
Добавил:
Morze
Разработчик ПО
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
ОС Нижний.pdf
Скачиваний:
5
Добавлен:
25.03.2023
Размер:
2.75 Mб
Скачать

Лабораторный практикум по курсу «Операционные системы»
Имя бита
PG_active
PG_dirty
PG_launder
PG_locked
PG_lru
PG_referenced
PG_reserved
Описание
Отмечает «горячие» страницы. Бит устанавливается, если страница в списке active_list (LRU), и сбрасывается, если страница удаляется из этого списка.
Признак того, что страницу нужно записать на диск. Когда страница записывается на диск, бит не очищается немедленно, чтобы страница не была освобождена до завершения операции записи.
Бит важен только для подсистемы замещения страниц. Когда подсистема виртуальной памяти выгружает страницу на диск, она устанавливает данный бит и вызывает функцию writepage(). При просмотре, если обнаруживается страница с установленными битам PG_launder и PG_locked, подсистема виртуальной памяти подождет завершения операции ввода/вывода.
Устанавливается, когда страница должна быть заблокирована в памяти для окончания дискового ввода/вывода. Сбрасывается по окончании операции.
Установлен, если страница находится в active_list или inactive_list.
Бит, установленный в том случае, если страница использовалась ее процессом-владельцем. Используется при работе алгоритма замещения страниц.
При загрузке устанавливается для страниц, которые не выгружаются на диск. Позднее используется для указания пустых страниц или страниц, которые не существуют.
Адресное пространство процесса
Адресное пространство процесса делится на две части – пользовательскую и часть, принадлежащую ядру. Работа с этими частями существенно отличается. Например, часть, принадлежащая ядру является всегда видимой вне зависимости от того, какой процесс выполняется, и не меняется при переключениях контекста. Запросы на выделение памяти для ядра обслуживаются немедленно. При выделении памяти в пользовательской части, для дескрипторы выделенных страниц устанавливаются таким образом, чтобы ссылаться на специальную страницу, заполненную нулями. В случае если процесс попытается выполнить запись в выделенные ему страницы, происходит страничный сбой, и только в этот момент для процесса будет выделена новая страница.
Пользовательская часть адресного пространства процесса состоит из множества регионов, выровненных по границе страницы. Регионы не перекрываются и представляют множество страниц, объединенных единым назначением и правами доступа. Страницы региона могут быть еще не выделены, быть активными и располагаться в оперативной памяти или быть выгружены на диск.
Пользовательская часть адресного пространства процесса описывается структурой mm_struct, регионы описываются структурами struct vm_area_struct. Если регион имеет соотнесенный с ним блок на диске, у него будет установлено поле vm_file.
Используя vm_file->f_dentry->d_inode->i_mapping, можно получить доступ к
Учебно-исследовательская лаборатория «Информационные технологии» 117

Лабораторный практикум по курсу «Операционные системы»
структуре address_space, содержащую всю необходимую информацию для выполнения дисковых операций (загрузка/выгрузка страниц).
Структура mm_struct определена следующим образом (<linux/sched.h>)
210 struct mm_struct {
211 struct vm_area_struct * mmap;
212 rb_root_t mm_rb;
213 struct vm_area_struct * mmap_cache; 214 pgd_t * pgd;
215 atomic_t mm_users;
216 atomic_t mm_count;
217 int map_count;
218 struct rw_semaphore mmap_sem;
219 spinlock_t page_table_lock;
220
221 struct list_head mmlist;
222
226 unsigned long start_code, end_code, start_data, end_data; 227 unsigned long start_brk, brk, start_stack;
228 unsigned long arg_start, arg_end, env_start, env_end; 229 unsigned long rss, total_vm, locked_vm;
230 unsigned long def_flags;
231 unsigned long cpu_vm_mask;
232 unsigned long swap_address;
233
234 unsigned dumpable:1;
235
236 /* Architecture-specific MM context */
237 mm_context_t context;
238 };
mmap – начало списка регионов;
mm_rb – регионы упорядочены в связном списке и в красно-черном дереве (бинарном, для осуществления быстрого поиска); данное поле – корень бинарного дерева;
mmap_cache – в данном поле сохраняется результат последнего вызова find_vma(); pgd – Page Global Directory (таблица таблиц страниц) процесса;
mm_users – число пользователей адресного пространства процесса; mm_count – число пользователей данной структуры mm_struct;
118 Учебно-исследовательская лаборатория «Информационные технологии»

Лабораторный практикум по курсу «Операционные системы»
map_count – количество регионов;
mmap_sem – поле, позволяющее блокировать доступ к списку регионов при выполнении над ним операций чтения и записи;
page_table_lock – поле, используемое для блокировки доступа к большинству полей структуры;
mmlist – все структуры mm_struct связаны в список через данное поле; start_code,end_code – начало и конец секции кода; start_data,end_data – начало и конец секции данных; start_brk,brk – начало и конец кучи;
start_stack – начало стека;
arg_start,arg_end – начало и конец секции аргументов командной строки; env_start,env_end – начало и конец секции переменных окружения;
rss – Resident Set Size – число резидентных страниц для данного процесса; total_vm – суммарный размер всех регионов процесса;
locked_vm – число резидентных страниц, заблокированных в памяти;
def_flags – может иметь значение VM_LOCKED (вся выделяемая в будущем память будет заблокирована);
cpu_vm_mask – битовая маска, определяющая все возможные процессоры в многопроцессорной системе (SMP);
swap_address – последний адрес, отправленный в область подкачки при последней выгрузке процесса из оперативной памяти целиком;
dumpable – Устанавливается функцией prctl(). Используется только при отладке. context – контекст адресного пространства (специфичен для конкретной архитектуры). Структура vm_area_struct определена следующим образом (<linux/mm.h>)
44 struct vm_area_struct {
45 struct mm_struct * vm_mm;
46 unsigned long vm_start;
47 unsigned long vm_end;
49
50 /* linked list of VM areas per task, sorted by address */ 51 struct vm_area_struct *vm_next;
52
53 pgprot_t vm_page_prot;
54 unsigned long vm_flags;
55
56 rb_node_t vm_rb;
Учебно-исследовательская лаборатория «Информационные технологии» 119

Лабораторный практикум по курсу «Операционные системы»
57
63 struct vm_area_struct *vm_next_share; 64 struct vm_area_struct **vm_pprev_share; 65
66 /* Function pointers to deal with this struct. */ 67 struct vm_operations_struct * vm_ops;
68
69 /* Information about our backing store: */
70 unsigned long vm_pgoff;
72 struct file * vm_file;
73 unsigned long vm_raend;
74 void * vm_private_data;
75 };
vm_mm – структура mm_struct – владелец региона; vm_start – адрес начала региона;
vm_end – адрес конца региона;
vm_next – все регионы объединены в список через это поле;
vm_page_prot – флаги доступа к страницам региона, установленные в таблице страниц; vm_flags – флаги доступа к региону;
vm_rb – поле, используемое для соединения регионов в бинарное дерево;
vm_next_share – разделяемые регионы, базирующиеся на отображении файлов в память, связаны в список через данное поле;
vm_pprev_share – дополнение к vm_next_share;
vm_ops – содержит указатели на функции open(), close() и nopage();
vm_pgoff – выровненное по границе страницы смещение в файле, который отображен в память;
vm_file – файл, отображаемый в память;
vm_raend – при обработке страничного сбоя в оперативную память считывается несколько страниц (чтение с предвыборкой), данное поле определяет число дополнительно считываемых страниц;
vm_private_data – используется некоторыми драйверами устройств.
120 Учебно-исследовательская лаборатория «Информационные технологии»
![]()
Лабораторный практикум по курсу «Операционные системы»
Рис. 55 Структуры данных, связанные с адресным пространством процесса
Существует ряд вызовов для работы с регионами. Упомянем два из них:
find_vma() – выполняет поиск региона, содержащего указанный адрес или ближайший к нему;
find_vma_prev() – то же, но возвращает еще и предыдущий регион.
Повторим, что в случае, если регион соотнесен с областью внутри файла на диске, используя vm_file->f_dentry->d_inode->i_mapping, можно получить доступ к структуре address_space. Данная структура определенна следующим образом (<linux/fs.h>).
401 struct address_space {
402 struct list_head clean_pages;
403 struct list_head dirty_pages;
404 struct list_head locked_pages;
405 unsigned long nrpages;
406 struct address_space_operations *a_ops; 407 struct inode *host;
408 struct vm_area_struct *i_mmap;
409 struct vm_area_struct *i_mmap_shared;
Учебно-исследовательская лаборатория «Информационные технологии» 121

