете список страниц, которые указывают на выбранный URL. Используйте эту информацию для выявления ссылок, требующих обновления.
Чтобы экспортировать полный список исходящих ссылок, нажмите на «Export» во вкладке «Internal». Вы также можете установить фильтр, чтобы экспортировать ссылки на внешние изображения, JavaScript, CSS, Flash и PDF. Чтобы ограничить экспорт только страницами, сортируйте посредством опции «HTML».
Чтобы получить полный список всех локаций и анкорных вхождений исходящих ссылок, выберите в меню «Advanced Export» позицию «All Out Links», а после отфильтруйте столбец «Destination» в экспортируемом CSV, чтобы исключить ваш домен.
-
Как найти перенаправляющие ссылки.
По завершении сканирования выберите в верхнем окне панель «Response Codes» и после отсортируйте результаты при помощи опции «Redirection (3xx)». Это позволит получить список всех внутренних и исходящих ссылок, которые будут перенаправлять. Применив фильтр «Status Code», вы сможете разбить результаты по типам. При нажатии «In Links» в нижнем окне, вы сможете увидеть все страницы, на которых используются перенаправляющие ссылки.
Если экспортировать информацию прямо из этой вкладки, то вы увидите только те данные, которые отображаются в верхнем окне (оригинальный URL, код состояния и то место, в которое происходит перенаправление).
Чтобы экспортировать полный список страниц, содержащих перенаправляющие ссылки, вам следует выбрать «Redirection (3xx) In Links» в меню «Advanced Export». Это вернет CSV-файл, который включает в себя расположение всех перенаправляющих ссылок. Чтобы показать только внутренние редиректы, отфильтруйте содержимое в CSV-файле с данными о вашем домене при помощи колонки «Destination».
Совет: Поверх двух экспортированных файлов используйте VLOOKUP, чтобы сопоставить столбцы «Source» и «Destination» с расположением конечного URL-адреса.
Пример формулы выглядит следующим образом:
=VLOOKUP([@Destination],’response_codes_redirection_(3xx).csv’!$A$3:$F$50,6,FALSE). Где «response_codes_redirection_(3xx).csv» — это CSV-файл, содержащий перенаправляющие URL-адреса и «50» — это количество строк в этом файле.
Контент сайта
-
Как идентифицировать страницы с неинформативным содержанием (т.н. «thin content» − «токний контент»).
После завершения работы Spider перейдите в панель «Internal», задав фильтрацию по HTML, а после прокрутите вправо к столбцу «Word Count». Отсортируйте содержимое страниц по принципу количества слов, чтобы выявить те, на которых текста меньше всего. Можете перетащить столбец «Word Count» влево, поместив его рядом с соответствующими URL-адресами, сделав информацию более показательной. Нажмите на кнопку «Export» во вкладке «Internal», если вам удобнее работать с данными в формате CSV.
Помните, что Word Count позволяет оценить объем размещенного текста, однако не дает решительно никаких сведений о том, является ли этот текст просто названиями товаров/услуг или оптимизированным под ключевые слова блоком.
-
Если требуется выделить с конкретных страниц список ссылок на изображения.
Если вы уже просканировали весь сайт или отдельную папку, то просто выберите страницу в верхнем окне, после нажмите «Image Info» в нижнем окне, чтобы просмотреть изображения, которые были найдены на этой странице. Картинки будут перечисляться в столбце «To».
Совет: Щелкните правой кнопкой мыши на любую запись в нижнем окне, чтобы скопировать или открыть URL-адрес.
Вы можете просматривать изображения на отдельно взятой странице, сканируя именно этот URL-адрес. Убедитесь, что глубина сканирования в настройках конфигурации сканирования Паука имеет значение «1». После того, как страница просканируется, перейдите во вкладку «Images», и вы увидите все изображения, которые удалось обнаружить Spider.
Наконец, если вы предпочитаете CSV, используйте меню «Advanced Export», опцию «All Image Alt Text», чтобы увидеть список всех изображений, их местоположение и любой связанный с ними замещающий текст.
