
Хранимая процедура

— объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере — могут выполняться стандартные операции с базами данных (как DDL, так и DML). — хранимые процедуры должны быть вызваны с помощью функции CALL

Наследие процедур T-SQL § принимать входные параметры и возвращать вызывающей процедуре или пакету ряд значений в виде выходных параметров; § содержать программные инструкции, которые выполняют операции в базе данных, в том числе вызывающие другие процедуры; § возвращать значение состояния вызывающей процедуре или пакету, таким образом передавая сведения об успешном или неуспешном завершении (и причины последнего).
![Синтаксис --SQL Server Stored Procedure Syntax CREATE { PROC | PROCEDURE } [schema_name. ]](https://present5.com/presentation/-107391857_437052289/image-4.jpg "Синтаксис --SQL Server Stored Procedure Syntax CREATE { PROC | PROCEDURE } [schema_name. ]")
Синтаксис —SQL Server Stored Procedure Syntax CREATE { PROC | PROCEDURE } [schema_name. ] procedure_name [ ; number ] [ { @parameter [ type_schema_name. ] data_type } [ VARYING ] [ = default ] [ OUT | OUTPUT | [READONLY] ] [ , . . . n ] [ WITH <procedure_option> [ , . . . n ] ] [ FOR REPLICATION ] AS { [ BEGIN ] sql_statement [; ] [. . . n ] [ END ] } [; ] <procedure_option> : : = [ ENCRYPTION ] [ RECOMPILE ] [ EXECUTE AS Clause ]

Аргументы • schema_name — Имя схемы, которой принадлежит процедура. Процедуры привязаны к схеме. Если имя схемы не указано при создании процедуры, то автоматически назначается схема по умолчанию для пользователя, который создает процедуру. • procedure_name Имя процедуры. Имена процедур должны соответствовать требованиям, предъявляемым к идентификаторам, и должны быть уникальными в схеме. • ; number — Необязательный целочисленный аргумент, используемый для группирования одноименных процедур. Все сгруппированные процедуры можно удалить, выполнив одну инструкцию DROP PROCEDURE. • {[BEGIN]sql_statement[; ][. . . n][END]} Одна или несколько инструкций Transact-SQL, составляющих текст процедуры. Инструкции можно заключить в необязательные ключевые слова BEGIN и END.
 • @ parameter - Параметр, объявленный в процедуре. Укажите имя параметра, начинающееся")
Аргументы (продолжение) • @ parameter — Параметр, объявленный в процедуре. Укажите имя параметра, начинающееся со знака @. Имя параметра должно соответствовать правилам для идентификаторов. Параметры являются локальными в пределах процедуры; в разных процедурах могут быть использованы одинаковые имена параметров. • OUT | OUTPUT — Показывает, что параметр процедуры является выходным. Используются параметры OUTPUT для возврата значений в вызвавший процедуру код. • EXECUTE AS clause — Определяет контекст безопасности, в котором должна быть выполнена процедура. • VARYING — Указывает результирующий набор, поддерживаемый в качестве выходного параметра. Этот параметр динамически формируется процедурой, и его содержимое может различаться. Применяется только к параметрам типа cursor. Этот параметр недопустим для процедур CLR.

Рекомендации • Начинайте текст процедуры с инструкции SET NOCOUNT ON • При создании или упоминании объектов процедуре используйте имена схем. базы данных в • Не выполняйте обработку или передачу слишком большого объема данных и ограничивайте область результатов в коде процедуры. • Используйте явные транзакции, указывая ключевые слова BEGIN/END TRANSACTION, и по возможности сокращайте транзакции.

• Используйте функцию Transact-SQL TRY…CATCH для обработки ошибок в пределах процедуры. • Используйте ключевое слово DEFAULT для всех столбцов таблицы, на которые ссылаются инструкции Transact-SQL CREATE TABLE и ALTER TABLE в тексте процедуры. • Используйте ключевые слова NULL и NOT NULL для каждого столбца во временной таблице. • Используйте оператор UNION ALL вместо операторов UNION и OR, если нет необходимости получить уникальные значения.
![Примеры CREATE PROCEDURE My. Proc AS UPDATE dbo. [Order Details] SET Quantity = 100](https://present5.com/presentation/-107391857_437052289/image-9.jpg "Примеры CREATE PROCEDURE My. Proc AS UPDATE dbo. [Order Details] SET Quantity = 100")
Примеры CREATE PROCEDURE My. Proc AS UPDATE dbo. [Order Details] SET Quantity = 100 Для вызова процедуры: Execute My. Proc