Лабораторный практикум по курсу «Операционные системы»
410 spinlock_t i_shared_lock;
411 int gfp_mask;
412 };
clean_pages – количество страниц, не требующих записи на диск;
dirty_pages – количество страниц, измененных процессом и требующих записи на диск; locked_pages – число страниц, заблокированных в памяти;
nrpages – число резидентных страниц, используемое данной областью; a_ops – структура указателей на функции файловой системы;
host – inode файла;
i_mmap – регион, частью которого является данная область;
i_mmap_shared – указатель на следующий регион, разделяющий данную область; i_shared_lock – поле, используемое для блокировки доступа к структуре; gfp_mask – маска, используемая при вызове __alloc_pages().
Периодически менеджер памяти должен сбрасывать страницы на диск. Структура a_ops предоставляет возможность использовать набор функций для работы со страницами области, не заботясь о том, каким образом выполняются операции (<linux/fs.h>).
383 struct address_space_operations {
384 int (*writepage)(struct page *);
385 int (*readpage)(struct file *, struct page *);
386 int (*sync_page)(struct page *);
387/*
388* ext3 requires that a successful prepare_write()
*call be followed
389* by a commit_write() call — they must be balanced
390*/
391int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
392int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
393/* Unfortunately this kludge is needed for FIBMAP.
*Don’t use it */
394int (*bmap)(struct address_space *, long);
395int (*flushpage) (struct page *, unsigned long);
396int (*releasepage) (struct page *, int);
397#define KERNEL_HAS_O_DIRECT
398int (*direct_IO)(int, struct inode *, struct kiobuf *,
122 Учебно-исследовательская лаборатория «Информационные технологии»
Оперативная память (ОЗУ) является тем компонентом персональных компьютеров, важность которого, при современной архитектуре вычислительных систем, сложно переоценить, и без которого работа их (в силу архитектурных особенностей) не представляется возможной. Было бы интересно посмотреть, как именно ОС управляет доступной ей памятью? Как она распределяет её между загруженными приложениями? Как происходит организация (создание) в памяти нового процесса, как код программы получает управление и как процессу выделяется дополнительная память по запросу, в случае, когда выделенная изначально память заканчивается? Как организовано адресное пространство процесса? Подобные вопросы возникали и продолжают возникать у многих довольно часто, но далеко не на все из них находятся вразумительные ответы.
Поскольку круг вопросов, касающихся оперативной памяти настолько велик, что не может быть освещен в одной статье, здесь мы коснемся лишь части огромного механизма управления памяти в ОС Microsoft Windows, а именно изучим адресное пространство процесса, увидим, что же размещается [системой] в пространстве памяти, выделяемой процессу.
Память (общее определение) — физическое устройство или среда для хранения данных, используемая в вычислениях в течении определенного времени.
Код приложений (программ), исполняемый в произвольный момент времени на процессоре, оперирует данными. Данные, которые в текущий момент необходимы коду для выполнения, должны быть размещены в физической (оперативной) памяти или регистрах общего назначения. Если данные размещены в памяти, то их положение нужно каким-либо образом определить — проще всего сделать это при помощи некоего числа (порядкового номера), называемым адресом [в массиве]. Иными словами, оперативную память легче всего себе представить в виде массива байт. Чтобы обратиться к конкретному байту данных (массива), или адресовать его, логично было бы использовать порядковый номер. Подобным образом можно поступить со всеми байтами, пронумеровав их целыми положительными числами, установив ноль за начало отсчёта. Индекс байта в этом огромном массиве и будет его адресом.
Адресация на уровне процессора
В первых микропроцессорах компании Intel (архитектуры x86) был доступен единственный режим работы процессора, впоследствии названный реальным режимом. Адресация памяти в процессорах того времени была достаточно простой и носила название сегментной. Суть её заключалась в том, что ячейка памяти адресовалась при помощи двух составляющих: сегмент : смещение (сегмент — область адресного пространства фиксированного размера, смещение — адрес ячейки памяти относительно начала сегмента). Специфика архитектуры упомянутых [первых] микропроцессоров накладывала ограничения на размер физического адресного пространства (16 килобайт, 64 килобайта, 1 мегабайт…), и память, доступная программно, была не более размера оперативной (физически установленной) памяти компьютера. Это было просто, логично и понятно. Тем не менее, описанная архитектура имела ряд недостатков, к тому же в индустрии появились тенденции дальнейшего развития:
- Была актуальна проблема согласования выделения памяти различным приложениям. Размещение кода/данных приложений в едином для всех программ пространстве памяти требовало от операционной системы (а иногда и от самой программы) сложного механизма постоянного отслеживания занятого пространства.
- Наметился переход к многозадачным операционным системам, в которых большое количество задач должно было выполняться [псевдо]параллельно, что затрудняло использование общего пространства памяти.
- В условиях множества одновременно выполняющихся задач встала проблема безопасности, необходимости ограничения доступа к «чужим» процессам в памяти.
Эти, а так же некоторые другие, проблемы явились отправной точкой для работы над усовершенствованием, в следствии чего в процессоре 80286 появился защищенный режим и концепция сегментной адресации памяти была значительно расширена для обеспечения новых требований. Например в защищенном режиме сегменты могли располагаться (начинаться) в памяти в произвольном месте (база), иметь нефиксированный размер (лимит), уровни доступа, типы содержимого и прочее. И наконец, по прошествии некоторого времени была создана новая архитектура, получившая название IA-32, в которой были введены несколько новых моделей организации оперативной памяти:
- Базовая плоская модель (basic flat model) — наиболее простая модель памяти [системы], операционная система и приложения получают в своё распоряжение непрерывное, не сегментированное адресное пространство.
- Защищенная плоская модель (protected flat model) — более сложная модель памяти [системы], может применяться страничный механизм изоляции пользовательского/системного кода/данных, описываются четыре сегмента: кода/данных (для уровня привилегий 3, пользовательский уровень) и кода/данных (для уровня привелегий 0, ядро).
- Мульти-сегментная модель (multi-segment Model) — самая сложная модель памяти [системы], предоставляется аппаратная защита кода, данных, программ и задач. Каждой программе (или задаче) назначаются их собственные таблицы [сегментных] дескрипторов и собственные сегменты.
И главным завоеванием защищенного режима явилось появление механизма страничной организации/адресации памяти.
Страничная организация памяти это альтернативный тип управления памятью, разработанный для обеспечения организации виртуального адресного пространства (виртуальной памяти) в многозадачных операционных системах. В отличие от сегментной адресации, которая делила адресное пространство на сегменты определенной длины, страничная адресация делит пространство на множество страниц равного размера. Изменения коснулись и принципов адресации: если в реальном режиме работы процессора пара сегментный_регистр : смещение могла адресовать ячейку памяти, то в защищенном режиме сегмент был заменен на селектор, который содержал индекс в таблице дескрипторов и биты вида таблицы дескрипторов + биты привилегий.
Механизм трансляции адресов (преобразование адреса)
Поскольку одним из нововведений защищенного режима было создание виртуальной адресации, потребовались механизм трансляции виртуальных адресов в физические, а так же механизм трансляции страниц. Именно благодаря трансляции операционная система имеет возможность создавать для каждого процесса иллюзию полноразмерного обособленного адресного пространства и обеспечивать защиту собственного ядра [от пользовательских процессов]. Адрес, по которому код программы (процесса) пытается обратиться к данным (где-то в оперативной памяти), изначально закодирован в исполняемой инструкции (пример фрагмента кода):
|
. . . cmp [edi+ecx*4+4], esi . . . |
..и проходит через некоторое количество преобразований, начиная от декодирования инструкции процессором и заканчивая выставлением адреса на шину. Давайте посмотрим, какие же этапы проходит преобразование адреса:
- Эффективный адрес — адрес, задаваемый в аргументах машинной инструкции при помощи регистров, смещений, коэффициентов. Фактически эффективный адрес представляет собой смещение от начала сегмента (базы). Как раз для нашего примера (выше): эффективный адрес = EDI + ECX * 4 + 4;
- Логический адрес – адрес, представляющий собой пару
селектор: смещение. Традиционно селектор (левая часть) располагается в сегментном регистре, смещение (правая часть) в регистре общего назначения или указывается непосредственно, для нашего примера это:DS:[EDI+ECX*4+4]. Как мы видим, часто сегментный регистр (левая часть) не указывается (выбирается неявно). Фактически с логическими адресами и имеет дело программист в своих программах; - Линейный адрес — это 32-/64-разрядный адрес, получаемый путем использования селектора (содержащегося в левой части виртуального адреса, в сегментном регистре, для нашего примера задан неявно, в
DS) в качестве индекса в таблице дескрипторов (для вычисления базы сегмента) и добавления к ней смещения (правая часть виртуального адреса, в нашем случае значение, вычисляемое на основе выражения EDI+ECX*4+4). Линейный адрес = база сегмента + эффективный адрес. - Гостевой физический адрес — при использовании аппаратной виртуализации. В случае, когда в системе работают виртуальные машины, физические адреса (получаемые в каждой из них), необходимо транслировать ещё раз.
- Физический адрес — это финальная часть преобразований адреса внутри процессора. Физический адрес:
- (для сегментной адресации) полностью совпадает с линейным адресом;
- (для сегментно-страничной адресации) получается путем преобразования трех частей значения линейного адреса на основании: каталога страниц, таблицы страниц и смещения внутри страницы;
И наконец этот получившийся физический адрес выставляется на адресную шину процессора; может как совпадать с адресом ячейки оперативной памяти, так и не совпадать с ним;
Отсюда следует, что существуют логическое, линейное и физическое адресные пространства, которые активно взаимодействуют между собой, и на совокупности которых основана адресация в современных операционных системах. Фактически, процесс преобразования адресов, используемых программистом в своей программе в адрес физической ячейки оперативной памяти, является цепочкой преобразований от первого пункта к последнему и именуется трансляцией адресов (прозрачное преобразование одного вида адреса в другой).
Механизм трансляции страниц (страничное преобразование)
Алгоритмы преобразования линейного адреса в физический (этапы 3 → 5) варьируются в зависимости от множества причин (состояния определенных регистров). В некоторых режимах линейный адрес делится на несколько частей, при этом каждая часть является индексом в специализированной системной таблице (все они расположены в памяти), а число и размер описанных таблиц различаются в зависимости от режима работы процессора. Запись в таблице первого уровня представляет собой адрес начала таблицы следующего уровня, а для последнего уровня — информация о физическом адресе страницы в памяти и её свойствах. Иначе говоря:
Страничная память — способ организации виртуальной памяти, при котором виртуальные адреса отображаются на физические постранично.
Соответственно, на данном этапе, мы уже имеем дело уже с разбиением адресного пространства на страницы (определенного размера) или со страничной организацией памяти. Иными словами, мы имеем дело с виртуальной памятью. Процессор как бы делит линейное адресное пространство на блоки (страницы) фиксированного размера (в зависимости от установок — 4Кб, 2Мб, 4Мб), которые уже могут отображаются в физической памяти или на жестком диске. И вот тут стоит обратить внимание на один крайне важный аппаратный механизм:
В произвольный момент времени та или иная страница может «находиться» (быть сопоставлена) в физической памяти, а может и не находиться в ней.
Иными словами, преобразование линейного адреса в физический может закончиться неудачей, если:
- страницы в данный момент нет в физической памяти;
- таблицы не содержат необходимых данных;
- недостаточно прав доступа;
Во всех этих случаях возникает аппаратное событие — так называемое исключение Page Fault (#PF), которое предписывает обработчику исключения произвести дополнительные действия по устранению возникшей проблемы: подгрузить (отсутствующую) страницу с диска (либо скинуть (ненужную) страницу на диск). Как только страница была подгружена, то выполнение прерванного кода продолжится с инструкции, которая вызвала #PF. Именно механизм страничной адресации (преобразования) и позволяет операционной системе организовать виртуальное адресное пространство, о котором речь пойдет далее. К сожалению, подробное описание механизмов преобразования адресов и типов адресации выходит за рамки данной статьи, далее мы переходим к «программному» уровню, то есть непосредственно к механизмам операционной системы.
Адресация на уровне ОС
Сами понимаете, что было бы не совсем корректно называть излагаемое в данной главе некоей «программной» частью адресации в операционной системе, поскольку:
Механизмы, используемые операционными системами, имеют аппаратную поддержку на уровне процессора.
..поэтому операционная система Windows эксплуатирует особенности той архитектуры, на которой она в данный момент функционирует (выполняется) и всего-лишь использует аппаратные механизмы [процессора]. Становится очевидным, что если Windows исполняется на станциях, построенных на базе процессоров архитектуры IA-32, то используется защищенный режим работы процессора. Версии операционной системы Windows для архитектуры IA-32, пользуются механизмом сегментации защищенного режима лишь в минимальном объёме:
- используются всего два уровня привилегий: 0 и 3;
- и из всех доступных способов организации памяти используется защищенная плоская модель со страничной адресацией (protected flat model);
Защищенная плоская модель в Windows имеет свои особенности: память представляется программе [задаче] в виде единого непрерывного адресного пространства (линейное адресное пространство). Код, данные и стек — всё содержатся в этом адресном пространстве, то есть объединены в один физический сегмент.
Есть соглашение, что все селекторы для процесса идентичны, это значит что адресация внутри процесса фактически базируется на смещении (а селекторы сегментов остаются неизменными). Исходя из этого, если каждый процесс [в системе] использует собственное адресное пространство линейным способом, то есть адресация базируется (фактически) на смещении, селекторы сегментов остаются неизменными, то сегментные регистры не нужны и их можно «опустить», «упразднить». На основе плоской модели памяти базируется часто упоминаемый в литературе механизм виртуальной памяти.
Виртуальная память – стратегия организации памяти [операционной системой], основанная на идее создания единого виртуального адресного [псевдо]пространства, состоящего из физической памяти (ОЗУ) и дисковой памяти (жесткий/твердотельный диск).
Возникает вопрос: почему это пространство называется виртуальным? А потому что виртуальный адрес может и не присутствовать в физической памяти, все механизмы [защищенного режима] созданы лишь для имитации (создания иллюзии для программы) его существования, ведь используются селекторы:смещения (которые могут ссылаться на любой адрес) совместно со страничным преобразованием (страницы могут быть сопоставлены с физической памятью, а могут и не быть), то есть все сущности по сути эфемерны, пользователь не знает как и где они размещены!!
Размерность адресных пространств
Не случайно во множественном числе, поскольку и эта тема несет в себе огромное количество неопределенностей и неточностей. Выше мы говорили о том, что существуют логическое, линейное и физическое адресные пространства в архитектуре процессора.
Физическое адресное пространство
Итак, размерность физического (процессорного) адресного пространства зависит от особенностей аппаратной архитектуры:
- 32-бита: используются 32-битные указатели (размерность 4 байта), и размер адресного пространства равен 232 = 4294967296 байт (4 гигабайта, Гб). Шестнадцатеричное представление диапазона: 00000000 — FFFFFFFF.
- 64-бита: используются 64-битные указатели (размерность 8 байт) и размер адресного пространства процесса равен 264 = 18446744073709551616 байт (16 экзабайт, Эб. ~17 миллиардов гигабайт). Шестнадцатеричное представление диапазона: 0000000000000000 — FFFFFFFFFFFFFFFF.
| Разрядность (битность) приложения | Разрядность указателя | Размер адресного пространства [процесса] | Адреса диапазона (шестнадцатеричные) |
|---|---|---|---|
| 32 бита | 32 бита (4 байта) | 232 (4294967296 байт = 4 гигабайта) | 00000000 — FFFFFFFF |
| 64 бита | 64 бита (8 байт) | 264 (18446744073709551616 байт = ~17 миллиардов гигабайт = 16 экзабайт) | 0000000000000000 — FFFFFFFFFFFFFFFF |
Но это, опять же, теоретическая адресация на основе разрядности.
Линейное адресное пространство
Линейное адресное пространство процесса теоретически могло бы быть идентично физическому адресному пространству, но на практике вступают в действие ограничения операционной системы, которые зависят от: версии операционной системы, [определенных] настроек (флагов) операционной системы и приложений, типа запуска: 32-битное приложение на 32-битной ОС, 32-битное приложение на 64-битной ОС, 64-битное на 64-битной ОС.
- 32-бита: размер линейного адресного пространства процесса равен 4Гб, верхние 2Гб (или 1Гб, в зависимости от флагов) из которых защищены на уровне страниц. Поэтому для пользовательского приложения в 32-битной ОС определен лимит в 2Гб (или 3, в зависимости от флагов), за пределы которого процесс выбраться не может (без использования специализированных технологий вида AWE).
- 64-бита: размер линейного адресного пространства процесса равен 16Тб или 256Тб, из которых (верхняя) часть защищена на уровне страниц. Поэтому 32/64-битному пользовательским приложениям может быть определен лимит в 2Гб, 4Гб, 8Тб и 128Тб (в зависимости от разрядности/версии/флагов).
Виртуальные адреса используются приложениями, однако сама операционная система (равно как и процессор) не способна по этим виртуальным адресам непосредственно обращаться к данным, потому как виртуальные адреса не являются адресами физического устройства хранения информации (ОЗУ/ДИСК), другими словами физически по этим адресам информация не хранится.
Для того, чтобы код, располагающийся по виртуальным адресам можно было выполнить, эти адреса должны быть отображены на физические адреса, по которым действительно могут храниться код и данные. Это особенности аппаратной архитектуры x86 (проще: так устроен центральный процессор).
Или, если выразиться иначе, выполняемый код или используемые данные должны находиться в физической памяти, только в этом случае они будут выполнены/обработаны процессором.
Еще раз: код и данные, которые в данный момент обрабатываются/исполняются, физически располагаются в ОЗУ.
Использование страничной организации операционной системой
Получается интересная ситуация: с одной стороны, для каждого процесса в операционной системе Windows выделяется адресное пространство, которое фактически эквивалентно размерности теоретического адресного пространства; с другой стороны размер физически установленной оперативной памяти (ОЗУ) компьютера может быть в разы меньше суммы всех адресных пространств процессов, исполняемых в данный момент в системе. Как нам в подобной ситуации обеспечить нормальное функционирование операционной системы? А очень просто, поскольку:
- виртуальные адреса суть иллюзия, они могут не ссылаться на физическую память;
- [в подавляющем большинстве случаев] процесс не использует всё виртуальное адресное пространство, отведенное для него; то есть адресное пространство процесса не обязательно заполнено [под завязку] данными;
- общие для всех процессов данные могут разделяться множеством процессов (экономия оперативной памяти);
- не обязательно код и данные всех процессов [постоянно] держать в ОЗУ (экономия оперативной памяти);
И в обеспечении всех этих механизмов нам на помощь приходит страничная организация (о которой говорилось выше): она позволяет операционной системе прозрачно (незаметно) для пользователя/приложения выполнять ряд очень нужных системе манипуляций:
- подгружать/выгружать неиспользуемые страницы с/на носитель информации (жесткий диск: HDD, SSD);
- проецировать общие страницы [общих ключевых библиотек] в несколько адресных пространств одновременно;
Страницы, которые в определенный промежуток времени не используются, из ОЗУ переносятся (перепроецируются) на любой физический носитель, установленный в системе — в файл (файл подкачки, страничный файл, page file, swap-файл, «своп») либо [в некоторых ОС] в область подкачки (специализированный раздел).
Сопоставлением (отображением) виртуальных адресов на физические адреса ОЗУ или файла подкачки занимается так называемый диспетчер виртуальной памяти (VMM, Virtual Memory Manager).
Диспетчер виртуальной памяти (Virtual memory manager, Kernel-mode memory manager) — модуль ядра ОС Windows, предназначающийся для организации подсистемы виртуальной памяти: создания таблицы адресов для процессов, организации общего доступа к памяти, осуществления защиты на уровне страниц, поддержки возможность отображения файлов на память, распределения физической памяти между процессами, организации выгрузки/загрузки страниц между физической памятью и файлом подкачки, обеспечения всех процессов достаточным для функционирования объемом физической памяти.
Упрощенная схема процесса «отображения» выглядит следующим образом:

Схема действительно упрощена, поскольку на деле в процессе сопоставления участвует множество структур: таблица указателей на каталог страниц, каталог страниц, таблица страниц. Как видно из нашего рисунка, виртуальные адреса могут проецироваться на физическую намять, файл подкачки или любой файл, располагающийся в файловой системе. На основе приведенной схемы мы может сделать довольно-таки важный вывод:
Виртуальное адресное пространство создается для каждого процесса, работающего в операционной в системе и напрямую не связано с адресацией физической памяти (ОЗУ).
и теперь вы, надеюсь, понимаете, что:
Виртуальный адрес может быть просто не сопоставлен с физической памятью!!
Получается, что у виртуальных страниц адреса одни, аппаратные страницы выделяются по мере необходимости из имеющихся в наличии свободных страниц физической памяти, и, понятное дело, что физические адреса будут случайными и, в большинстве случаев, не будут совпадать с виртуальными. Напомню, что синхронизация между виртуальными и физическими страницами памяти обеспечивается аппаратно (на уровне процессора), называется страничным преобразованием и была нами описана выше. Наиболее значимые особенности виртуальной памяти таковы:
- Виртуальная память, доступная программе, напрямую не связана с физической памятью.
- Каждая программа работает в своей виртуальном адресном пространстве. Размер этого пространства может быть больше размера фактически установленной в машине оперативной памяти.
- Адресное пространство [каждого] процесса (программы), исполняющегося в ОС, изолировано [от подобных адресных пространств других процессов].
Когда какая-либо программа обращается к своим данным, которые [в этот момент] отсутствуют в ОЗУ, то функция обработчика страничного нарушения диспетчера виртуальной памяти производит следующие манипуляции:
- сохраняет в стек адрес инструкции, следующей за инструкцией, вызвавшей #PF;
- производит поиск свободной (незанятой) физической страницы;
- создает новый элемент в таблице страниц;
- подгружает недостающие данные из файла подкачки в ОЗУ;
- производит проецирование виртуальной страницы на физическую;
- производит восстановление адреса из стека и выполняет «перезапуск» инструкции (следующей за той, на которой было прервано выполнение);
Все эти процессы происходят на уровне ядра операционной системы, поэтому они «прозрачны» или «неразличимы» для пользовательского приложения (а программисту, в реалиях высокоуровневого программирования, зачастую и вовсе не интересны).
Теперь несколько слов об изоляции или закрытости [адресного пространства] процесса. Виртуальное пространство [каждого] процесса изолировано, или, можно сказать по-другому — процессы отделены друг от друга в своем собственном виртуальном адресном пространстве. Поэтому любой поток в рамках некоего процесса получает доступ только лишь к той памяти, которая принадлежит родительскому процессу. Наглядно, изолированность выражается в том, что некая программа A в своем адресном пространстве может хранить запись данных по условному адресу 12345678h, и в то же время у программы B по абсолютно тому же адресу 12345678h (но уже в его собственном адресном пространстве) могут находиться совершенно другие данные. Изолированность, к тому же подразумевает, что код одной программы (если быть точным, то потока в рамках процесса) не может получить доступ к памяти другой программы (без дополнительных манипуляций). Достоинства виртуальной памяти:
- Упрощается программирование. Программисту больше не нужно учитывать ограниченность памяти, или согласовывать использование памяти с другими приложениями.
- Повышается безопасность. Адресное пространство процесса изолировано.
- Однородность массива. Адресное пространство линейно.
[пример] Виртуальное адресное пространство процесса
Я думаю, после некоторого количества теоретических выкладок, самое время перейти ближе к рассмотрению основной темы статьи. Напомню, что мы будем исследовать структуру памяти 32-битного процесса Windows. Для исследования памяти процесса нам потребуется специализированное программное средство, которое поможет нам увидеть адресное пространство процесса в деталях. Использовать мы будем утилиту VMMap от Марка Руссиновича, отличное приложение, которое выводит подробную информацию по использованию памяти в рамках того или иного процесса. Однако, не обошлось, что называется, и без ложки дегтя. Бытует мнение, что данное ПО отражает карту процесса не достаточно подробно, игнорируя кое-какие структуры памяти, однако, как отправная точка для понимания принципов размещения объектов в памяти вполне нас устроит.
Для практического эксперимента я буду использовать самописный модуль test2.exe, написанный на ассемблере, код которого предельно прост, отображает всего-лишь некоторые оконные элементы и выводит информационное окно перед выходом. В модуле используются (импортируются) функции SetFocus, SendMessageA, MessageBoxA, CreateWindowExA, DefWindowProcA, DispatchMessageA, ExitProcess, GetMessageA, GetModuleHandleA, LoadCursorA, LoadIconA, PostQuitMessage, RegisterClassA, ShowWindow, TranslateMessage, UpdateWindow из библиотек user32.dll и kernel32.dll. Итак, запускаем на исполнение тестовый файл test2.exe а затем, пока приложение исполняется, загружаем программу VMMap, указывая ей открыть наш целевой процесс. Вот что мы наблюдаем:

Поскольку информации довольно много, к карте процесса потребуется небольшое пояснение. И хотя это и не статья, описывающая функционал утилиты VMMap, однако мы должны осветить некоторые ключевые моменты, потому как без знаний о заголовках столбцов и видах типов регионов мы в изучении далеко не продвинемся.
| Наименование столбца | Описание |
|---|---|
| Address | Стартовый адрес региона в виртуальном пространстве процесса. Шестнадцатеричное представление. |
| Type | Тип региона (см. таблицу далее). |
| Size | Полный размер выделенной области. Отражает максимальный размер физической памяти, которая необходима для хранения региона. Так же включает зарезервированные области. |
| Committed | Количество памяти региона, которое «отдано», «передано» или «зафиксировано» — то есть эта память уже связана с ОЗУ, страничным файлом [подкачки], или с отображенным файлом (mapped file) [на диске]. |
| Private | Часть всей памяти, выделенной для региона, которая приватна, то есть принадлежит исключительно процессу-владельцу и не может быть разделена с другими процессами. |
| Total WS | Общее количество физической памяти, выделенной для региона (ОЗУ + файл подкачки). |
| Private WS | Приватная часть физической памяти [региона/файла]. Принадлежит исключительно владельцу и не может быть разделена (использована совместно) с другими процессами. |
| Shareable WS | Общедоступная часть физической памяти [региона/файла]. Может быть использована совместно другими процессами, которым так же необходим данный регион (файл). |
| Shared WS | Общедоступная часть физической памяти [региона/файла]. Уже используется совместно с другими процессами. |
| Locked WS | Часть физической памяти [региона/файла], которая гарантированно находится в ОЗУ и не вызывает ошибок страниц (необходимость подгрузки из файла подкачки), когда к ней пытаются получить доступ. |
| Blocks | Количество выделенных в регионе блоков памяти. Блок — неразрывная группа страниц с идентичными атрибутами защиты, сопоставленная с одним регионом физической памяти. Если Вы посмотрите внимательно то заметите, что значения параметра «Blocks», отличные от нуля, встречаются в регионах, которые разбиты на несколько частей (подрегионы, блоки). Обычно имеется несколько подрегионов: основной регион + резервные. |
| Protection | Типы операций, которые могут быть применены к региону. Для регионов, которые подразделяются на подблоки (+), колонка указывает общую (сводную) информацию по типам защиты в подблоках. В случае применения к региону неразрешенного типа операций, возникает «Ошибка доступа». Ошибка доступа происходит в случаях: когда происходит попытка запустить код из региона, который не помечен как исполняемый (если DEP включена), или при попытке записи в регион, который не помечен как предназначенный для записи или для «копирования-при-записи» (copy-on-write), или в случае попытки доступа к региону, который маркирован как «нет доступа» или просто зарезервирован, но не подтвержден. Атрибуты защиты присваиваются регионам виртуальной памяти на основе атрибутов сопоставленных регионов физической памяти. |
| Details | Дополнительная информация по региону. Тут могут отображаться: путь файла бэкапа, идентификатор кучи (для региона heap), идентификатор потока (для стека), указатель на .NET-домен и прочее. |
WS (Working Set) — так называемый рабочий набор, то есть множество (массив) страниц физической памяти (ОЗУ), уже выделенных для процесса и использующихся для фактического хранения кода/данных. Когда требуется доступ к каким-либо адресам виртуальной памяти, фактически с этими адресами должна быть связана физическая память (потому что операции чтения/записи/выполнения могут производиться только с физической памятью). Поэтому, когда с данными адресами будет сопоставлена физическая память, она добавляется как раз к рабочему набору процесса (working set).
Ну и необходимо описать все виды типов (type) регионов. Типы регионов у можно наблюдать на карте процесса в столбце Type:
| Тип региона | Описание |
|---|---|
| Free | Диапазон виртуальных адресов не сопоставленных с физической памятью. Это память, которая еще не занята. Регион или часть региона доступны для резервирования (выделения). |
| Shareable | Регион, который может быть разделен с другими процессами и забекаплен в физической памяти либо файле подкачки. Подобные регионы обычно содержат данные, которые разделены между процессами, то есть используются несколькими программами, через общие, специально оформленные, секции DLL или другие объекты. |
| Private Data | Частные данные. Это регион, выделенный через функцию VirtualAlloc. Эта часть памяти не управляется менеджером кучи (Heap Manager), функциями .NET и не выделяется стеку. Обычно содержит данные приложения, которые используются только нашей программой и не доступны другим процессам. Так же содержит локальные структуры процесса/потока, такие как PEB или TEB. Типичная «память программы». Регион сопоставлен со страничным файлом. |
| Unusable | Виртуальная память, которая не может быть использована из-за фрагментации. Это осколки, которые уже закреплены за регионом. Гранулярность выделения памяти в Windows — регионы по 64Кб. Когда Вы пытаетесь выделить память с помощью функции VirtualAlloc и запрашиваете, к примеру 8 килобайт, VirtualAlloc возвращает адрес региона в 64 килобайта. Оставшиеся 56Кб помечаются как неиспользуемые (unusable). Обратите внимание на то, что области Unusable «следуют» в карте за не кратными 64Кб регионами, на самом же деле, это всего-лишь память, которая входит в регион (принадлежит региону-владельцу), но на данный момент не используется. |
| Image | Регион сопоставлен с образом исполняемого EXE- или DLL-файла, проецируемого в память. Это именно тот регион, куда загружается образ пользовательского приложения со всеми его секциями (в нашем случае test2.exe). |
| Image (ASLR) | Образы системных библиотек, загружаемые с использованием механизма безопасности ОС под названием ASLR (Address Space Layout Randomization). ASLR — рандомизация расположения в адресном пространстве процесса таких структур как: образ исполняемого файла, подгружаемая библиотека, куча и стек. Вкратце, ОС игнорирует предпочитаемый базовый адрес загрузки, который задан в заголовке PE и загружает библиотеку в адрес по выбору «менеджера загрузки». Для поддержки ASLR, библиотека должна быть скомпилирована со специализированной опцией, либо без неё, когда используется принудительная рандомизация (ForceASLR). Таким образом, усиливается безопасность процесса и исключаются конфликты базовых адресов образов [подгружаемых модулей]. Применяется начиная с Windows Vista. Технология так же известна под псевдонимом Rebasing. |
| Thread Stack | Стек. Регион сопоставлен со стеком потока. Каждый поток имеет свой собственный стек, соответственно под каждый поток выделяется регион для хранения его собственного стека. Когда в процессе создается новый поток, система резервирует регион адресного пространства для стека потока. Для чего обычно используется стек? Ну как и все стеки, стек потока предназначается для хранения локальных переменных, содержимого регистров и адресов возврата из функций. |
| Mapped File | Проецируемые файлы. Это немного не то же, что «проецирование» образа самой программы и необходимых библиотек. Все отображаемые в адресное пространство процесса файлы могут быть трех видов: самой программой, библиотеками, и рабочими объектами. Проецируемые (mapped) файлы это и есть вот эти самые рабочие объекты, которые может создавать и использовать код программы. Обычно это файлы, которые содержат какие-либо требующиеся приложению данные и с которыми приложение работает напрямую. Проецирование файлов — наиболее удобный способ обработки внешних данных, поскольку данные из файла становятся доступны непосредственно в адресном пространстве процесса (регион памяти сопоставлен с файлом или частью файла), а на самом деле они размещаются на диске. Таким образом программе файл доступен в виде большого массива, нет необходимости писать собственный код загрузки файла в память, на лицо экономия на операциях ввода-вывода и операциях с блоками памяти. ОС делает всё это прозрачно для разработчика, собственными механизмами, получается для кода область проецируемых файлов — это обычная память. Проецируемые файлы предназначены для операций с файлами из кода основной программы, ведь рано или поздно подобные операции с файлами приходится использовать практически во всех проектах, и зачастую это влечет за собой большое количество дополнительной работы, поскольку пользовательское приложение должно уметь работать с файлами: открывать, считывать и закрывать файлы, переписывать фрагменты файла в буфер и оттуда в другую область файла. В Windows все подобные проблемы решаются как раз при помощи проецируемых в память файлов (memory-mapped files). Проецируемый в память файл может иметь имя и быть разделяемым, то есть совместно использоваться несколькими приложениями. Работа с проецируемыми файлами в пользовательском режиме обеспечивается функциями CreateFileMapping и MapViewOfFile. |
| Heap (Private Data) | Куча. Это регион зарезервированного адресного пространства процесса, предназначенный для динамического распределения небольших областей памяти. Представляет из себя закрытую область памяти, которая управляется так называемым «Менеджером кучи» (Heap Manager). Данные в этой области хранятся «в куче» (или «свалены в кучу»), то есть друг за другом, разнородные, без какой-либо систематизации. Смысл кучи сводится к обработке множества запросов на создание/уничтожение множества мелких объектов (блоков памяти). Куча используется различными функциями WinAPI, вызываемыми кодом Вашего приложения, либо функциями самого приложения, для выделения различных временных буферов хранения строк, переменных, структур, объектов. Память в куче выделяется участками (индексами), которые имеют фиксированный размер (8 байт). |
Как Вы видите из карты процесса, всё адресное пространство процесса разбито на множество неких зон различного назначения, называемых регионами. Регионов в адресном пространстве достаточно много. Однако, для начала, давайте посмотрим на «общее» разбиение адресного пространства процесса, дабы возникло понимание, как что и где может размещаться. Разбиение адресного пространства в определенной степени зависит от версии ядра Windows.
Общая концепция разбиения виртуального адресного пространства 32-битных программ:
| Начало | Конец | Размер | Описание |
|---|---|---|---|
| 00000000 | 0000FFFF | 64Кб | Область нулевых указателей. Зарезервировано. Данная область всегда маркируется как свободная (Free). Попытка доступа к памяти по этим адресам вызывает генерацию исключения нарушения доступа STATUS_ACCESS_VIOLATION. Область применяется для выявления программистами некорректных, нулевых указателей, тем самым позволяя выявлять некорректно работающий код. Если по каким-то причинам (напр.: возврат значения функцией) переменная или регистр вдруг принимает нулевое (неинициализированное) значение, то дальнейшая попытка обращения к памяти (запись/чтение) с использованием данной переменной/регистра приведет к генерации исключения (напр.: mov eax, dword ptr [esi], где ESI=0). |
| 00010000 | 7FFEFFFF | 2Гб (3Гб) | Пользовательский режим (User mode). Пользовательская часть кода и данных. В это пространство загружается пользовательское приложение, с разбивкой по секциям. Отображаются все проецируемые в память файлы, доступные данному процессу. В этом пространстве создаются пользовательская часть стеков потоков приложения. Тут присутствуют основные системные библиотеки ntdll.dll, kernel32.dll, user32.dll, gdi32.dll. |
| 7FFF0000 | 7FFFFFFF | 64Кб | Область некорректных указателей. Зарезервировано. Данная область всегда маркируется как свободная (Free). Попытка доступа к памяти по этим адресам вызывает генерацию исключения нарушения доступа STATUS_ACCESS_VIOLATION. Хотя эта область формально и относится к области памяти пользовательского режима, она является «пограничной», то есть имеется риск при операциях с большими блоками памяти выйти за границы пользовательского режима и перезаписать данные режима ядра, поэтому Microsoft предпочла заблокировать доступ к данной области. Область применяется для выявления некорректных (вышедших за пределы пользовательской памяти) указателей (переменные/регистры) в коде (например: mov eax, dword ptr [esi], где ESI=значение, входящее в диапазон 7FFF0000-7FFFFFFF). |
| 80000000 | FFFFFFFF | 2Гб (1Гб) | Режим ядра (Kernel mode). Код и данные модулей ядра, код драйверов устройств, код низкоуровневого управления потоками, памятью, файловой системой, сетевой подсистемой. Размещается кеш буферов ввода/вывода, области памяти, не сбрасываемые в файл подкачки. Таблицы, используемые для контроля страниц памяти процесса (PTE?). В этом пространстве создаются ядерная часть стеков для каждого потока в каждом процессе. Пространство недоступно из пользовательского режима, и попытка обращения из кода режима пользователя приведет к исключению нарушения доступа. Пространство «общее», то есть идентично (одинаково) для всех процессов системы. |
Ну, регионы мы бегло рассмотрели, давайте разберемся, как же происходит построение адресного пространства для конкретного процесса? Ведь должен существовать в системе механизм выделения и заполнения регионов. Все начинается с того, что пользователь либо некий код инициируют выполнение исполняемого модуля (программы). Одни из примеров подобного действия может быть двойной щелчок в проводнике по имени исполняемого файла. В этом случае код инициирующего выполнение потока вызывает функцию CreateProcess либо родственную из набора функций, предназначающихся для создания нового процесса. Какие же действия выполняет ядро после вызова данной функции:
- Находит исполняемый файл (.exe), указанный в параметре функции CreateProcess. В случае каких проблем просто возвращает управление со статусом false.
- Создает новый объект ядра «процесс».
- Создает адресное пространство процесса.
- Во вновь созданном адресном пространстве резервирует регион (набор страниц). Размер региона выбирается с расчетом, чтобы в него мог уместиться исполняемый .exe-файл. Загрузчик образа смотрит на параметр заголовка .exe-файла, который указывает желательное расположение (адрес) этого региона. По-умолчанию =
00400000, однако может быть изменен при компиляции. - Отмечает, что физическая память, связанная с зарезервированным регионом это сам .exe-файл на диске.
- После окончания процесс проекции .exe-файла на адресное пространство процесса, система анализирует секцию import directory table, в которой представлен список DLL-библиотек (которые содержат функции необходимые коду исполняемого файла) и список самих функций.
- Для каждой найденной DLL-библиотеки производится «отображение», то есть вызывается функция LoadLibrary, которая выполняет следующие действия:
- Резервирует регион в адресном пространстве процесса. Размер выбирается таковым, чтобы в регион мог поместиться загружаемый DLL-файл. Желаемый адрес загрузки DLL указывается в заголовке. Если размер региона по желаемому адрес меньше размера загружаемого DLL, либо регион занят, ядро пытается найти другой регион.
- Отмечает, что физическая память, связанная с зарезервированным регионом это DLL-файл на диске.
- Производится настройка образа библиотеки, сопоставление функций. Результатом этого является заполненная таблица (массив) адресов импортируемых функций, чтобы в процессе работы код обращается к своему массиву для определения точки входа в необходимую функцию.
Очевидно, что в момент создания процесса, адресное пространство практически все свободно (незарезервировано). Поэтому, для того, что бы воспользоваться какой-либо частью адресного пространства, надо эту самую часть для начала выделить (зарезервировать) посредством специализированных функций.
Резервирование (reserving) — операция выделения региона (выделения блока памяти по те или иные нужды).
Резервирование региона происходит вместе с выравниванием начала региона с учетом так называемой гранулярности (зависит от процессора, 64Кб). При резервировании обеспечивается дополнительно еще и кратность размера региона размеру страницы (зависит от процессора, 4Кб), поэтому если вы пытаетесь зарезервировать регион некратной величины, система округлит значение до ближайшей большей кратной величины.
Страница (page) — минимальная единица [объема памяти], используемая системой при управлении памятью (как мы и писали выше).
Размещение в адресном пространстве структур и библиотек
Далее по тексту я буду приводить описание непосредственно регионов памяти, делая цветовую маркировку для удобства сопоставления типа региона фактически размещаемым данным.
| Адрес | Модуль | Описание | ||||||
|---|---|---|---|---|---|---|---|---|
| 00040000 | apisetschema.dll | Предназначена для организации и разделения на уровни выполнения огромного количества функций базовых DLL системы. Подобная технология была названа «Наборами API» (API Sets), появилась в Windows 7 и предназначалась для группировки всех [многочисленных] функций в 34 различных типа и уровня выполнения, с целью предотвратить циклические зависимости между модулями и минимизировать проблемы с производительностью, которые обусловлены обеспечением зависимости новых DLL от набора Win32 API в адресном пространстве процесса. Перенаправляет вызовы, адресованные базовым DLL к их новым копиям, разделенным на уровни. | ||||||
| 00050000 | Стек потока | [64-битный] стек потока. | ||||||
| 00090000 | Стек потока. | Одномерный массив элементов с упорядоченными адресами (организованный по принципу «последний пришел — первым ушел» (LIFO)), предназначенный для хранения небольших объемов данных фиксированного размера (слово/двойное слово/четверное слово): стековых фреймов, передаваемых в функцию аргументов, локальных переменных функций, временно сохраняемых значений регистров. Для каждого потока выделяется собственный (отдельный) стек. Каждый раз при создании нового потока в контексте процесса, система резервирует регион адресного пространства для стека потока и передает данному региону определенный объем [физической] памяти. Для стека система резервирует 1024Кб (1Мб) адресного пространства и передает ему всего две страницы (2х8Кб?) памяти. Но перед фактическим выполнением потока система устанавливает указатель стека на конец верхней страницы региона стека, это именно та страница, с которой поток начнет использовать свой стек. Вторая страница сверху называется сторожевой (guard page). Как только активная страница «переполняется», поток вынужден обратиться к следующей (сторожевой) странице. В этом случае система уведомляется о данном факте и передает память еще одной странице, расположенной непосредственно за сторожевой. После чего флаг PAGE_GUARD переходит к странице, которой только что была передана память. Благодаря описанному механизму объем памяти стека увеличивается исключительно по мере необходимости. | ||||||
| 00280000 | msctf.dll.mui | Файл локализации библиотеки msctf.dll, описанной ниже. В общем смысле представляет собой переведенные на русский язык текстовые строки/константы, используемые библиотекой. | ||||||
| 00400000 | test2.exe | Собственно образ нашей программы. Отображается в виртуальном адресном пространстве благодаря системному механизму проецирования файлов. Исполняемый .exe-файл проецируется на адресное пространство программы по определенным адресам и становится его частью. Проецирование состоит в том, что данные [из файла] не копируются в память, а как бы связываются с данными на физическом носителе, то есть любое обращение к памяти по этим адресам инициирует чтение данных с диска, память как бы «читается» из файла на диске. Виртуальный адрес 00400000 является «предпочитаемой базой образа» (Image base), константой, которую можно изменять при компиляции. По традиции, никто этим не заморачивается, и, в большинстве случаев, данный адрес актуален для подавляющего большинства программ (но встречаются и исключения).
Не путайте «базу образа» (image base) с «точкой входа» (entry point). Вторая представляет из себя адрес, с которого начинается исполнение кода программы. Обычно лежит по некоторому смещению относительно «базы образа». Образ исполняемого файла (test2.exe) содержит в себе секции. Данный факт можно подтвердить, раскрыв (+) содержимое образа. Объясняется это тем, что exe-файл состоит из множества частей: непосредственно секция кода, секция данных, секция ресурсов, констант. Все эти секции загрузчик размещает по собственным областям памяти и назначает различные атрибуты доступа. |
||||||
| 00410000 | locale.nls | NLS предоставляет поддержку местной раскладки клавиатуры и шрифтов. NLS позволяет приложениям устанавливать локаль для пользователя и получать (отображать) местные значения времени, даты, и других величин, отображаемых в формате региональных настроек. | ||||||
| 01F80000 | SoftDefault.nls | |||||||
| 02250000 | StaticCache.dat | |||||||
| 735A0000 | uxtheme.dll | Тема оформления. Функционал библиотеки позволяет менять визуальное представление интерфейса (вид многочисленных элементов управления) программ без необходимости менять базовый (в ядре) функционал операционной системы. | ||||||
| 73A30000 | comctl.dll | Библиотека реализует готовые элементы управления (контролы), которые используются в графическом интерфейсе. | ||||||
| 74B20000 | dwmapi.dll | Интерфейс диспетчера окон рабочего стола (DWM, Desktop Windows Manager). DWM — графический интерфейс рабочего стола, использующийся в Windows Aero. Управляет объединением различных выполняющихся и визулизируемых окон с рабочим столом. В своей программе я никаких специфических функций Windows Aero не использую, но, могу предположить, что образ библиотеки dwmapi.dll отображается на адресное пространство процесса по причине включенного на уровне системы интерфейса Aero. | ||||||
| 751F0000 75250000 752D0000 | wow64win.dll wow64.dll wow64cpu.dll | В адресном пространстве процесса по данным адресам находятся библиотеки DLL пользовательского режима, отвечающие за работу подсистемы Wow64. Они появились в нашем адресном пространстве не случайно, поскольку, напомню, что наш 32-разрядный процесс test2.exe запущен в 64-разрядной ОС Windows 7 Professional.
Wow64 (Windows 32-bit on Windows 64-bit) — эмуляция Win32 приложений на 64-разрядной ОС Windows. Представляет из себя программную среду, позволяющую исполнять 32-разрядные приложения на 64-разрядной версии Windows. Механизм используется в 64-разрядных версиях Windows в виде набора библиотек DLL пользовательского режима. Помимо данных библиотек в 64-разрядной версии ОС присутствует поддержка со стороны ядра (изменение контекста). Перехватывает системные вызовы 32-битных версий ntdll.dll и user32.dll, поступающих от 32-битных приложений и транслирует их в 64-битные вызовы ядра. С помощью Wow64 создаются 32-разрядные версии структур данных для процесса, например
|
||||||
| 75500000 | msctf.dll | Библиотека расширяет функционал, предоставляемый службами Microsoft для работы с текстом (Microsoft Text Services). Среди функций библиотеки имеются функции усовершенствованной текстовой обработки и ввода текста. Функционал библиотеки msctf.dll предоставляет двунаправленный обмен между приложением и службами работы с текстом. Предоставляет поддержку различных языков. | ||||||
| 75810000 | msvcrt.dll | Microsoft Visual C++ Runtime. Библиотека времени выполнения языка C, обеспечивающая вспомогательные функций для работы с памятью, устройствами ввода/вывода, математическими функциями. Довольно много прототипов функций, используемых в языках C/C++ содержится в данной библиотеке. | ||||||
| 758C0000 | gdi32.dll | Одна из четырех основных библиотек поддержки Win32 API. Часть интерфейса графического устройства (GDI, Graphics Device Interface) или интерфейса между приложениями и графическими драйверами видеокарты, работающая в режиме пользователя. Содержит функции и методы для представления графических объектов и вывода их на устройство отображения, отвечает за отрисовку линий, кривых, обработку палитры и управление шрифтами, можно сказать полностью отвечает на графику. Приложения посылают запросы коду GDI, работающему в режиме пользователя, который пересылает их GDI режима ядра, а тот уже перенаправляет данные запросы драйверам графического адаптера. Моя программа [напрямую] не импортирует функции из gdi32.dll напрямую, однако библиотека проецируется в адресное пространство любого процесса, использующего оконный интерфейс. | ||||||
| 75A80000 | advapi32.dll | Одна из четырех основных библиотек поддержки Win32 API. Содержит большое количество часто востребованных функций: работа с реестром, сервисами, выключение (перезагрузка) ПК, и прч. В системе присутствует огромное количество библиотек, которые статически слинкованы с библиотекой advapi32.dll. Поэтому, без проецирования её в адресное пространство процесса никак не обойтись. | ||||||
| 76С00000 | kernel32.dll | Одна из четырех основных библиотек поддержки Win32 API. В библиотеке содержатся основные подпрограммы для поддержки работы подсистемы Win32. Много ключевых процедур и функций, которые используются в пользовательских программах, содержатся в библиотеке kernel32.dll. Это работа с процессами (GetModuleHandle, GetProcAddress, ExitProcess), вводом-выводом, памятью, синхронизацией. Ранее kernel32.dll загружался во всех контекстах процесса по одному и тому же адресу. Теперь, думаю именно из-за ASLR, в адресному пространстве каждого процесса он загружается по разным адресам? Большинство экспортируемых библиотекой kernel32.dll функций используют «родной» API ядра напрямую. | ||||||
| 77070000 | user32.dll | Одна из четырех основных библиотек поддержки Win32 API. Эта библиотека проецируется практически в каждый процесс Win32. Библиотека содержит часто используемые функции для обработки сообщений, меню, взаимодействия. Напомню, что в моей программе используются такие функции как: SetFocus, SendMessage, MessageBox, CreateWindowEx, DefWindowProcA, DispatchMessageA, GetMessageA, LoadCursorA, LoadIconA, PostQuitMessage, RegisterClassA, ShowWindow, TranslateMessage, UpdateWindow. Все эти функции предоставляются системной библиотекой user32.dll, поэтому без проецирования её в адресное пространство моего процесса моя программа (test2.exe) работать не будет. | ||||||
| 771F0000 | kernelbase.dll | Результат технологии разделения на уровни выполнения базовых функций DLL. Содержит так называемые низкоуровневые функции, которые ранее помещались в библиотеках kernel32.dll и advapi32.dll. Теперь код направляет запросы к этой библиотеке низкоуровневых функций, вместо того, чтобы, как раньше, выполнять их напрямую. | ||||||
| 77C00000 | ntdll.dll | Библиотека, обеспечивающая «родной» интерфейс (Native API) функций ядра как для приложений раннего этапа загрузки ОС, так и для функций интерфейса WinAPI. Все функции подсистемы Win32 можно разделить на две части: функции, требующие перехода в режим ядра и функции не требующие перехода в режим ядра. Для обработки API-функций пользовательского режима, которые требуют перехода в режим ядра и существует библиотека ntdll.dll. По своей структуре ntdll.dll представляет собой обычную библиотеку пользовательского режима, представляющую собой своеобразный «мост» (переходник) между функциями библиотек пользовательского режима и кодом, который реализует соответствующий функционал в ядре. Пользовательский режим (user mode) и режим ядра (kernel mode) существенно отличаются в реализации, однако пользовательский режим должен максимально сохранять совместимость с привычными (старыми) форматами входных/выходных данных функций, в то время как режим ядра может потребовать существенного видоизменения кода от версии Windows к версии. С этой точки зрения, ntdll.dll играет роль интерфейса совместимости, именно благодаря ему разработчики Microsoft могут свободно менять [при выпуске новых версий/пакетов обновлений Windows] внутреннюю реализацию функций в ядре, сохраняя, при этом, формат параметров функций пользовательского режима. Можно сказать, что Native API создан с единственной целью — вызывать функции ядра, код которого располагается в нулевом кольце защиты. Большинство точек входа в Native API являются «заглушками», которые передают параметры и управление коду режима ядра. | ||||||
| 77DE0000 | ntdll.dll | То же самое, что и описанный ntdll.dll, только для 32-битного процесса. | ||||||
| 7EFDB000 | TEB |
Блок переменных окружения потока (Thread Environment Block). Структура данных, размещаемая в адресном пространстве процесса, которая содержит информацию о конкретном потоке в пределах основного (текущего) процесса (в нашем случае — test2.exe). Каждый поток имеет свой TEB. Заполняется через функцию MmCreateTeb и заполняется загрузчиком потока. Создается, контролируется и разрушается исключительно самой ОС. Подобные регионы создаются и уничтожаются по мере появления/уничтожения потоков в процессе. Wow64 процессы имеют два TEB для каждого потока? | ||||||
| 7EFDE000 | PEB |
Блок переменных окружения процесса (Process Environment Block). Структура данных, размещенная в адресном пространстве процесса, которая содержит информацию о загруженных модулях (LDR_DATA), окружении, базовой информации и другие данные, которые требуются для нормального функционирования процесса. Создается через функцию MmCreatePeb и заполняется загрузчиком процесса на этапе создания адресного пространства процесса. PEB создается, контролируется и уничтожается исключительно самой ОС. Wow64 процессы имеют два PEB для каждого процесса? | ||||||
| 80000000 | Ядро | Память выше данного значения принадлежит ядру. В этой области памяти находятся модули ядра, объекты ядра и пользовательские объекты, доступные всем процессам — проекции системных файлов. Но это все уже тема отдельной статьи. |
Выводы
К каким выводам можно придти после изучения адресного пространства процесса? Первый состоит в том, что понятие «памяти» для пользовательских программ это достаточно условное обозначение, поскольку регионы адресного пространства могут по разному отображаться на различные объекты операционной системы. Второй состоит в том, что адресное пространство процесса это огромный линейный массив байтов, в котором хранится всё, с чем непосредственно работает процесс (программа). Массив этот виртуален, не ограничен физической памятью, уникален для каждого приложения и обладает достаточной размерностью, дабы программист не задумывался о его ограничениях. Механизм создания адресного пространства процесса достаточно сложен, и в статье удалось рассмотреть лишь малую часть его логики. В добавок, мы вовсе не касались 64-битных реалий, грозно смотрящих на нас из недалекого будущего  но, пожалуй это тема отдельной статьи.
но, пожалуй это тема отдельной статьи.
Глава 14
Адресное пространство процесса
В главе 11, «Управление памятью», было рассказано о том, как ядро управляет физической памятью. В дополнение к тому, что ядро должно управлять своей памятью, оно также должно, управлять и адресным пространством процессов — тем, как память видится для каждого процесса в системе. Операционная система Linux — это операционная система с виртуальной памятью (virtual memory operating system), т.е. для всех процессов выполняется виртуализация ресурсов памяти. Для каждого процесса создается иллюзия того, что он один использует всю физическую память в системе. Еще более важно, что адресное пространство процессов может быть даже значительно больше объема физической памяти. В этой главе рассказывается о том, как ядро управляет адресным пространством процесса.
Адресное пространство процесса состоит из диапазона адресов, которые выделены процессу, и, что более важно, в этом диапазоне выделяются адреса, которые процесс может так или иначе использовать. Каждому процессу выделяется «плоское» 32- или 64-битовое адресное пространство. Термин «плоское» обозначает, что адресное пространство состоит из одного диапазона адресов (например, 32-разрядное адресное пространство занимает диапазон адресов от 0 до 429496729). Некоторые операционные системы предоставляют сегментированное адресное пространство — адресное пространство состоит больше чем из одного диапазона адресов, т.е. состоит из сегментов. Современные операционные системы обычно предоставляют плоское адресное пространство. Размер адресного пространства зависит от аппаратной платформы. Обычно для каждого процесса существует свое адресное пространство. Адрес памяти в адресном пространстве одного процесса не имеет никакого отношения к такому же адресу памяти в адресном пространстве другого процесса. Тем не менее несколько процессов могут совместно использовать одно общее адресное пространство. Такие процессы называются потоками.
Значение адреса памяти — это заданное значение из диапазона адресов адресного пространства, как, например, 41021f000. Это значение идентифицирует определенный байт в 32-битовом адресном пространстве. Важной частью адресного пространства являются интервалы адресов памяти, к которым процесс имеет право доступа, как, например, 08048000–0804c000. Такие интервалы разрешенных адресов называются областями памяти (memory area). С помощью ядра процесс может динамически добавлять и удалять области памяти своего адресного пространства.
Процесс имеет право доступа только к действительным областям памяти. Более того, на область памяти могут быть установлены права только для чтения или запрет на выполнение. Если процесс обращается к адресу памяти, который не находится в действительной области памяти, или доступ к действительной области выполняется запрещенным образом, то ядро уничтожает процесс с ужасным сообщением «Segmentation Fault» (ошибка сегментации).
Области памяти могут содержать следующую нужную информацию.
• Отображение выполняемого кода из выполняемого файла в область памяти процесса, которая называется сегментом кода (text section).
• Отображение инициализированных переменных из выполняемого файла в область памяти процесса, которая называется сегментом данных (data section).
• Отображение страницы памяти, заполненной нулями, в область памяти процесса, которая содержит неинициализированные глобальные переменные и называется сегментом bss[79] (bss section). Нулевая страница памяти (zero page, страница памяти, заполненная нулями) — это страница памяти, которая полностью заполнена нулевыми значениями и используется, например, для указанной выше цели.
• Отображение страницы памяти, заполненной нулями, в память процесса, которая используется в качестве стека процесса пространства пользователя (не нужно путать со стеком процесса в пространстве ядра, который является отдельной структурой данных и управляется и используется ядром).
• Дополнительные сегменты кода, данных и BSS каждой совместно используемой библиотеки, таких как библиотека libc и динамический компоновщик, которые загружаются в адресное пространство процесса.
• Все файлы, содержимое которых отображено в память.
• Все области совместно используемой памяти.
• Все анонимные отображения в память, как, например, связанные с функцией malloc()[80].
Каждое действительное значение адреса памяти в адресном пространстве процесса принадлежит только и только одной области памяти (области памяти не перекрываются). Как будет показано, для каждого отдельного участка памяти в выполняющемся процессе существует своя область: стек, объектный код, глобальные переменные, отображенный в память файл и т.д.
Читайте также
Отображение файла на адресное пространство процесса
Отображение файла на адресное пространство процесса
Следующим шагом является распределение виртуального адресного пространства и отображение на него файла с использованием объекта отображения. С точки зрения программиста этот процесс распределения памяти
Адресное пространство процесса
Адресное пространство процесса
Адресное пространство ядра обычно совпадает с адресным пространством выполняющегося в данный момент процесса. В этом случае говорят, что ядро расположено в том же контексте, что и процесс. Каждый раз, когда процессу передаются
ГЛАВА 2. ПЯТЬ УРОВНЕЙ ЗРЕЛОСТИ ПРОИЗВОДСТВЕННОГО ПРОЦЕССА
ГЛАВА 2. ПЯТЬ УРОВНЕЙ ЗРЕЛОСТИ ПРОИЗВОДСТВЕННОГО ПРОЦЕССА
Постоянное совершенствование производственного процесса основано на многих небольших эволюционных шагах, а не на революционных нововведениях [Imai 86]. CMM предоставляет концептуальную структуру, организующую эти
Глава 15 Пространство и компоновка чертежа
Глава 15
Пространство и компоновка чертежа
Формирование в AutoCAD модели объекта, в том числе трехмерной, обычно не является самоцелью. Это делается для дальнейшего использования такой модели в системах прочностных расчетов и кинематического моделирования, при получении
Пространство модели и пространство листа
Пространство модели и пространство листа
Пространство модели (Model Space) – это пространство AutoCAD, где формируются модели объектов как при двумерном, так и при трехмерном моделировании. О том, что в окне AutoCAD на текущий момент установлено пространство модели, говорят
ГЛАВА 16. Пространство имен System.IO
ГЛАВА 16. Пространство имен System.IO
При создании полноценных приложений исключительно важна возможность сохранения информации между сеансами доступа пользователя. В этой главе рассматривается целый ряд вопросов, связанных с реализацией ввода-вывода в .NET. Первой нашей
Глава 10. Размер области процесса сканирования
Глава 10.
Размер области процесса сканирования
Этот параметр определяет максимальные размеры документа, который вы имеете возможность считать с помощью данного сканера. Некоторые младшие модели планшетных сканеров позволяют обрабатывать листы формата Legal (8,5 х 14 дюймов,
Глава 11. Скорость процесса сканирования
Глава 11.
Скорость процесса сканирования
Общее быстродействие сканера зависит от большого количества разнообразных факторов: характеристик механизма сканера, производительности компьютера, быстродействия используемых программ, текущего разрешения и глубины цвета.
Глава 15 Пространство и компоновка чертежа
Глава 15 Пространство и компоновка чертежа
Формирование в AutoCAD модели объекта, в том числе трехмерной, обычно не является самоцелью. Это делается для дальнейшего использования такой модели в системах прочностных расчетов и кинематического моделирования, при получении
Пространство модели и пространство листа
Пространство модели и пространство листа
Пространство модели (Model Space) – это пространство AutoCAD, где формируются модели объектов как при двумерном, так и при трехмерном моделировании. О том, что в окне AutoCAD на текущий момент установлено пространство модели, говорят
Глава 15 Пространство и компоновка чертежа
Глава 15 Пространство и компоновка чертежа
Пространство модели и пространство листа Мастер компоновки листа Работа с листами Вставка листа с помощью Центра управления AutoCAD Видовые экраны Именованные виды Неперекрывающиеся видовые экраны Создание нескольких видовых
Пространство модели и пространство листа
Пространство модели и пространство листа
Пространство модели (Model Space) – это пространство AutoCAD, где формируются модели объектов как при двумерном, так и при трехмерном моделировании. О том, что в окне AutoCAD на текущий момент установлено пространство модели, говорят
Глава 12 Пространство и компоновка чертежа
Глава 12
Пространство и компоновка чертежа
Формирование в AutoCAD модели объекта, в том числе трехмерной, обычно не является самоцелью. Это делается для дальнейшего использования такой модели в системах прочностных расчетов и кинематического моделирования, при получении
Пространство модели и пространство листа
Пространство модели и пространство листа
Пространство модели (Model Space) – это пространство AutoCAD, где формируются модели объектов как при двумерном, так и при трехмерном моделировании. О том, что в окне AutoCAD на текущий момент установлено пространство модели, говорят
Сегментация памяти (Схема памяти компьютера)
Время на прочтение
19 мин
Количество просмотров 52K
Представляю, Вам, перевод статьи одного из разработчиков PHP, в том числе версии 7 и выше, сертифицированного инженера ZendFramework. В данный момент работает в SensioLabs и большую часть занимается низкоуровневыми вещами, в том числе программированием в С под Unix. Оригинал статьи здесь.
Ошибка Сегментации: (Компьютерная верстка памяти)
Несколько слов, о чем эта запись в блоге
Я планирую в будущем писать технические статьи о PHP, связанные с глубоким пониманием памяти. Мне нужно, чтобы мои читатели имели такие знания, которые им помогут понять некоторые концепции дальнейшего объяснения. Для того, чтобы ответить на этот вопрос, нам придется перемотать время назад в 1960-е года. Я собираюсь объяснить вам, как работает компьютер, а точнее, как происходит доступ к памяти в современном компьютере, а затем вы поймете, из-за чего происходит это странное сообщение об ошибке — Segmentation Fault.
То, что вы будете читать здесь, краткое изложение основ дизайна компьютерной архитектуры. Я не буду заходить слишком далеко, если это не нужно, и буду использовать хорошо известные формулировки, так что, кто работает с компьютером каждый день может понять такие важные понятия о том, как работает ПК. Существует много книг о компьютерной архитектуре. Если вы хотите углубиться дальше в этой теме, я предлагаю вам достать некоторые из них и начать читать. Кроме того, откройте исходный код ядра ОС и изучите его, будь то ядро Linux, или любое другое.
Немного истории computer science
Еще в то время, когда компьютерами были огромные машины, тяжелее тонны, внутри вы могли бы найти один процессор с чем-то вроде 16Kb оперативной памяти (RAM). Не будем углубляться дальше =) В этот период компьютер стоил примерно $ 150 000 и мог выполнить ровно одну задачу в момент времени. Если бы мы в то время нарисовали схему его памяти, то архитектура выглядела следующим образом:
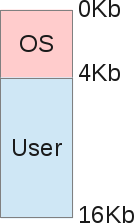
Как вы можете видеть, размер памяти 16Кб, и состоит из двух частей:
- Область памяти операционной системы(4kb)
- Область памяти запущенных процессов (12Kb)
Роль операционной системы заключалась в управлении прерываниями центрального процесса аппаратными средствами. Таким образом, операционная система нуждалась в памяти для себя, чтобы копировать данные с устройства и работать с ними (режим PIO). Для предоставления данных на экран тоже была необходима основная память, так как видеоадаптеры имели от нуля до нескольких килобайт памяти. И наша сольная программа использовала память ОС для достижения поставленных задач.
<Совместное использование компьютера
Но одна из главных проблем такой модели заключается в том, что компьютер (стоимостью $ 150 000) мог выполнять только одну задачу единовременно, и эта задача ужасно долго выполнялась: целые дни, чтобы обработать несколько Кб данных. По такой огромной цене явно не представляется возможным купить несколько машин, чтобы выполнить несколько процедур одновременно. Так что люди пытались распределить ресурсы машины. Это было время рождения многозадачности. Имейте в виду, что тогда было ещё очень рано говорить о многопроцессорных ПК. Как мы можем заставить одну машину с одним процессором, и на самом деле решить несколько различных задач? Ответ на этот вопрос — планирование. Пока один процесс занят в ожидании ввода / вывода (ожидает прерывание), процессор может запустить другой процесс. Мы не будем говорить о планировании на всех уровнях (слишком широкой теме), только о памяти. Если машина может выполнять несколько задач, один процесс за другим, то это означает, что память будет распределяться примерно таким образом:

Обе, задачи А и B, сохраняются в оперативной памяти, так как копировать их туда и обратно на диск — слишком ресурсозатратный процесс. Данные должны оставаться в оперативной памяти на постоянной основе, так как их соответствующие задачи по-прежнему работают. Планировщик дает некоторое время процессора, то задаче А, то B, и т.д… каждый раз предоставляя доступ к её области памяти. Но подождите, здесь есть проблема. Когда один программист будет писать код задачи B, он должен знать адреса границ памяти. Например, задача В будет располагаться с 10Kb памяти до 12Кб. Поэтому каждый адрес в программе должен жестко записан именно в эти пределы. Если машина затем будет выполнять ещё 3 задачи, то адресное пространство будет разделено на большее количество областей, и границы памяти задачи В сдвинутся. Программисту пришлось бы переписать свою программу, чтобы использовать меньше памяти, и переписывать каждый адрес указателя памяти.
Здесь очевидна так же другая проблема: что, если задача B получит доступ к памяти задачи А? Это легко может произойти, потому что, когда вы манипулируете указателями, небольшая ошибка при вычислении приводит к совершенно другому адресу. Это может испортить данные задачи А (перезаписать их). Также существует проблема безопасности, что если задача А работает с очень чувствительными данными? Нет никакого способа, чтобы предотвратить чтение задачей B некоторой области памяти задачи А. И последнее: что, если задача B по ошибке перезапишет память ОС? Например, память ОС от 0Kb до 4Kb, в случае если задача B перепишет этот участок, то операционная система наверняка потерпит крах.
Адресное пространство
Таким образом, нужна помощь операционной системы и аппаратного обеспечения, чтобы получить возможность запускать несколько задач находящиеся в памяти. Один из способов помочь, является создание того, что называется адресное пространство. Адресное пространство является абстракцией памяти, которую операционная система даст процессу, и эта концепция является абсолютно фундаментальной, так как в настоящее время каждая часть компьютера, которую вы встретите в вашей жизни, разработана таким образом. Сейчас не существует никакой другой модели (в гражданском обществе, армия может сохранять тайну).
Каждая система в настоящее время организована с таким макетом памяти как “код — стек — куча”, и это расстраивает.
Адресное пространство содержит все задачи (процессы) которые необходимо запустить:
- Код: это машинные инструкции, которые процессор должен обработать
- Данные: данные машинных команд которые обрабатываются вместе с ними.
Адресное пространство делится следующим образом:
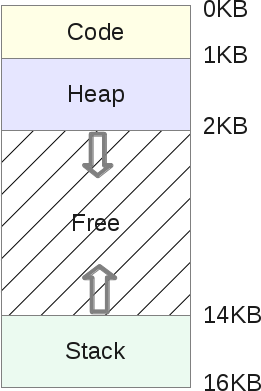
- Стек — это область памяти, где программа хранит информацию о вызываемых функциях, их аргументах и каждой локальной переменной в функции.
- Куча — это область памяти где программист волен делать всё что угодно.
- Код — область памяти, где будут храниться инструкции ЦП скомпилированной программы. Эти инструкции генерируются компилятором, но могут быть написаны вручную. Обратите внимание, что сегмент кода обычно делится на три части (текст, данные и BSS), но мы не будем так глубоко погружаться.
- Код всегда фиксированного размера создаётся компилятором и будет весить (в нашем примере) 1Кб.
- Стек, однако, является изменяемой зоной, так как программа работает. Когда функции вызываются, стек расширяется, при возвращении из функции: стек уменьшается.
- Куча тоже является изменяемой зоной, когда программист выделяет память из кучи (malloc()), она расширяется, а когда программист освобождает память обратно (free()), куча сужается.
Так как стек и куча являются расширяемыми зонами, они расположены на противоположных местах в одном адресном пространстве: стек будет расти вверх, а куча вниз. Они оба могут свободно расти, каждый в направлении другого. ОС должна просто проверять, чтобы зоны не перекрывались, правильно используя виртуальное пространство.
Виртуализация памяти
Если задача А получила адресное пространство, такое, которое мы видели, так же как и задача B. То как мы можем разместить их в памяти? Это кажется странным, но адресное пространство задачи А начинается от 0KB до 16Kb, так же как и задачи B. Хитрость заключается в создании виртуальной среды. На самом деле картина размещения А и В в памяти:
Когда задача А попытается получить доступ к памяти в своем адресном пространстве, например индекс 11К, где-то в своем собственном стеке, операционная система выполнит хак и на самом деле загрузит индекс памяти 1500, потому что индекс 11K принадлежит задаче B. На самом деле, всё адресное пространство каждой программы в памяти — это просто виртуальная память. Каждая программа, работающая на компьютере, обращается к виртуальным адресам, с помощью некоторых аппаратных чипов ОС будет обманывать процесс, когда он будет пытаться получить доступ к любой зоне памяти.
ОС виртуализирует память и гарантирует, что любая задача не сможет получить доступ к памяти, которой не владеет. Виртуализация памяти позволяет изолировать процесс. Задача А больше не может получить доступ к памяти задачи B и не сможет получить доступ к памяти ОС. И все это полностью прозрачно для задач на уровне пользователя, благодаря тоннам сложного кода ядра ОС. Таким образом, операционная система обслуживает каждый запрос памяти процесса. Это работает очень эффективно — даже если запущено слишком много различных программ. Для достижения этой цели процесс получает помощь от аппаратного обеспечения, главным образом от процессора и некоторых электронных компонентов вокруг него, таким как блок управления памятью (MMU ). MMU появился в начале 70-х годов, вместе с IBM, как отдельные чипы. Сейчас они встраиваются непосредственно в наши чипы CPU и являются обязательными для любой современной ОС для запуска. На самом деле, операционная система не выполняет тонны операций, а полагается на некоторые аппаратные особенности поведения, которые облегчат доступ к памяти.
Вот небольшая программа на C, показывающая некоторые адреса памяти:
#include <stdio.h>
#include <stdlib.h>
int main (int argc, символ ** argv)
{
int v = 3;
printf("Code is at %p \n", (void *)main);
printf("Stack is at %p \n", (void *)&v);
printf("Heap is at %p \n", malloc(8));
return 0;
}
На моей LP64 x86_64 машине он показывает:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010Мы можем видеть, что адрес стека находится намного выше адреса кучи, а код расположен ниже стека. Но каждый из этих 3-х адресов являются подделками: в физической памяти, по адресу 0x7ffe60a1465c точно не расположено целое число 3. Помните, что каждая программа пользователя манипулирует адресами виртуальной памяти, тогда как программы уровня ядра, таких как само ядро ОС (или аппаратный код драйвера) могут манипулировать физическими адресами RAM.
Трансляция адреса
Адресная трансляция — это формулировка, за которой скрывается некая магическая техника. Аппаратное обеспечение (ММУ)транслирует каждый виртуальный адрес программы уровня пользователя в правильный физический адрес. Таким образом, операционная система помнит для каждой задачи соответствие между его виртуальными адресами и физическими. И это является сложной задачей. Операционная система управляет всей памятью задач на уровне пользователя для каждого требования доступа к памяти, обеспечивая тем самым полную иллюзию процессу. Таким образом, операционная система преобразует всю физическую память в полезную, мощную и простую абстракцию.
Давайте подробно рассмотрим простой сценарий:
Когда процесс запускается, операционная система бронирует фиксированную область физической памяти, скажем, 16KB. Затем сохраняет начальный адрес этого пространства в специальную переменную, называемую базой. Потом устанавливает другую специальную переменную, называемую границами (или пределом) ширины пространства — 16КB. Далее операционная система сохранит эти два значения в таблице процессов, называемой PCB (Process Control Block).
А вот как выглядит процесс виртуального адресного пространства:
А вот его физическое изображение:

ОС решила сохранить его в физической памяти в диапазоне адресов от 4K до 20K. Таким образом, базовый адрес устанавливается в 4K, а предел установлен на 4 + 16 = 20К. Когда этот процесс планируется (учитывая некоторое время процессора), операционная система считывает обратно предельные значения из PCB и копирует их в конкретные регистры процессора. Когда CPU во время работы попытается загрузить, например, виртуальный адрес 2K (что-то в его куче), CPU добавит этот адрес базы, полученный от операционной системы. Таким образом, процесс доступа памяти приведет к физическому местоположению 2K + 4K = 6К.
Физический адрес = виртуальный адрес + предел
Если полученный физический адрес (6К) находится вне границ (-4K | 20K-), это означает, что процесс попытался получить доступ к неправильному участку памяти, которым он не владеет. Процессор сгенерирует исключение, и поскольку в ОС есть обработчик исключений для этого события, ОС активируется процессором и будет знать, что исключение памяти только что произошло на CPU. Затем ОС по умолчанию передаст сигнал поврежденному процессу “SIGSEGV”. Ошибка сегментации, которая по умолчанию (это может быть изменено) завершит задачу с сообщением — “Произошел сбой в работе с недопустимым доступом к памяти”.
Перемещение памяти
Еще лучше, если задача А не запланирована, это означает, что она извлекается из CPU, так как планировщик попросил запустить другую задачу (скажем, задачу B). При выполнении задачи B ОС может свободно переместить всё физическое адресное пространство задачи A. Операционная система часто получает время процессора при выполнении пользовательских задач. Когда завершается последний системный вызов, управление ЦП возвращается к ОС, и до выполнения системного вызова ОС может делать все, что захочет, управляя памятью, перемещая все пространство процесса в различные физические слоты карт памяти.
Это относительно просто: операционная система перемещает область 16K в другую 16K свободного пространства, и просто обновляет базовые и связанные переменные задачи A. Когда задача будет возобновлена и передана CPU, процесс преобразования адреса по-прежнему будет работать, но это не приведет к тому же физическому адресу, как раньше.
Задача А не заметила ничего, с её точки зрения, её адресное пространство по-прежнему начинается от 0К до 16К. Операционная система и аппаратное обеспечение MMU берут полный контроль над каждым доступом к памяти для задачи А, давая ей полную иллюзию. Программист задачи A манипулирует своими разрешенными виртуальными адресами, от 0 до 16, а MMU будет заботиться о позиционировании в физической памяти.
Образ памяти после перемещения будет выглядеть следующим образом:
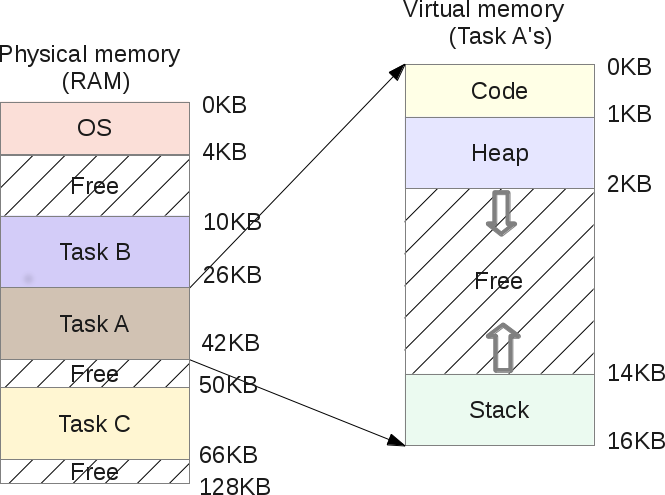
В настоящее время программист больше не должен задаваться вопросом, где его программа находиться в оперативной памяти, если другая задача работает рядом с его собственной, и какими адресами манипулировать. Это делает сама ОС вместе с очень производительным и умным аппаратным средством — “Блок управления памяти” (MMU).
Сегментация памяти
Обратите внимание на внешний вид слова «сегментация» — мы близки к объяснению почему происходят ошибки сегментации. В предыдущей главе мы объяснили о трансляции и перемещении памяти, но модель, которую мы использовали имеет свои недостатки:
Мы предположили, что каждое виртуальное адресное пространство фиксируется шириной 16Kb. Очевидно, что это не так в действительности. Операционная система должна поддерживать список физической памяти свободных слотов (шириной 16 Kb), чтобы иметь возможность найти место для любого нового процесса с просьбой начать или переместить запущенный процесс. Как сделать это эффективно, чтобы не замедлить всю систему? Как вы можете видеть, каждый процесс занимает участок памяти 16 Kb, даже если процесс не использует всё своё адресное пространство, что очень вероятно. Эта модель явно тратит много памяти, процесс потребляет1KB памяти, а его участок памяти в физической памяти 16Кб. Такие отходы называют внутренней фрагментацией: память зарезервирована, но никогда не используется.
Для решения некоторых из этих проблем, мы собираемся погрузиться в более сложную организацию памяти в ОС — сегментацию. Сегментацию легко понять: мы расширяем идею «базы и границ» трех логических сегментов памяти: кучи, кода и стека; каждого процесса — вместо того, чтобы просто рассматривать образ памяти в качестве одного уникального объекта.
При такой концепции, память между стеком и кучей больше не тратится впустую. Вот так:

Теперь легко заметить, что свободное пространство в виртуальной памяти для задач А больше не выделяется в физической памяти, использование памяти становится гораздо более эффективным. Единственным отличием является то, что в настоящее время для любой задачи, ОС должна запоминать не одну пару баз/границ, а три: по одной паре для каждого типа сегмента. ММУ заботится о переводе, так же, как и раньше, и теперь поддерживает, 3 базовых величин, и 3 границ.
Например, здесь, куча задачи A имеет базу 126K и границы 2К. Затем задача просит доступ к виртуальному адресу 3KB, в куче; физический адрес 3Kb — 2Кб (начало кучи) = 1Kb + 126K (смещение) = 127K. 127K находится перед 128К — это правильный адрес памяти, который может быть выполнен.
Совместное использование сегментов
Сегментирование физической памяти не только решает проблему свободной виртуальной памяти, освобождая больше физической памяти, но она также позволяет разделить физические сегменты с помощью различных процессов виртуальных адресных пространств. Если запустить дважды ту же задачу, задачу А например, сегмент кода точно такой же: обе задачи выполняют одни и те же команды процессора. Обе задачи будут использовать свой собственный стек и кучу, обращаться к своим собственным наборам данных. Неэффективно дублировать сегмент кода в памяти. ОС теперь может разделить его и сэкономить еще больше памяти. Например так:
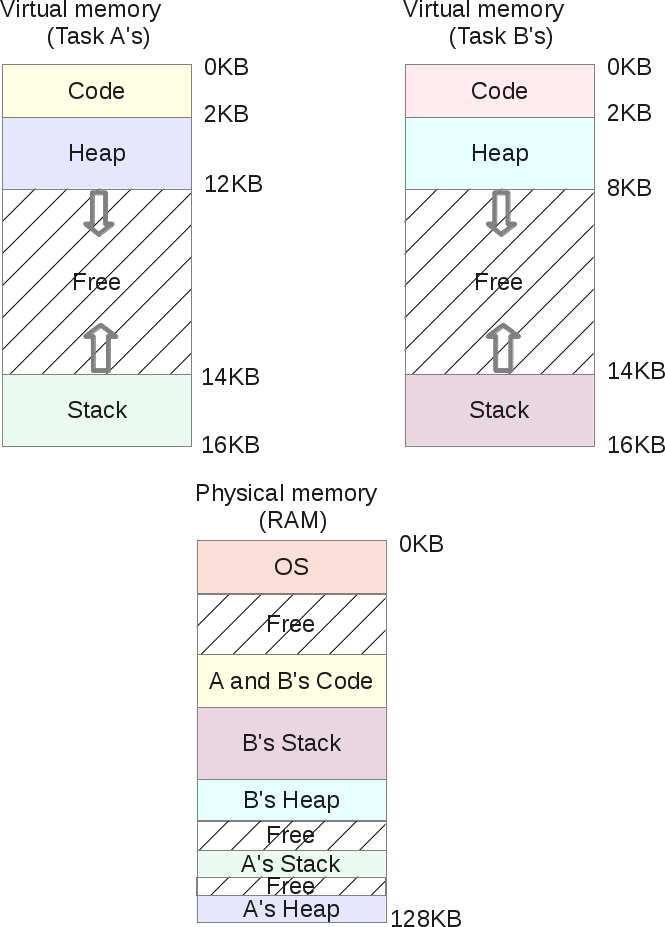
На картинке выше, А и В имеют свою собственную область кода в их соответствующем виртуальном пространстве памяти, но под капотом. Операционная система разделяет эту область в одних и тех же физических сегментах памяти. Обе задачи А и В абсолютно не видят этого, для них обеих — они владеют своей памятью. Для достижения этой цели ОС должна реализовать еще одну особенность: бит защиты сегмента. ОС будет для каждого физического сегмента создавать, регистрировать границы / пределы для правильной работы блока MMU, но она также зарегистрирует флаг разрешения.
Поскольку код не является изменяемым, сегменты кода все созданы с флагом разрешения RX. Процесс может загрузить эту область памяти для выполнения, но любой процесс, попытавшийся писать в эту область памяти, будет завершен ОС. Остальные два сегмента: куча и стек являются RW, процессы могут читать и писать от своего собственного стека / кучи, но они не могут выполнять код из него (это предотвращает недостатки безопасности программы, где плохой пользователь может захотеть повредить кучу или стек, чтобы ввести код для запуска, которому будет доступно ядро ОС. Это невозможно, так как куча и стек сегментов часто не являются исполняемыми. Обратите внимание, что это было не всегда, так как требует дополнительной поддержки аппаратного обеспечения для эффективной работы, это называется «бит NX» под процессором Intel). Сегменты памяти разрешений изменяемы во время выполнения: задача может потребовать mprotect () от ОС. Эти сегменты памяти отчетливо видны под Linux, используйте утилиты /proc/{pid}/maps или /usr/bin/pmap
Ниже приведен пример для PHP:
$ pmap -x 31329
0000000000400000 10300 2004 0 r-x-- php
000000000100e000 832 460 76 rw--- php
00000000010de000 148 72 72 rw--- [ anon ]
000000000197a000 2784 2696 2696 rw--- [ anon ]
00007ff772bc4000 12 12 0 r-x-- libuuid.so.0.0.0
00007ff772bc7000 1020 0 0 ----- libuuid.so.0.0.0
00007ff772cc6000 4 4 4 rw--- libuuid.so.0.0.0
... ...Здесь мы детально видим все отображения памяти. Адреса являются виртуальными и отображают их разрешения области памяти. Как мы можем видеть, каждый общий объект (.so) отображается в адресное пространство как несколько отображений (вероятно кода и данных), и области кода являются исполнимыми, а под капотом они разделяются в физической памяти между каждым процессом, отображающим такой общий объект в его собственное адресное пространство…
Самое большое преимущество разделяемых объектов под Linux (и Unix) — это экономия памяти. Возможно также создать общую зону, ведущую к общему физическому сегменту памяти, с помощью системного вызова mmap(). Буква ‘s’, появившаяся рядом с этой областью, означает “разделяемая”.
Пределы Сегментации
Мы видели, что сегментация решает проблему не используемой виртуальной памяти. Когда процесс не использует некоторый объем памяти, этот процесс не отображается в физическую память благодаря сегментам, которые соответствуют выбранной памяти. Тем не менее, это не совсем верно. Что делать, если процесс требует 16Kb кучи? ОС, скорее всего, создаст сегмент физической памяти размером 16КБ. Но если пользователь затем освобождает 2Кб такой памяти? Тогда, ОС должна уменьшить сегмент 16Кб до 14kb. Что делать, если теперь программист спрашивает 30Kb кучи? Старый сегмент 14Kb теперь должен вырасти до 30 КБ, но может ли он это сделать? Другие сегменты теперь могут окружать наш сегмент 14kb, препятствуя его росту. Тогда ОС придется искать свободное пространство 30 КБ, а затем перемещать сегмент.

Большая проблема с сегментами в том, что они приводят к очень фрагментированной физической памяти, потому что они продолжают расти, поскольку пользовательские задачи запрашивают и освобождают память. Операционная система должна поддерживать список свободных кусочков памяти и управлять ими.
Иногда, ОС путем суммирования всех свободных сегментов получает некоторое доступное пространство, но так как оно не соприкасается, она не может использовать это пространство и должна отказать требованию памяти от процессов, даже если существует пространство в физической памяти. Это очень плохой сценарий. Операционная система может попытаться сжать память путем слияния всех свободных участков в один большой кусок, который можно было бы использовать в будущем, чтобы удовлетворить запрос памяти.
Но такой алгоритм уплотнения сложен для CPU, и в это время ни один пользовательский процесс не сможет получить CPU: операционная система полностью загружена реорганизацией своей физической памяти, таким образом, система становится непригодной для использования. Сегментация памяти решает множество проблем управления памятью и многозадачности, но она также показывают реальные недостатки. Таким образом, существует необходимость в расширении возможностей сегментации и исправлении этих недостатков. Отсюда образовалось ещё одно понятие — “пагинация памяти”.
Пагинация памяти
Пагинация страниц памяти разделяет некоторые концепции сегментации памяти и пытается решить её проблемы. Мы увидели, что основной проблемой сегментации памяти является то, что сегменты будут увеличиваться и уменьшаться очень часто, так как пользовательский процесс запрашивает и освобождает память. Иногда операционная система сталкивается с проблемой. Она не может найти большую область свободного места, чтобы удовлетворить запрос памяти пользовательского процесса, потому что физическая память стала сильно фрагментирована с течением времени: она содержит много сегментов разного размера по всей физической памяти, что приводит к сильно фрагментированной физической памяти.
Разбивка решает эту проблему с помощью простой концепции: что если для каждого физического распределения ядро будет выделять фиксированный размер? Страницы — это сегменты физической памяти фиксированного размера. Если операционная система использует распределения фиксированного размера, то намного легче управлять пространством, что в итоге сводит на нет фрагментацию памяти.
Давайте покажем пример еще раз, предполагая небольшое 16Кб виртуальное адресное пространство, чтобы облегчить представление:
С пагинацией мы не говорим о кучи, стеке или сегменте кода. Мы разделим весь процесс виртуальной памяти на зоны фиксированного размера: мы называем их страницы. На приведенном выше примере мы разделили адресное пространство в виде 4-х страниц, 4КБ каждый.
Затем мы делаем то же самое с физической памятью.
И операционная система просто хранит то, что называется «Таблица процессорных страниц» — связь между одной страницей виртуальной памяти процесса и базовой физической страницей (который мы называем «страница кадра»).
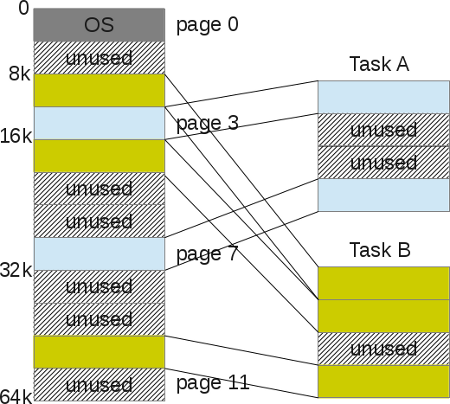
С помощью этого способа управления памятью больше нет проблем в свободном управлении пространством. Кадр страницы отображается (используется) или нет, ядру легко найти достаточное количество страниц, чтобы удовлетворить запрос памяти пользовательского процесса. Он просто хранит список свободных страниц кадров, а также просматривает его при каждом запросе памяти. Страница является наименьшей единицей памяти, которой ОС может управлять. Страница (на нашем уровне) является неделимой. Вместе со страницами каждому процессу прилагается таблица страниц, которая хранит адресные переводы. Переводы больше не используют значения границы, как это было с сегментацией, а использует «номер виртуальной страницы (VPN)» и «смещение» на этой странице.
Давайте покажем пример преобразования адресов с нумерацией страниц. Виртуальное адресное пространство размером 16Kb, т.е. нам нужно 14 бит для представления адреса (2 ^ 14 = 16Kb). Размер страницы 4 Кб, так что нам нужно 4kb (16/4), чтобы выбрать нашу страницу:

Теперь, когда процесс хочет загрузить, например, адрес 9438 (из 16384 возможностей), это дает 10.0100.1101.1110 в двоичной системе, что приводит к следующему:

То есть 1246й байт виртуальной страницы 2 ( «0100.1101.1110» го байта в «10» й странице). Теперь, операционная система должна искать эту страницу таблицы процессов, чтобы узнать на какой странице 2я карта. Согласно тому, что мы предложили, страница 2 — это 8К байт в физической памяти. Таким образом, виртуальный адрес 9438 приводит к физическому адресу 9442 (8k + 1246 смещение). Мы нашли наши данные! Как мы уже говорили, существует лишь одна таблица страниц для каждого процесса, поскольку каждый процесс будет иметь свои собственные переводы адреса, так же, как с сегментами. Но подождите, где эти таблицы страниц хранятся на самом деле? Угадайте …: в физической памяти, да, а где же ей ещё быть? Если таблицы страниц сами хранятся в памяти, следовательно, для каждого доступа к памяти, память должна иметь доступ для извлечения VPN. Таким образом, со страницами один доступ к памяти равен фактически двум доступам к памяти: один для извлечения записи таблицы страниц, и один, чтобы получить доступ к «реальным» данным. Зная, что доступ к памяти медленный процесс, получаем — что это не лучшая идея.
Переводно-ассоциативный буфер: TLB
Использование поискового вызова в качестве механизма ядра для поддержки виртуальной памяти может привести к высокой производительности накладных расходов. Измельчение адресного пространства на небольшие фиксированного размера единицы (страницы) требует большого количества информации о карте. Потому что информация о карте, как правило, хранится в физической памяти. Логический поиск подкачки требует дополнительного поиска в памяти для каждого виртуального адреса, сгенерированного программой. И тут опять приходят аппаратные средства, чтобы ускорить и помочь ОС. В пагинации, как и в сегментации, аппаратные средства помогают ядру ОС перевести адреса эффективным приемлемым способом. TLB является частью MMU, всего лишь простой кэш некоторых VPN переводов. TLB будет предотвращать доступ ОС к памяти от доступа к таблице страниц процесса, для получения физического адреса памяти из виртуальной. Аппаратное обеспечение MMU будет срабатывать на каждом виртуальном доступе к памяти, извлекая VPN из этого адреса, и выполняя поиск TLB, если он совпадает для этого конкретного VPN. Если он совпал, то он просто выполнил свою роль. Если он получает промах, то он будет искать таблицу страниц процесса, и если ссылка на память действительна, она обновит TLB, так что любой дальнейший доступ памяти этой страницы попадет в TLB.
Как и в любом кэше, вы чаще попадете, чем получите промах, так как ситуация промах вызывает страницу поиска, вследствие чего, доступ к памяти будет медленным. Вы догадаетесь об этом. Чем больше страниц, тем лучше TLB попадает, но тем больше неиспользуемого пространства вы будете иметь на каждой странице. Здесь должен быть найден компромисс. Современные ядра используют различные размеры страницы. Ядро Linux может использовать то, что называется «огромные страницы», страницы, размером 2Mb что больше традиционных 4Kb. Кроме того, информацию лучше хранить в смежных адресах памяти. Если вы сократите свои данные в памяти, то скорее всего будете страдать от пропусков TLB или от переполнения TLB. Это то, что называется Эффективность пространственной локальности TLB: Данные, находящиеся непосредственно рядом с вами, могут быть сохранены в той же физической странице, таким образом, получая выгоду из текущего доступа к памяти из TLB.
Для переключения контекста TLB хранит также то, что называется ASID в каждой из своих записей. Это идентификатор адресного пространства, который является чем-то вроде PID. Каждый запланированный процесс имеет свой собственный ASID, следовательно TLB может управлять любым адресом процесса без риска недействительных адресов из других процессов. Также, если пользовательский процесс попытается загрузить неверный адрес, адрес, скорее всего, не будет сохранен в TLB, следовательно произойдет промах в поиске в записи таблицы страниц процесса. Теперь адрес сохраниться, но с неверным битом. Под X86 каждый перевод использует 4 байта, таким образом, имеется много бит. И нередко можно найти действительный бит вместе с другими составными, такими как грязный бит, биты защиты, опорного бита и т.д.… Если запись помечена как недопустимая, ОС по умолчанию использует SIGSEGV, что приводит к «ошибке сегментации», даже если здесь мы больше не говорим о сегментах. Вы должны знать, что подкачка более сложна в современных ОС, чем я объяснил. Современные ОС, как правило, используют многоуровневые таблицы страниц, многостраничные размеры, а также важную концепцию, которую мы не будем объяснять. Страница выселения, известная как «swaping» (Процесс, когда ядро обменивает страницы памяти на дисковое пространство, чтобы эффективно использовать главную память и создать иллюзию для пользовательских процессов, что основная память не ограничена в пространстве).
Вывод
Теперь вы знаете, что находится под сообщением «Ошибка сегментации». Операционная система использует сегменты для отображения виртуальной памяти в физической памяти. Когда процесс ядра хочет получить доступ к некоторой памяти, он выдает требование о том, чтобы MMU переводил на физический адрес памяти. Но если этот адрес не правильный, из пределов физического сегмента, или если права защиты сегмента не подходящие, то ОС по умолчанию посылает сигнал процессу, вызвавшего отказ: SIGSEGV, который имеет обработчик по умолчанию. Он убивает процесс и выводит сообщение: «Ошибка сегментации”. В других операционных системах (предполагаю) часто сообщение выглядит как „Общая неисправность защиты“. С Linux — нам повезло, мы имеем возможность доступа к исходному коду, здесь есть место исходного кода для X86 / 64 платформ, которое управляет ошибками доступа к памяти, так же здесь и SIGSEGV. Если вы заинтересованы в разработке сегментов для X86 / 64 платформ, вы можете посмотреть на их определение в ядре Linux. Вы также найдете интересный материал о пейджинговой памяти, которая поддерживает более длинный путь сегментирования памяти, чем использование классических сегментов. Мне понравилось писать эту статью, она перенесла меня в конец девяностых, когда я программировал свой первый CPU: Motorola 68HC11 с использованием C, VHDL и прямого монтажа. Я не программировал виртуальное управления памятью ОС, а использовал физические адреса напрямую (моему процессору не нужны такие сложные механизмы). Затем я подался в Web; но мои первые знания пришли от электроники, систем которые мы используем каждый день…
Организация памяти процесса
Организация памяти процессов ОС Windows рассмотрена во многих книгах и статьях. Мы изучим только те аспекты этого вопроса, которые имеют отношение к поиску переменных в памяти, а также чтению и записи их значений.
Адресное пространство процесса
Адресное пространство процесса
Исполняемый EXE-файл и запущенный процесс ОС – это не одно и то же. Файл – это некоторые данные, записанные на устройство хранения информации (например жёсткий диск). Исполняемый файл содержит инструкции (или машинный код), которые выполняет процессор без каких либо дополнительных преобразований.
Когда вы запускаете EXE-файл, для его исполнения ОС нужно выполнить несколько шагов. Во-первых, прочитать его содержимое с устройства хранения и записать в
оперативную память
(random-access memory или RAM). Благодаря этому процессор получает намного более быстрый доступ к инструкциям из файла, поскольку скорость его интерфейса с RAM на несколько порядков выше чем с любым диском.
Когда содержимое файла записано в оперативную память, ОС загружает туда же все необходимые для его работы динамические библиотеки. После этого шага, процесс готов к выполнению. Поскольку все современные ОС для компьютеров и телефонов многозадачные, несколько процессов могут исполняться параллельно. Параллельность в данном случае не означает одновременность. То есть если у компьютера один процессор с одним ядром, он будет переключаться между процессами. В таком случае говорят о распределении процессорного времени. В многозадачных ОС этим занимается специальная программа
планировщик
(scheduler). Благодаря ей каждый процесс получает единицы времени (тики или секунды) в зависимости от своего приоритета.
Чем занимается запущенный процесс? Чтобы ответить на этот вопрос, заглянем в типичный исполняемый файл. В основном он содержит алгоритмы обработки и интерпретации каких-то данных. Следовательно, большая часть работы процесса заключается в манипуляции данными.
Где процесс хранит свои данные? Мы уже знаем, что ОС всегда загружает исполняемые инструкции в оперативную память. В случае данных, сам процесс может свободно выбрать место их хранения: жёсткий диск, оперативная память или даже удалённый компьютер (например игровой сервер подключённый по сети). Большая часть данных, необходимых во время работы процесса копируются в оперативную память для ускорения доступа к ней. Поэтому, именно в RAM мы можем прочитать состояния игровых объектов. Они будут доступны на протяжении всего времени выполнения (runtime) процесса.
Иллюстрация 3-2 демонстрирует элементы типичного процесса. Как правило, он состоит из нескольких модулей. Обязательным из них является EXE, который содержит все инструкции и данные, загруженные из исполняемого файла. Другие модули (обозначенные DLL_1 и DLL_2) соответствуют библиотекам, функции которых вызываются из EXE.
{caption: «Иллюстрация 3-2. Элементы типичного процесса Windows»}