-
Как найти изображения, у которых отсутствует замещающий текст или изображения, имеющие длинный Alt-текст.
Прежде всего, вам нужно убедиться, что в меню Паука «Configuration» выбрана позиция «Check Images». По завершении сканирования перейдите во вкладку «Images» и отфильтруйте содержимое при помощи опций «Missing Alt Text» или «Alt Text Over 100 Characters». Нажав на вкладку «Image Info» в нижнем окне, вы найдете все страницы, на которых размещаются хотя бы какие-нибудь изображения. Страницы будут перечислены в столбце «From».

Вместе с тем, в меню «Advanced Export» вы можете сэкономить время и экспортировать «All Image Alt Text» (Все картинки, весь текст) или «Images Missing Alt Text» (Картинки без Alt-тега) в формат CSV.
-
Как найти на сайте каждый CSS-файл.
В меню конфигурации Паука перед сканированием выберите «Check CSS». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «CSS».

-
Как найти файлы JavaScript.
В меню конфигурации Паука перед сканированием выберите «Check JavaScript». По окончании процесса отфильтруйте результаты анализа в панели «Internal» при помощи опции «JavaScript».
-
Как выявить все плагины jQuery, использованные на сайте, и их местоположение.
Прежде всего, убедитесь, что в меню конфигурации выбрано «Check JavaScript». По завершении сканирования примените в панели «Internal» фильтр «JavaScript», а после сделайте поиск «jQuery». Это позволит вам получить список файлов с плагинами. Отсортируйте перечень по опции «Address» для более удобного просмотра. Затем просмотрите «InLinks» в нижнем окне или экспортируйте информацию в CSV. Чтобы найти страницы, на которых используются файлы, поработайте со столбиком «From».
Вместе с этим, вы можете использовать меню «Advanced Export», чтобы экспортировать «All Links» в CSV и отфильтровать столбец «Destination», дабы просматривать исключительно URL-адреса с «jquery».
Совет: Плохими для СЕО являются не только все плагины jQuery. Если вы видите сайт, использующий jQuery, то разумно будет убедиться, что контент, который вы собираетесь проиндексировать, включен в исходный код страницы и выдается при загрузке страницы, а не после этого. Если вы не уверены в данном аспекте, то почитайте о плагине в интернете, чтобы побольше узнать о том, как он работает.
-
Как определить, где на сайте размещается flash.
Перед сканированием в меню конфигурации выберите «Check SWF». А по завершении работы Паука отфильтруйте результаты в панели «Internal» по значению «Flash».

Помните, что этот метод позволяет лишь найти файлы формата .SWF, расположенные на странице. Если плагин вытаскивается через JavaScript, вам придется использовать пользовательский фильтр.
-
Как найти на сайте внутренние PDF-документы.
После завершения сканирования отфильтруйте результаты работы Spider при помощи опции «PDF» в панели «Internal».
-
Как выявить сегментацию контента в пределах сайта или группы страниц.
Если вы хотите найти на сайте страницы, содержащие необычный контент, установите пользовательский фильтр, выявляющий печати HTML, не свойственные данной странице. Сделано это должно быть до запуска Паука.
-
Как найти страницы, имеющие кнопки социального обмена.
Для этого перед запуском Паука нужно будет установить пользовательский фильтр. Для его установки перейдите в меню конфигурации и нажмите «Custom». После этого введите любой фрагмент кода из исходного кода страницы.
В приведенном примере задачей стояло найти страницы, содержащие кнопку «Like» социальной сети Facebook, соответственно для них был создан фильтр формата «http://www.facebook.com/plugins/like.php».
-
Как найти страницы, использующие iframe.
Для этого необходимо установить для тега <iframe соответствующий пользовательский фильтр.
-
Как найти страницы, содержащие встроенное видео или аудио контент.
Для этого установите пользовательский фильтр для фрагмента кода встраивания под Youtube или любой другой медиа плеер, используемый на сайте.