CREATE PROCEDURE Delete. Employee @emp. Id INT, @counter INT OUTPUT AS SELECT @counter = COUNT(*) FROM Works_on WHERE Emp. Id = @emp. Id DELETE FROM Employee WHERE Id = @emp. Id DELETE FROM Works_on WHERE Emp. Id = @emp. Id; Для вызова процедуры: DECLARE @quantity. Delete. Employee INT; EXECUTE Delete. Employee @emp. Id=18316, @counter=@quantity. Delete. Employee OUTPUT; PRINT N’Удалено сотрудников: ‘ + convert(nvarchar(30), @quantity. Delete. Employee);
, @Year. Order. Date int) AS SELECT Last.")
CREATE PROCEDURE Employees. In. Dept (@city varchar(10), @Year. Order. Date int) AS SELECT Last. Name, Birth. Date, City FROM dbo. Employees JOIN dbo. Orders ON dbo. Orders. Employee. ID = dbo. Employees. Employee. ID WHERE dbo. Employees. City = @city and YEAR(dbo. Orders. Order. Date) = @Year. Order. Date
 AS")
CREATE PROCEDURE Production. usp. Delete. Work. Order ( @Work. Order. ID int ) AS SET NOCOUNT ON; BEGIN TRY BEGIN TRANSACTION — Delete rows from the child table, Work. Order. Routing, for the specified work order. DELETE FROM Production. Work. Order. Routing WHERE Work. Order. ID = @Work. Order. ID; — Delete the rows from the parent table, Work. Order, for the specified work order. DELETE FROM Production. Work. Order WHERE Work. Order. ID = @Work. Order. ID; COMMIT END TRY BEGIN CATCH — Determine if an error occurred. IF @@TRANCOUNT > 0 ROLLBACK — Return the error information. DECLARE @Error. Message nvarchar(4000), @Error. Severity int; SELECT @Error. Message = ERROR_MESSAGE(), @Error. Severity = ERROR_SEVERITY(); RAISERROR(@Error. Message, @Error. Severity, 1); END CATCH; GO EXEC Production. usp. Delete. Work. Order 13;

Transact-SQL Stored procedure

UDF

— представляет собой подпрограмму которая принимает параметры Transact-SQL, — выполняет действия, такие как сложные вычисления — возвращает результат этих действий в виде значения — в отличие от хранимых процедур, функции всегда возвращают одно значение — определяемые пользователем функции посредством инструкции CREATE FUNCTION создаются

Вызовы § В инструкциях Transact-SQL, например SELECT. § В приложениях, вызывающих функцию. § В определении другой пользовательской функции. § Для параметризации представления или улучшения функциональности индексированного представления. § Для определения столбца таблицы. § Для определения ограничения CHECK на столбец. § Для замены хранимой процедуры.
![Синтаксис --Transact-SQL Scalar Function Syntax CREATE FUNCTION [ schema_name. ] function_name ( [ {](https://present5.com/presentation/-107391857_437052289/image-17.jpg "Синтаксис --Transact-SQL Scalar Function Syntax CREATE FUNCTION [ schema_name. ] function_name ( [ {")
Синтаксис —Transact-SQL Scalar Function Syntax CREATE FUNCTION [ schema_name. ] function_name ( [ { @parameter_name [ AS ][ type_schema_name. ] parameter_data_type [ = default ] [ READONLY ] } [ , . . . n ] ] ) RETURNS return_data_type [ WITH <function_option> [ , . . . n ] ] [ AS ] BEGIN function_body RETURN scalar_expression END [ ; ]

Аргументы • schema_name — Имя схемы, которой принадлежит функция. Функции привязаны к схеме. Если имя схемы не указано при создании функции, то автоматически назначается схема по умолчанию для пользователя, который создает функцию. • function_name — Имя функции. Имена функций должны соответствовать требованиям, предъявляемым к идентификаторам, и должны быть уникальными в схеме. • @parameter_name — Аргумент пользовательской функции. Может быть объявлен один или несколько аргументов. • parameter_data_type — Тип данных параметра (возможно, с указанием схемы, которой он принадлежит). Для функций Transact-SQL допустимы любые типы данных, включая определяемые пользователем типы данных CLR и определяемые пользователем табличные типы, за исключением типа данных timestamp.