Все Windows приложения используют как минимум одну системную библиотеку, которая предоставляет доступ к WinAPI-функциям. Даже если вы не пользуетесь WinAPI явно в своей программе, компилятор вставляет вызовы ExitProcess и VirtualQuery автоматически в ходе компиляции. Они отвечают за корректное завершение процесса и управление его памятью.
Мы рассмотрели исполняемый файл и запущенный процесс. Теперь поговорим о библиотеках с функциями. Они делятся на два типа: динамически подключаемые (dynamic-link libraries или DLL) и статически подключаемые (static libraries). Главное различие между ними заключается во времени разрешения зависимостей. Когда исполняемый файл использует функцию библиотеки, говорят, что он от неё зависит.
Статически подключаемые библиотеки должны быть доступны в момент компиляции. Программа
компоновщик
собирает их и исполняемый файл в единый выходной файл. Таким образом, EXE-модуль на иллюстрации 3-2 содержит машинный код и статических библиотек, и исполняемого файла.
Динамически подключаемые библиотеки также должны быть доступны в момент компиляции. Однако, результирующий файл на выходе компоновщика не содержит их машинный код. Вместо этого ОС ищет и загружает эти DLL библиотеки в момент запуска приложения. Если найти их не удалось, приложение завершает свою работу с ошибкой. На иллюстрации 3-2 у процесса есть два модуля DLL, соответствующие динамическим библиотекам.
Рассмотрим, как CPU выполняет инструкции процесса. Эти инструкции – элементарные шаги более сложных высокоуровневых алгоритмов. Результат выполнения каждого шага сохраняется в регистрах (или ячейках памяти) процессора и используется в дальнейшем или выгружается в оперативную память.
Запущенное приложение может использовать несколько алгоритмов в ходе своей работы. Некоторые из них могут выполняться параллельно (так же как процессы в многозадачной ОС).
Поток
(thread) – это часть машинного кода процесса, которая может выполняться независимо от других частей. Потоки взаимодействуют друг с другом (обмениваются информацией) через разделяемые ресурсы, например файл или область RAM. За выбор потока для исполнения в данный момент отвечает уже знакомый нам планировщик ОС. Как правило, число одновременно работающих потоков определяется числом ядер процессора. Но есть технологии (например hyper-threading от Intel), позволяющие более эффективно использовать мощности процессора и исполнять сразу два потока на одном ядре.
Иллюстрация 3-2 демонстрирует, что модули процесса могут содержать несколько потоков, а могут не содержать ни одного. EXE-модуль всегда имеет главный поток (main thread), который первым получает управление при старте приложения.
Рассмотрим структуру памяти типичного процесса. Иллюстрация 3-3 демонстрирует адресное пространство процесса, состоящего из EXE-модуля и DLL-библиотеки. Адресное пространство – это множество всех доступных процессу адресов памяти. Оно разделено на блоки, называемые сегментами. У каждого из них есть базовый адрес, длина и набор прав доступа (на запись, чтение и исполнение). Разделение на сегменты упрощает задачу контроля доступа к памяти. С их помощью ОС может оперировать блоками памяти, а не отдельными адресами.
{caption: «Иллюстрация 3-3. Адресное пространство типичного процесса»}

Процесс на иллюстрации 3-3 имеет три потока (включая главный). У каждого потока есть свой сегмент стека. Стек – это область памяти, организованная по принципу «последним пришёл — первым вышел» («last in — first out» или LIFO). Она инициализируется ОС при старте приложения и используется для хранения переменных и вызова функций. В стеке сохраняется адрес инструкции, следующей за вызовом. После возврата из функции процесс продолжает своё выполнение с этой инструкции. Также через стек передаются входные параметры функций.
Кроме сегментов стека, у процесса есть несколько сегментов динамической памяти (heap), к которым имеет доступ каждый поток.
У всех модулей процесса есть обязательные сегменты: .text, .data и .bss. Кроме обязательных могут быть и дополнительные сегменты (например .rsrc). Они не представлены на схеме 3-3.
Таблица 3-1 кратко описывает каждый сегмент из иллюстрации 3-3. Во втором столбце приведены их обозначения в отладчике OllyDbg.
{caption: «Таблица 3-1. Описание сегментов», width: «100%», column-widths: «15%,15%,*»}
|
Сегмент |
Обозначение в OllyDbg |
Описание |
|
Стек главного потока |
Stack of main thread |
Содержит автоматические переменные (память под которые выделяется при входе в блок области видимости и освобождается при выходе из него), стек вызовов с адресами возврата из функций и их входные параметры. |
|
— |
— |
— |
|
Динамическая память ID 1 |
Heap |
Дополнительный сегмент памяти, который создаётся при переполнении сегмента динамической памяти ID 0. |
|
— |
— |
— |
|
Динамическая память ID 0 |
Default heap |
ОС всегда создаёт этот сегмент при запуске процесса. Он используется по умолчанию для хранения переменных. |
|
— |
— |
— |
|
Стек потока 2 |
Stack of thread 2 |
Выполняет те же функции, что и стек главного потока, но используется только потоком 2. |
|
— |
— |
— |
|
|
Code |
Содержит машинный код модуля EXE. |
|
— |
— |
— |
|
|
Data |
Содержит статические и не константные глобальные переменные модуля EXE, которые инициализируются значениями при создании. |
|
— |
— |
— |
|
|
|
Содержит статические и не константные глобальные переменные модуля EXE, которые не инициализируются при создании. |
|
— |
— |
— |
|
Стек потока 3 |
Stack of thread 2 |
То же самое, что и стек потока 2, только используется потоком 3. |
|
Динамическая память ID 2 |
|
Дополнительный сегмент памяти, расширяющий сегмент динамической памяти ID 1 при его переполнении. |
|
— |
— |
— |
|
|
Code |
Содержит машинный код модуля DLL. |
|
— |
— |
— |
|
|
Data |
Содержит статические и не константные глобальные переменные модуля DLL, которые инициализируются значениями при создании. |
|
— |
— |
— |
|
|
|
Содержит статические и не константные глобальные переменные модуля DLL, которые не инициализируются при создании. |
|
— |
— |
— |
|
Динамическая память ID 3 |
|
Дополнительный сегмент памяти, расширяющий сегмент динамической памяти ID 2 при его переполнении. |
|
— |
— |
— |
|
TEB потока 3 |
Data block of thread 3 |
Содержит блок информации о потоке (Thread Information Block или TIB), также известный как блок контекста потока (Thread Environment Block или TEB). Он представляет собой структуру с информацией о потоке 3. |
|
— |
— |
— |
|
TEB потока 2 |
Data block of thread 2 |
Содержит TEB структуру потока 2. |
|
— |
— |
— |
|
TEB главного потока |
Data block of main thread |
Содержит TEB структуру главного потока. |
|
— |
— |
— |
|
PEB |
Process Environment Block |
Содержит блок контекста процесса (Process Environment Block или PEB). Эта структура данных с информацией о процессе в целом. |
|
— |
— |
— |
|
Пользовательские данные |
User Share Data |
Содержит данные, которые доступны и совместно используются текущим процессом и другим. |
|
— |
— |
— |
|
Память ядра |
Kernel memory |
Область памяти, зарезервированная для нужд ОС. |
Предположим, что на иллюстрации 3-3 приведено адресное пространство процесса игрового приложения. В этом случае состояние игровых объектов может находится в сегментах, отмеченных красным цветом.
ОС назначает базовые адреса этих сегментов в момент старта приложения. Эти адреса могут отличаться от запуска к запуску. Кроме того, последовательность сегментов в памяти может также меняться. В то же время некоторые из сегментов, отмеченных синим цветом на иллюстрации 3-3 (например PEB, User Share Data и Kernel memory), имеют неизменный адрес при каждом старте приложения.
Отладчик OllyDbg позволяет прочитать структуру памяти (memory map) запущенного процесса. Иллюстрации 3-4 и 3-5 демонстрируют вывод OllyDbg для приложения, адресное пространство которого приведено на схеме 3-3.
{caption: «Иллюстрация 3-4. Структура памяти процесса в OllyDbg»}

{caption: «Иллюстрация 3-5. Структура памяти процесса в OllyDbg (продолжение)»}

Таблица 3-2 демонстрирует соответствие между схемой 3-3 и сегментами настоящего процесса из иллюстраций 3-4 и 3-5.
{caption: «Таблица 3-2. Сегменты процесса»}
|
Базовый адрес |
Сегмент |
Обозначение в OllyDbg |
|
001ED000 |
Стек главного потока |
Stack of main thread |
|
— |
— |
— |
|
004F0000 |
Динамическая память ID 1 |
Heap |
|
— |
— |
— |
|
00530000 |
Динамическая память ID 0 |
Default heap |
|
— |
— |
— |
|
00ACF000 |
Стеки вспомогательных |
Stack of thread N |
|
00D3E000 |
потоков |
|
|
0227F000 |
|
|
|
— |
— |
— |
|
00D50000-00D6E000 |
Сегменты EXE модуля «ConsoleApplication1» |
|
|
— |
— |
— |
|
02280000-0BB40000 |
Дополнительные сегменты |
|
|
0F230000-2BC70000 |
динамической памяти |
|
|
— |
— |
— |
|
0F0B0000-0F217000 |
Сегменты модуля DLL «ucrtbased» |
|
|
— |
— |
— |
|
7EFAF000 |
TEB вспомогательных |
Data block of thread N |
|
7EFD7000 |
потоков |
|
|
7EFDA000 |
|
|
|
— |
— |
— |
|
7EFDD000 |
TEB главного потока |
Data block of main thread |
|
— |
— |
— |
|
7EFDE000 |
PEB главного потока |
Process Environment Block |
|
— |
— |
— |
|
7FFE0000 |
Пользовательские данные |
User shared data |
|
— |
— |
— |
|
80000000 |
Память ядра |
Kernel memory |
Возможно, вы обратили внимание, что OllyDbg не может автоматически идентифицировать все сегменты динамической памяти. С этой задачей лучше справляются отладчик WinDbg и инструмент HeapMemView.
Поиск переменной в памяти
Поиск переменной в памяти
Внутриигровые боты читают состояния объектов из памяти процесса игрового приложения. Эти состояния могут храниться в нескольких переменных, находящихся в разных сегментах. Базовые адреса этих сегментов и смещение переменных внутри них могут меняться от запуска к запуску. Это означает, что абсолютные адреса переменных непостоянны. К сожалению, бот может читать данные из памяти только по абсолютным адресам. Следовательно, он должен уметь искать нужные ему переменные самостоятельно.
Термин «абсолютный адрес» неточен, если мы говорим о
модели сегментации памяти x86
. x86 – это архитектура процессора, впервые реализованная компанией Intel. Сегодня практически все настольные компьютеры имеют процессоры этой архитектуры. Правильный термин, который следует употреблять – «линейный адрес». Он вычисляется по следующей формуле:
линейный адрес = базовый адрес сегмента + смещение в сегменте
В этой главе мы продолжим использовать термин «абсолютный адрес», поскольку он интуитивно понятен.
Задачу поиска переменной в памяти процесса можно разделить на три этапа. В результате получится следующий алгоритм:
-
1.
Найти сегмент, который содержит искомую переменную.
-
2.
Определить базовый адрес сегмента.
-
3.
Определить смещение переменной внутри сегмента.
Очень высока вероятность того, что переменная будет храниться в одном и том же сегменте при каждом старте приложения. Это правило не выполняется для сегментов динамической памяти, что связано с особенностью её организации. Если мы установили, что переменная не находится в сегменте динамической памяти, первый шаг алгоритма может быть выполнен вручную. Полученный результат можно закодировать в боте без каких-либо дополнительных условий и проверок. В противном случае бот должен искать сегмент самостоятельно.
Второй шаг алгоритма бот должен всегда выполнять сам. Как мы упоминали ранее, адреса сегментов меняются при старте приложения.
Последний шаг алгоритма – найти смещение переменной в сегменте. Нет никаких гарантий, что оно не будет меняться при каждом старте приложения. Однако, смещение может оставаться тем же в некоторых случаях. Это зависит от типа сегмента, как демонстрирует таблица 3-3. Таким образом, в некоторых случаях мы можем выполнить третий шаг алгоритма вручную и закодировать результат в боте.
{caption: «Таблица 3-3. Смещение переменных в различных типах сегментов», width: «100%», column-widths: «20%,*»}
|
Тип сегмента |
Постоянство смещения |
|
|
Смещение переменной не меняется |
|
|
при перезапуске приложения. |
|
— |
— |
|
Стек |
В большинстве случаев смещение переменной не меняется. Но оно зависит от порядка выполнения инструкций (control flow). Если этот порядок меняется, смещение, скорее всего, тоже изменится. |
|
— |
— |
|
Динамическая память |
Смещение переменной меняется при перезапуске приложения. |
Поиск переменной в 32-битном приложении
Поиск переменной в 32-битном приложении
Применим алгоритм поиска переменной на практике. Выполним все его шаги вручную для приложения ColorPix, которым мы пользовались в прошлой главе для чтения цветов и координат пикселей экрана. Это поможет лучше понять и запомнить все необходимые действия.
Приложение ColorPix является 32-битным. Скриншот его окна приведён на иллюстрации 3-6. Попробуем найти в памяти переменную, которая соответствует координате X выделенного на экране пикселя. На иллюстрации 3-6 она подчёркнута красной линией.
{caption: «Иллюстрация 3-6. Окно приложения ColorPix»}

W> В ходе дальнейших действий вы не должны закрывать уже запущенное приложение ColorPix. Иначе, вам придётся начать поиск переменной сначала.
Для начала найдём сегмент памяти, в котором хранится переменная. Эту задачу можно разделить на два этапа:
-
1.
Найти абсолютный адрес переменной с помощью сканера памяти Cheat Engine.
-
2.
Сравнить найденный адрес с базовыми адресами всех сегментов. Таким образом мы узнаем сегмент, в котором хранится переменная.
Чтобы найти переменную с помощью Cheat Engine, выполните следующие действия:
-
1.
Запустите 32-битную версию сканера с правами администратора.
-
2.
Выберите пункт главного меню «File» -> «Open Process». Вы увидите диалог со списком запущенных процессов (см. иллюстрацию 3-7).
{caption: «Иллюстрация 3-7. Диалог выбора процесса Cheat Engine», height: «50%»}