Мета данные и директивы
-
Как найти страницы с длинными, короткими или отсутсвующими заголовками, meta description или meta keywords
По завершении сканирования перейдите во вкладку «Page Titles» и отфильтруйте содержимое через «Over 70 Characters», чтобы увидеть чрезмерно длинные заголовки страниц. Аналогичное можно проделать в панелях «Meta Description» и «URL». Точно такой же алгоритм можно использовать для определения страниц, с отсутствующими или короткими заголовками и мета данными.

-
Как найти страницы с дублированными заголовками, meta description или meta keywords
По завершении сканирования перейдите во вкладку «Page Titles» и отфильтруйте содержимое через «Duplicate», чтобы увидеть дублирующиеся заголовки страниц. Аналогичное можно проделать в панелях «Meta Description» и «URL».
-
Как найти дублированный контент и/или URL, которые должны быть перенаправлены/переписаны/канонизированы.
По завершении работы Паука перейдите во вкладку «URL» и отфильтруйте результаты посредством «Underscores», «Uppercase» or «Non ASCII Characters», выявив URL, которые бы могли потенциально быть переписаны в более стандартную структуру. Отфильтруйте через инструмент «Duplicate», чтобы увидеть страницы, которые имеют несколько URL-версий. Примените фильтр «Dynamic», чтобы распознать URL-адреса, включающие параметры.
Кроме этого, если вы пройдете в панель «Internal» через фильтр «HTML» и прокрутите подальше вправо к колонке «Hash», то вы увидите уникальную последовательность букв и цифр на каждой странице. Если вы нажмете «Export», то сможете использовать условное форматирование в Excel, чтобы выделить повторяющиеся значения в этом столбце, в итоге показывая, что страницы идентичны и должны быть рассмотрены.
-
Как определить страницы, содержащие Мета-директивы.
После сканирования перейдите в панель «Directives». Чтобы увидеть тип директива просто прокрутите вправо и посмотрите, какие столбцы заполнены. Либо же используйте фильтр, чтобы найти любой из следующих тегов:
- Index;
- Noindex;
- Follow;
- Nofollow;
- Noarchive;
- Nosnippet;
- Noodp;
- Noydir;
- Noimageindex;
- Notranslate;
- Unavailable_after;
- Refresh;
- Canonical.
-
Как определить, что файл robots.txt работает так, как положено.
По умолчанию, Screaming Frog будет соответствовать robots.txt. В качестве приоритетных, программа будет следовать директивам, сделанным специально для пользовательского агента. Если таковых не имеется, то Spider будет следовать любым директивам для бота Google. Если же специальных директив для Googlebot нет, то Паук будет следовать глобальным директивам, принятым для всех пользовательских агентов. При этом Spider выберет лишь один какой-то набор директив, не затрагивая все последующие.
Если вам требуется заблокировать от Паука некоторые части сайта, то используйте для этих целей синтаксис обычного robots.txt с пользовательским агентом Screaming Frog SEO Spider. Если вы хотите игнорировать robots.txt, то просто выберите соответствующую опцию в меню конфигурации программы.
-
Как найти и проверить разметку Schema или другие микроданные.
Чтобы найти каждую страницу, содержащую разметку Schema или другие микроданные, вам нужно использовать пользовательские фильтры. В меню «Configuration» кликните по «Custom» и вбейте тот маркер, который вы ищите.
Чтобы найти каждую страницу, содержащую разметку Schema, просто добавьте следующий фрагмент кода в пользовательский фильтр: itemtype=http://schema.org.
Чтобы найти определенный тип разметки вам придется быть более конкретным. Например, использование пользовательского фильтра ‹span itemprop=”ratingValue”› позволит вам найти все страницы, содержащие разметку Schema для построения рейтингов.
Для сканирования вы можете использовать 5 различных фильтров. После вам останется лишь нажать «OK» и просветить программным сканером сайт или список страниц.
Когда Паук завершит работу, выберите в верхнем окне вкладку «Custom», чтобы увидеть все страницы с искомым вами маркером. Если вы задали более одного пользовательского фильтра, вы сможете поочередно просмотреть их, переключаясь в результатах сканирования между страничками фильтров.