• READONLY — Указывает, что параметр не может быть обновлен или изменен при определении функции. Если тип параметра является определяемым пользователем табличным типом, то должно быть указано ключевое слово READONLY. • return_data_type — Возвращаемое значение скалярной функции, определяемой пользователем. Для функций Transact-SQL допустимы любые типы данных, включая определяемые пользователем типы данных CLR, за исключением типа данных timestamp. • function_body — Указывает серию инструкций Transact-SQL, которая в совокупности не вызывает побочных эффектов (например, изменение содержимого таблиц) и формирует возвращаемое значение функции. function_body используется только в скалярных функциях и функциях, возвращающих табличное значение, из нескольких инструкций. • scalar_expression — Указывает скалярное значение, возвращаемое скалярной функцией. • WITH ENCRYPTION — в системном каталоге кодирует содержащую текст инструкции CREATE FUNCTION. информацию,
 RETURNS DECIMAL(16, 2) BEGIN DECLARE")
Примеры CREATE FUNCTION Compute. Costs (@percent INT = 10) RETURNS DECIMAL(16, 2) BEGIN DECLARE @add. Costs DEC (14, 2), @sum. Budget DEC(16, 2) SELECT @sum. Budget = SUM (Budget) FROM Project SET @add. Costs = @sum. Budget * @percent/100 RETURN @add. Costs END;

Вызов UDF USE Sample. Db; -SELECT Number, Project. Name FROM Project WHERE Budget < dbo. Compute. Costs(25); • Инструкция SELECT в примере отображает названия и номера всех проектов, бюджеты которых меньше, чем общие дополнительные расходы по всем проектам при заданном значении процентного увеличения. • В инструкциях Transact-SQL имена функций необходимо задавать, используя имена, состоящие из двух частей: schema name и function name, поэтому в примере мы использовали префикс схемы dbo.

• Определенную пользователем функцию можно вызывать с помощью инструкций Transact-SQL, таких как SELECT, INSERT, UPDATE или DELETE. • Вызов функции осуществляется, указывая ее имя с парой круглых скобок в конце, в которых можно задать один или несколько аргументов. • Аргументы — это значения или выражения, которые передаются входным параметрам, определяемым сразу же после имени функции. • При вызове функции, когда для ее параметров не определены значения по умолчанию, для всех этих параметров необходимо предоставить аргументы в том же самом порядке, в каком эти параметры определены в инструкции CREATE FUNCTION.
) RETURNS TABLE AS RETURN (SELECT First.")
CREATE FUNCTION Employees. In. Project (@project. Number CHAR(4)) RETURNS TABLE AS RETURN (SELECT First. Name, Last. Name FROM Works_on, Employee WHERE Employee. Id = Works_on. Emp. Id AND Project. Number = @project. Number) SELECT * FROM Employees. In. Project(‘p 3’)