-
1.
Выберите процесс с именем «ColorPixel.exe» и нажмите кнопку «Open». В результате имя этого процесса отобразится в верхней части окна Cheat Engine.
-
2.
Введите значение координаты X, которое вы видите в данный момент в окне ColorPixel, в поле «Value» окна Cheat Engine.
-
3.
Нажмите кнопку «First Scan», чтобы найти абсолютный адрес указанного значения координаты X в памяти процесса ColorPixel.
Когда вы нажимаете кнопку «First Scan», значение в поле «Value» окна Cheat Engine, должно соответствовать тому, что отображает ColorPixel. Координата X изменится, если вы переместите курсор мыши по экрану, поэтому нажать на кнопку будет затруднительно. Воспользуйтесь комбинацией клавиш Shift+Tab, чтобы переключиться на неё и Enter, чтобы нажать.
В левой части окна Cheat Engine вы увидите результаты поиска, как на иллюстрации 3-8.
{caption: «Иллюстрация 3-8. Результаты поиска в окне Cheat Engine»}

Если в момент сканирования процесса несколько переменных имеют то же самое значение что и координата X, найденных переменных будет больше чем две. В этом случае вам надо отфильтровать ошибочные результаты. Для этого выполните следующие шаги:
-
1.
Переместите курсор мыши, чтобы значение координаты X в окне ColorPixel изменилось.
-
2.
Введите новую координату X в поле «Value» окна Cheat Engine.
-
3.
Нажмите кнопку «Next Scan».
После этого в окне результатов должны остаться только две переменные, как на иллюстрации 3-8. В моём случае их абсолютные адреса равны 0018FF38 и 0025246C. У вас они могут отличаться, но это не существенно для нашего примера.
Мы нашли абсолютные адреса двух переменных, хранящих значение координаты X. Теперь определим сегменты, в которых они находятся. Для этой цели воспользуемся отладчиком OllyDbg. Для поиска сегментов выполните следующие шаги:
-
1.
Запустите отладчик OllyDbg с правами администратора. Путь к нему по умолчанию:
C:\Program Files (x86)\odbg201\ollydbg.exe. -
2.
Выберите пункт главного меню «File» -> «Attach». Вы увидите диалог со списком запущенных 32-битных процессов (см. иллюстрацию 3-9).
{caption: «Иллюстрация 3-9. Диалог выбора процесса в отладчике OllyDbg»}

-
1.
Выберите процесс «ColorPix» в списке и нажмите кнопку «Attach». Когда отладчик подключится к нему, вы увидите состояние «Paused» в правом нижнем углу окна OllyDbg.
-
2.
Нажмите комбинацию клавиш Alt+M, чтобы открыть окно, отображающее структуру памяти процесса ColorPix. Это окно «Memory Map» приведено на иллюстрации 3-10.
{caption: «Иллюстрация 3-10. Окно Memory Map со структурой памяти процесса»}

Переменная с абсолютным адресом 0018FF38 хранится в сегменте стека главного процесса («Stack of main thread»), который занимает адреса с 0017F000 по 00190000.
I> OllyDbg отображает только адрес начала сегмента и его размер. Чтобы вычислить конечный адрес, вы должны сложить два эти числа. Результат будет равен адресу начала следующего сегмента.
Вторая найденная нами переменная с адресом 0025246C находится в сегменте с базовым адресом 00250000, тип которого неизвестен. Найти его будет труднее чем сегмент стека. Поэтому мы продолжим работу с первой переменной.
Последний шаг поиска – расчёт смещения переменной в сегменте стека. Стек в архитектуре x86 растёт вниз. Это означает, что он начинается с больших адресов и расширяется в сторону меньших. Следовательно, базовый адрес стека равен его верхней границе (в нашем случае это 00190000). Нижняя границе стека может меняться по ходу его увеличения.
Смещение переменной равно разности базового адреса сегмента, в котором она находится, и её абсолютного адреса. В нашем случае мы получим:
Для сегментов динамической памяти, .bss и .data это вычисление выглядело бы иначе. Все они растут вверх (в сторону больших адресов), поэтому их базовый адрес соответствует нижней границе.
Теперь у нас есть вся необходимая информация, чтобы найти и прочитать координату X в любом запущенном процессе ColorPix. Алгоритм бота, который бы это делал, выглядит следующим образом:
-
1.
Прочитать базовый адрес сегмента стека главного потока. Этот адрес хранится в TEB сегменте.
-
2.
Вычесть смещение переменной (всегда равное C8) из базового адреса сегмента стека. В результате получим её абсолютный адрес.
-
3.
Прочитать значение переменной из памяти процесса ColorPix по её абсолютному адресу.
Корректность первого шага алгоритма мы можем проверить вручную с помощью отладчика OllyDbg. Он позволяет прочитать информацию сегмента TEB в удобном виде. Для этого дважды щёлкните по сегменту, который называется «Data block of main thread», в окне «Memory Map» отладчика. Вы увидите окно как на иллюстрации 3-11.
{caption: «Иллюстрация 3-11. Окно OllyDbg с информацией TEB»}

Базовый адрес сегмента стека 00190000 указан во второй строчке открывшегося окна. Учтите, что этот адрес может меняться при каждом запуске приложения.
Поиск переменной в 64-битном приложении
Поиск переменной в 64-битном приложении
Применим наш алгоритм поиска переменной для 64-битного приложения.
W> Отладчик OllyDbg не поддерживает 64-битные приложения, поэтому вместо него воспользуемся WinDbg.
Resource Monitor (монитор ресурсов) Windows 7 будет нашим приложением для анализа. Он распространяется вместе с ОС и доступен сразу после её установки. Разрядность Resource Monitor совпадает с разрядностью Windows. Чтобы запустить приложение, откройте меню Пуск (Start) Windows и введите следующую команду в строку поиска:
Иллюстрации 3-12 демонстрирует окно Resource Monitor.
{caption: «Иллюстрация 3-12. Окно приложения Resource Monitor»}

Найдём переменную, хранящую размер свободной памяти системы. На иллюстрации её значение подчёркнуто красной линией.
Прежде всего найдём сегмент, содержащий искомую переменную. Для этого воспользуемся 64-битной версией сканера Cheat Engine. Интерфейс его 64 и 34-битных версий одинаков, поэтому вам нужно выполнить те же действия, что и при анализе приложения ColorPixel.
В моем случае сканер нашёл две переменные с адресами 00432FEC и 00433010. Определим сегменты, в которых они хранятся. Чтобы прочитать структуру памяти процесса с помощью отладчика WinDbg, выполните следующие действия:
-
1.
Запустите 64-битную версию WinDbg с правами администратора. Путь к нему по умолчанию:
C:\Program Files (x86)\Windows Kits\8.1\Debuggers\x64\windbg.exe. -
2.
Выберите пункт главного меню «File» -> «Attach to a Process…». Откроется окно диалога со списком запущенных 64-разрядных процессов, как на иллюстрации 3-13.
{caption: «Иллюстрация 3-13. Диалог выбора процесса в отладчике WinDbg», height: «50%»}

-
1.
Выберите в списке процесс «perfmon.exe» и нажмите кнопку «OK».
-
2.
В командной строке отладчика, расположенной в нижней части окна «Command», введите текст
!addressи нажмите Enter. Структура памяти процесса отобразится в окне «Command», как на иллюстрации 3-14.
{caption: «Иллюстрация 3-14. Вывод структуры памяти процесса в окне Command»}

Обе переменные с абсолютными адресами 00432FEC и 00433010 находятся в сегменте динамической памяти с ID 2. Границы этого сегмента: с 003E0000 по 00447000. Смещение первой переменной в сегменте равно 52FEC:
00432FEC — 003E0000 = 52FEC
Для бота алгоритм поиска переменной, хранящей размер свободной памяти ОС в приложении Resource Monitor, выглядит следующим образом:
-
1.
Прочитать базовый адрес сегмента динамической памяти с ID 2. Чтобы получить доступ к этим сегментам, надо воспользоваться следующими WinAPI-функциями:
-
2.
Добавить смещение переменной (в моем случае равное 52FEC) к базовому адресу сегмента. В результате получится её абсолютный адрес.
-
3.
Прочитать значение переменной из памяти процесса.
Как вы помните, смещение переменной в сегменте динамической памяти обычно меняется при перезапуске приложения. В случае если приложение достаточно простое (как рассматриваемый нами Resource Monitor), порядок выделения динамической памяти может быть одним и тем же при каждом старте программы.
Попробуйте перезапустить Resource Monitor и найти переменную ещё раз. Вы получите то же самое её смещение в сегменте, равное 52FEC.
Мы рассмотрели адресное пространство Windows процесса. Затем составили алгоритм поиска переменной в памяти и применили его к 32 и 64-разрядному приложениям. В ходе этого мы познакомились с функциями отладчиков OllyDbg и WinDbg для анализа структуры памяти процесса.
Стек процесса
Вообще говоря, стеков в процессе может быть много и размещаться они могут в разных областях виртуальной памяти. Вот несколько примеров:
Cтек основной нити.
Он же стек процесса в однопоточном приложении. Начальный адрес выделяется ядром. Размер стека может быть изменён в командной строке до запуска программы командой ulimit -s <размер в килобайтах> или вызовом setrlimit
#include <sys/resource.h>
...
struct rlimit rl;
int err;
rl.rlim_cur = 64*1024*1024;
err = setrlimit(RLIMIT_STACK, &rl);
Стек обработчика сигналов
Стек обработчика сигналов может быть расположен в любой области памяти, доступной на чтение и запись. Альтернативный стек создаётся вызовом sigaltstack(new, old), которому передаются указатели на структуры, описывающие стек:
typedef struct {
void *ss_sp; /* Base address of stack */
int ss_flags; /* Flags */
size_t ss_size; /* Number of bytes in stack */
} stack_t;
После создания альтернативного стека можно задавать обработчик сигнала, указав в параметрах функции sigaction() флаг SS_ONSTACK.
Стек нити
При создании новой нити для всегда создаётся новый стек. Функция инициализации нити pthread_attr_init(pthread_attr_t *attr) позволяет вручную задать базовый адрес стека нити и его размер через поля attr.stackaddr и attr.stacksize. В большинстве случаев рекомендуется предоставить выбор адреса и размера стека системе, задав attr.stackaddr=NULL; attr.stacksize=0;.
Выделение памяти из кучи
Динамическое выделение памяти в куче (heap) реализовано на уровне стандартных библиотек C/C++ (функция malloc() и оператор new соответственно). Для распределения памяти из кучи процесс должен сообщить ядру, какой размер виртуальной памяти должен быть отображён на физическую память. Для этого выделяется участок виртуальной памяти, расположенный между адресами start_brk и brk. Величина start_brk фиксирована, а brk может меняться в процессе выполнения программы. Brk (program break — обрыв программы) — граница в виртуальной памяти на которой заканчивается отображение в физическую память. В современном Linux за этой границей могут быть отображения файлов и кода ядра в память процесса, но в оригинальном Unix это был «край» памяти программы. Начальное значение brk — start_brk устанавливается в момент загрузки программы из файла вызовом execve() и указывает на участок после инициализированных (data) и неинициализированных (BSS) глобальных переменных.
Для того, чтобы изменить размер доступной физической памяти, необходимо изменить верхнюю границу области кучи.
#include <unistd.h>
int brk(void *addr); //явное задание адреса
void *sbrk(intptr_t increment); //задание адреса относительно текущего значения
// возвращает предыдущее значение адреса границы
Вызов brk() устанавливает максимальный адрес виртуальной памяти, для которого в сегменте данных выделяется физическая память. Увеличение адреса равноценно запросу физической памяти, уменьшение — освобождению физической памяти.
Вызов sbrk(0) позволяет узнать текущую границу сегмента памяти.
В Linux вызов brk() транслируется в вызов функции ядра do_mmap(), изменяющий размер анонимного файла, отображаемого в память.
do_mmap(NULL, oldbrk, newbrk-oldbrk,
PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_FIXED|MAP_PRIVATE, 0)
Файлы, отображаемые в память
Отображение содержимого файла в виртуальную память mmap() задействует кэш файловой системы. Некоторые страницы виртуальной памяти отображаются на физические страницы кэша. В тех ситуациях, когда обычные физические страницы сохраняются в своп, страницы, отображенные в файлы сохраняются в сами файлы. Отображение файлов в память может использоваться, в частности, для отображения секций кода исполняемых файлов и библиотек, в соответствующие сегменты памяти процесса.
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int msync(void *addr, size_t length, int flags);
int munmap(void *addr, size_t length);
Функция mmap() отображает length байтов, начиная со смещения offset файла, заданного файловым дескриптором fd, в память, начиная с адреса addr. Параметр addr является рекомендательным, и обычно бывает выставляется в NULL. mmap() возвращает фактический адрес отображения или значение MAP_FAILED (равное (void *) -1) в случае ошибки.
Аргумент prot описывает режим доступа к памяти (не должен конфликтовать с режимом открытия файла).
- PROT_EXEC данные в отображаемой памяти могут исполняться
- PROT_READ данные можно читать
- PROT_WRITE в эту память можно писать
- PROT_NONE доступ к этой области памяти запрещен.
Параметр flags указывает, видны ли изменения данных в памяти другим процессам, отобразившим этот фрагмент файла в свою память, и влияют ли эти изменения на сам файл.
- MAP_SHARED запись в эту область памяти будет эквивалентна записи в файл и изменения доступны другим процессам. Файл может не обновляться до вызова функций
msync()илиmunmap(). - MAP_PRIVATE неразделяемое отображение с механизмом copy-on-write. Запись в эту область приводит к созданию для процесса персональной копии данных в памяти и не влияет на файл.
- MAP_ANONYMOUS память не отображается ни в какой файл, аргументы fd и offset игнорируются. Совместно с MAP_SHARED может использоваться для создания общей памяти, разделяемой с дочерними процессами
- MAP_FIXED память обязательно отображается с адреса
addrили возвращается ошибка. Не рекомендуется к использованию, так как сильно зависит от архитектуры процессора и конкретной ОС.
msync() сбрасывает изменения сделанные в памяти в отображенный файл. Параметры addr и length позволяют синхронизировать только часть отображенной памяти.
munmap() отменяет отображение файла в память и сохраняет сделанные в памяти изменения в файл.
Разделяемая память в System V IPC
В подсистеме межпроцессного взаимодействия System V IPC (System five interprocess communication — названо в по имени версии Unix, в которой эта подсистема появилась) для совместной работы с памятью используется резервирование физической памяти на уровне ядра. После резервирования процессы могут отображать зарезервированную память в своё виртуальное адресное пространство используя для идентификации зарезервированного участка идентификатор, генерируемый специальным образом.
Данное резервирование не привязано к какому-либо процессу и сохраняется даже тогда, когда ни один процесс эту физическую память не использует. Таким образом выделение памяти для совместного использования становится «дорогим» с точки зрения использованных ресурсов. Программа, резервирующая области памяти для совместного доступа и не освобождающая их, может либо исчерпать всю доступную память, либо занять максимально доступное в системе количество таких областей.
У областей совместно используемой памяти, как и других объектов System V IPC есть атрибуты «пользователь-владелец», «группа-владельца», «пользователь-создатель», «группа-создателя», а так же права на чтение и запись для владельца, группы-владельца и остальных, аналогичные файловым. Например: rw- r— —.
Пример вызовов для работы общей памятью:
// создание ключа на основе inode файла и номера проекта
// файл не ложен удаляться до завершения работы с общей памятью
key_t key=ftok("/etc/hostname", 456);
// получение идентификатора общей памяти на основе ключа
// размером size байт с округлением вверх
// до размера кратного размеру страницы
//
// опция IPC_CREAT - говорит, что если память ещё не зарезервирована
// то должна быть выполнена резервация физической памяти
size=8000
int shmid=shmget(key, size, IPC_CREAT);
// подключение зарезервированной памяти к виртуальному адресному пространству
// второй параметр - желаемый начальный адрес отображения
// третий параметр - флаги, такие как SHM_RDONLY
int *addr=(int *)shmat(shmid, NULL, 0);
// можно работать с памятью по указателю
addr[10]=23;
// отключение разделяемой памяти от виртуального адресного пространства
int err;
err=shmdt(addr);
// освобождение зарезервированной памяти
err=shmctl(shmid, IPC_RMID, NULL);
Список всех зарезервированных областей памяти в системе можно просмотреть командой lspci -m:
lsipc -m
KEY ID PERMS OWNER SIZE NATTCH STATUS CTIME CPID LPID COMMAND
0xbe130fa1 3112960 rw------- root 1000B 11 May03 7217 9422 /usr/sbin/httpd -DFOREGROUND
0x00000000 557057 rw------- usr74 384K 2 dest Apr28 17752 7476 kdeinit4: konsole [kdeinit]
0x00000000 5898243 rw------- usr92 512K 2 dest 12:05 5265 9678 /usr/bin/geany /home/s0392/1_1.s
0x00000000 4521988 rw------- usr75 384K 2 dest May06 22351 16323 sview
0x00000000 3276805 rw------- usr15 384K 1 dest May05 24835 15236
0x00000000 4587530 rw------- usr75 2M 2 dest May06 19404 16323 metacity
OOM Killer
Выделение физической памяти в Linux оптимистично. В момент вызова brk() проверяется лишь то факт, что заказанная виртуальная память не превышает общего объёма физической памяти + размер файла подкачки. Реальное выделение памяти происходит при первой записи. В этом случае может оказаться, что вся доступная физическая память и своп уже распределены между другими процессами.
При нехватке физической памяти Linux запускает алгоритм Out of memory killer (OOM killer) который относительно случайно выбирает один из процессов и завершает его, освобождая тем самым физическую память.