Карта сайта
-
Как создать карту сайта (Sitemap) в XML.
После того, как паук закончил сканировать ваш сайт, нажмите на «Advanced Export» и выберите «XML Sitemap».
Сохранить вашу карту сайта, а после откройте ее в Excel. Выберите «Read Only» и откройте файл «As an XML table». При этом может выйти сообщение, что некоторые схемы не могут быть интегрированы. Просто нажмите на кнопку «Yes».
После того, как карта сайта предстанет перед вами в табличной форме, вы с легкостью сможете изменить частоту, приоритет и прочие настройки. Обязательно убедитесь в том, что Sitemap содержит только один предпочитаемый (канонический) вариант каждого URL, без параметров и прочих дублирующих факторов.
После внесения каких-либо изменений пересохраните файл в режиме XML.
-
Как узнать свой существующий XML-файл Sitemap.
В первую очередь, вам нужно будет создать копию Sitemap на своем ПК. Вы можете сохранить любую живую карту сайта, перейдя на URL и сохранив файл или импортировав его в Excel.
После этого перейдите в раздел меню Screaming Frog под названием «Mode» и выберите «List». После вверху страницы нажмите на «Select File», выберите свой файл и начните сканирование. По завершении работы Spider во вкладке «Internal», разделе «Sitemap dirt» вы сможете увидеть любые перенаправления, ошибки 404, дублированные URL-адреса и т.п.
Общие рекомендации по устранению неполадок
-
Как определить, почему некоторые разделы моего сайта не индексируются или не ранжируются.
Интересно, почему некоторые страницы не индексируются? Во-первых, убедитесь, что они не попали в robots.txt и не были помечены как noindex. Во-вторых, вам нужно удостовериться в том, что пауки могут добраться до страниц сайта, чтобы проверить внутренние ссылки. После того как паук просканирует ваш сайт, экспортируйте список внутренних ссылок как файл CSV, используя HTML-фильтр во вкладке «Internal».
Откройте документ CSV и во второй лист скопируйте список URL-адресов, которые не индексируются или не ранжируются. Используйте VLOOKUP, чтобы посмотреть, присутствуют ли подобные проблемные URL в результатах сканирования.
-
Как проверить, был ли перенос/редизайн сайта успешным.
Вы можете использовать Screaming Frog, чтобы выяснить, были ли старые URL-адреса перенаправлены. Поможет в этом режим «List», посредством которого можно проверить коды состояний. Если старые URL выдают ошибку 404, то вы будете точно знать, какие из них требуют переадресации.
-
Как найти медленно загружающиеся страницы сайта.
После завершения процесса сканирования перейдите во вкладку «Response Codes» и отсортируйте столбец «Response Time» по принципу «от большого к малому», чтобы найти страницы, которые могут страдать от медленной скорости загрузки.
-
Как найти вредоносные программы или спам на сайте.
В первую очередь, вам необходимо выявить следы, оставленные вредоносными программами или спамом. Далее в меню конфигурации нажмите на «Custom» и внесите название маркера, который вы ищите. За одно сканирование вы можете анализировать до 5 таких маркеров. Внесите все необходимые и после нажмите на «OK», чтобы изучить весь сайт или перечень страниц на нем.
По завершении процесса перейдите во вкладку «Custom», располагающуюся в верхнем окне, чтобы просмотреть все страницы, на которых были обнаружены указанные вами «следы» мошеннических и вирусных программ. Если вы задали более одного пользовательского фильтра, то результаты по каждому будут выведены в отдельное окно, и вы сможете ознакомиться с ними, переходя от одного фильтра к другому.
PPC и аналитика
-
Как одновременно проверить список всех URL, используемых для контекстной рекламы.
Сохраните список адресов в формате .txt или .csv и измените настройки режима с «Mode» на «List». После выберите свой файл для загрузки и нажмите на «Start». Просмотрите во вкладке «Internal» код состояния по каждой странице.
Scraping
-
Как собрать мета данные с ряда страниц.
У вас имеется куча URL-адресов, по которым важно получить как можно больше информации? Включите режим «Mode», затем загрузите список адресов формате .txt или .csv. После того как Spider завершит выполнение рабочей операции, вы сможете увидеть коды состояния, исходящие ссылки, количество слов и, конечно, мета данные по каждой странице в вашем списке.
-
Как сделать scraping сайта для всех страниц, содержащих определенный маркер.
Прежде всего, вам нужно будет разобраться с самим маркером – определить, что именно вам необходимо. После этого в меню «Configuration» нажмите на «Custom» и введите название искомого маркера. Помните, что вы можете ввести до 5 различных маркеров. Затем нажмите на «OK», чтобы запустить процесс сканирования и отфильтровать страницы сайта по наличию на них указанных «следов».
На примере показана ситуация, когда требуется найти все страницы, содержащие слова «Please Call» в разделах, касающихся стоимости товаров. Для этого был найден и скопирован HTML-код из исходного кода страницы.
После сканирования вам нужно перейти в раздел «Custom» в верхнем окне, чтобы просмотреть список всех страниц, содержащих заданный маркер. Если было введено более одного маркера, то информация по каждому из них будет подана в отдельном окне.
Совет: Данный метод хорош в том случае, если у вас нет прямого доступа к сайту. Если же вам требуется получить данные с сайта клиента, то значительно проще и быстрее будет попросить его взять нужную информацию непосредственно из базы данных и передать вам.
Переписывание URL
-
Как найти и удалить ID сессии или другие параметры из просканированных URL-адресов.
Чтобы идентифицировать URL с ID-сессиями или другими параметрами просто отсканируйте сайт с учетом настроек, заданных по умолчанию. По завершении работы Паука прейдите во вкладку «URL» и примените фильтр «Dynamic», чтобы увидеть все URL-адреса, содержащие требуемые параметры.
Чтобы на отсканированных страницах удалить параметры из показа выберите «URL Rewriting» в меню конфигурации. Затем в панели «Remove Parameters» нажмите «Add», чтобы добавить параметры, которые вы хотите убрать из URL и нажмите «OK». Чтобы активизировать внесенные изменения вам потребуется вновь запустить Паука.
-
Как переписать отсканированные URL (например, сменить .com на .co.uk или записать все URL в нижнем регистре).
Чтобы переписать любой из проработанных пауком адресов выберите в меню конфигурации «URL Rewriting», а после в панели «Regex Replace» нажмите на «Add» и добавить RegEx к тому, что вам требуется заменить.
После того, как вы внесете все требуемые корректировки, вы сможете проверить их в панели «Test» путем введения тестовых URL в окно «URL before rewriting». Строка «URL after rewriting» будет обновляться автоматически, следуя заданным вами параметрам.
Если вам требуется переписать все URL-адреса нижним регистром, то просто выберите «Lowercase discovered URLs» в панели «Options».
Не забудьте вновь запустить Spider после внесения изменений, чтобы те вступили в свои права.
Анализ ключевых слов
-
Как узнать, какие страницы сайтов конкурентов имеют наибольшую ценность.
В целом, конкуренты будут пытаться расширять ссылочную популярность и привлекать трафик на свои наиболее ценные страницы путем их внутренней перелинковки. Любой уделяющий внимание SEO конкурент также выстраивать прочную связь между корпоративным блогом и самыми важными страницами сайта.
Найдите наиболее значимые страницы сайта конкурента путем сканирования, а после перейдите в панель «Internal» и отсортируйте результаты в столбце «Inlinks» по принципу «от большого к малому», чтобы увидеть, какие страницы имеют более всего внутренних ссылок.
Чтобы просмотреть страницы, связанные с корпоративным блогом конкурента, уберите галочку из «Check links outside folder» в меню конфигурации Паука и просканируйте папку/поддомен блога. Затем в панели «External» отфильтруйте полученные результаты, используя поиск по URL главного домена. Прокрутите страницу до конца вправо и отсортируйте список в столбце «Inlinks», чтобы увидеть страницы, которые линкуются чаще всего.
Совет: Для удобства работы с таблицей программы перемещайте столбцы влево и вправо методом Drag and Drop.
-
Как узнать, какие анкоры конкуренты используют для внутренней перелинковки.
В меню «Advanced Export» выберите «All Anchor Text», чтобы экспортировать CSV, содержащие анкорные вхождения сайта и узнать их местоположение и привязки.
-
Как узнать, какие мета ключевики конкуренты используют на своем сайте.
После того как паук завершит сканирование, загляните в панель «Meta Keywords», чтобы просмотреть список мета ключевиков, найденных на каждой отдельной странице. Отсортируйте столбец «Meta Keyword 1» по алфавиту, чтобы сделать информацию более показательной.
Ссылочное построение
-
Как проанализировать потенциальные места расположения ссылок.
Собрав список URL-адресов, вы можете просканировать их в режиме «List», чтобы собрать как можно больше информации о страницах. После завершения сканирования проверьте коды состояния в панели «Response Codes» и в панели «Out Links» изучите исходящие ссылки, типы ссылок, анкорные вхождения и директивы. Это даст вам представление о том, какие сайты ссылаются эти страницы и как.
Для обзора панели «Out Links» убедитесь, что интересующий вас URL выбран в верхнем окне.
Вы наверняка захотите использовать пользовательские фильтры, чтобы определить, нет ли уже в данных местах ссылок.
Вы также можете экспортировать полный список ссылок, нажав на опцию «All Out Links» в панели «Advanced Export Menu». Это позволит получить не только ссылки, ведущие на сторонние сайты, но и показать внутренние ссылки по отдельным страницам вашего списка.
-
Как найти битые ссылки для внешней рекламы.
Итак, имеется сайт, с которого вы бы хотели получить ссылки на свой собственный ресурс. Используя Screaming Frog, вы можете найти битые ссылки на страницы сайта (или на весь сайт целиком) и после, связавшись с владельцем понравившегося вам ресурса, предложить ему заменить битые ссылки ссылками на ваш ресурс там, где это возможно.
-
Как проверить обратные ссылки и просмотреть анкоры.
Загрузите список своих обратных ссылок и запустите Паука в режиме «List». После экспортируйте полный список внешних ссылок, нажав на «All Out Links» в меню «Advanced Export Menu». Это предоставит вам URL и якорный текст/Alt-текст для всех ссылок на этих страницах. После этого вы можете отфильтровать столбец «Destination» в CSV-файле, чтобы определить, перелинкован ли ваш сайт и какой якорный текст/Alt-текст он включает.
-
Как убедиться в том, что обратные ссылки были успешно удалены.
Для этого требуется установить пользовательский фильтр, который содержит корневой домен URL, затем загрузить свой список обратных ссылок и запустить Паука в режиме «List». По окончании сканирования перейдите в панель «Custom», чтобы просмотреть список страниц, которые продолжают на вас ссылаться.
Совет: Помните о том, что нажав правой кнопкой мыши на любой URL-адрес в верхнем окне результатов сканирования, вы можете, в частности:
- Скопировать или открыть URL-адрес.
- Запустить повторное сканирование адреса или убрать его из списка.
- Экспортировать информацию о URL или изображении, имеющемся на этой странице, входящих и исходящих ссылках.
- Проверить индексацию страницы в Google, Bing и Yahoo.
- Проверить обратные ссылки страницы в Majestic, OSE, Ahrefs и Blekko.
- Просмотреть кэшированную версию.
- Просмотреть старые версии страницы.
- Открыть robots.txt для домена, в котором находится страница.
- Запустить поиск для других доменов на том же IP.
Заключение
Итак, мы детально рассмотрели все аспекты использования программы Screaming Frog. Надеемся, что наша подробная инструкция поможет Вам сделать аудит сайта более простым и в тоже время достаточно эффективным, при этом даст возможность сэкономить массу времени.