Справка по UDF • http: //professorweb. ru/my/sqlserver/2012/level 3/3_3. php • https: //msdn. microsoft. com/ruru/library/ms 186755(v=sql. 105). aspx
Хранимая процедура
-
Храни́мая процеду́ра — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам. В хранимых процедурах могут выполняться стандартные операции с базами данных (как DDL, так и DML). Кроме того, в хранимых процедурах возможны циклы и ветвления, то есть в них могут использоваться инструкции управления процессом исполнения.
Хранимые процедуры похожи на определяемые пользователем функции (UDF). Основное различие заключается в том, что пользовательские функции можно использовать как и любое другое выражение в SQL запросе, в то время как хранимые процедуры должны быть вызваны с помощью функции CALL:
или
Хранимые процедуры могут возвращать множества результатов, то есть результаты запроса SELECT. Такие множества результатов могут обрабатываться, используя курсоры, другими сохранёнными процедурами, возвращая указатель результирующего множества, либо же приложениями. Хранимые процедуры могут также содержать объявленные переменные для обработки данных и курсоров, которые позволяют организовать цикл по нескольким строкам в таблице. Стандарт SQL предоставляет для работы выражения IF, LOOP, REPEAT, CASE и многие другие. Хранимые процедуры могут принимать переменные, возвращать результаты или изменять переменные и возвращать их, в зависимости от того, где переменная объявлена.
Реализация хранимых процедур варьируется от одной СУБД к другой. Большинство крупных поставщиков баз данных поддерживают их в той или иной форме. В зависимости от СУБД, хранимые процедуры могут быть реализованы на различных языках программирования, таких, как SQL, Java, C или C++. Хранимые процедуры, написанные не на SQL, могут самостоятельно выполнять SQL-запросы, а могут и не выполнять.
Всё более широкое использование хранимых процедур привело к появлению процедурных элементов в языке SQL стандарта SQL:1999 и SQL:2003 в части SQL/PSM. Это сделало SQL императивным языком программирования. Большинство СУБД предлагает собственные проприетарные и расширения производителя, сверх SQL/PSM.
Источник: Википедия
Связанные понятия
Объе́ктный мо́дуль (также — объектный файл, англ. object file) — файл с промежуточным представлением отдельного модуля программы, полученный в результате обработки исходного кода компилятором. Объектный файл содержит в себе особым образом подготовленный код (часто называемый двоичным или бинарным), который может быть объединён с другими объектными файлами при помощи редактора связей (компоновщика) для получения готового исполнимого модуля либо библиотеки.
Три́ггер (англ. trigger) — хранимая процедура особого типа, которую пользователь не вызывает непосредственно, а исполнение которой обусловлено действием по модификации данных: добавлением INSERT, удалением DELETE строки в заданной таблице, или изменением UPDATE данных в определённом столбце заданной таблицы реляционной базы данных.
Сервер баз данных (БД) выполняет обслуживание и управление базой данных и отвечает за целостность и сохранность данных, а также обеспечивает операции ввода-вывода при доступе клиента к информации.
Сериализация (в программировании) — процесс перевода какой-либо структуры данных в последовательность битов. Обратной к операции сериализации является операция десериализации (структуризации) — восстановление начального состояния структуры данных из битовой последовательности.
Интерпретируемый язык программирования — язык программирования, исходный код на котором выполняется методом интерпретации. Классифицируя языки программирования по способу исполнения, к группе интерпретируемых относят языки, в которых операторы программы друг за другом отдельно транслируются и сразу выполняются (интерпретируются) с помощью специальной программы-интерпретатора (что противопоставляется компилируемым языкам, в которых все операторы программы заранее оттранслированы в объектный код…
Упоминания в литературе
Третий раздел посвящен изучению технологий и методик моделирования ИС. Должен быть понятен алгоритм проектирования РИС с учетом требований CASE – и CALS – технологий, используемых за рубежом и российских аналогов. Специалист по РИС должен знать весь перечень стадий и этапов проектирования РИС. Для проектирования РИС необходимо уметь пользоваться современными инструментальными средствами разработки. Заканчивается курс лекций практическими примерами проектирования и разработки РИС в современной инструментальной среде Visual Studio 2005, 2010, при этом проектировщику достаточно знать основы событийно управляемого программирования и разработки Windows-приложения на языке C#. Разработка базы данных демонстрируется на примере СУБД SQL Server 2005, 2008. Важно и необходимо уяснить, как проектируется и создается удаленный запрос с клиентского приложения на сервер базы данных с помощью функций пользователя или хранимых процедур. Специалист по РИС должен в обязательном порядке выполнять фрагментацию и локализацию данных в распределенной базе данных.
Связанные понятия (продолжение)
Разделяемая память (англ. Shared memory) является самым быстрым средством обмена данными между процессами.
Удалённый вызов процедур, реже Вызов удалённых процедур (от англ. Remote Procedure Call, RPC) — класс технологий, позволяющих компьютерным программам вызывать функции или процедуры в другом адресном пространстве (как правило, на удалённых компьютерах). Обычно реализация RPC-технологии включает в себя два компонента: сетевой протокол для обмена в режиме клиент-сервер и язык сериализации объектов (или структур, для необъектных RPC). Различные реализации RPC имеют очень отличающуюся друг от друга архитектуру…
Компоновщик (также редактор связей, от англ. link editor, linker) — инструментальная программа, которая производит компоновку («линковку»): принимает на вход один или несколько объектных модулей и собирает по ним исполнимый модуль.
DLL (англ. Dynamic Link Library — «библиотека динамической компоновки», «динамически подключаемая библиотека») в операционных системах Microsoft Windows и IBM OS/2 — динамическая библиотека, позволяющая многократное использование различными программными приложениями. Эти библиотеки обычно имеют расширение DLL, OCX (для библиотек содержащих ActiveX), или DRV (для ряда системных драйверов). Формат файлов для DLL такой же, как для EXE-файлов Windows, т. е. Portable Executable (PE) для 32-битных и 64-битных…
Обмен сообщениями в информатике — один из подходов реализации взаимодействия компонентов и систем, используемый в параллельных вычислениях, объектно-ориентированном программировании, также — одна из форм межпроцессного взаимодействия в операционных системах, в микроядерных операционных системах подход используется для обмена информацией между одним из ядер и одним или более исполняющих блоков.
Файловый дескриптор — это неотрицательное целое число. Когда создается новый поток ввода-вывода, ядро возвращает процессу, создавшему поток ввода-вывода, его файловый дескриптор.
Среда выполнения (англ. execution environment, иногда «ранта́йм» от англ. runtime — «время выполнения») в информатике — вычислительное окружение, необходимое для выполнения компьютерной программы и доступное во время выполнения компьютерной программы. В среде выполнения, как правило, невозможно изменение исходного текста программы, но может наличествовать доступ к переменным окружения операционной системы, таблицам объектов и модулей разделяемых библиотек.
Конте́йнер в программировании — тип, позволяющий инкапсулировать в себе объекты других типов. Контейнеры, в отличие от коллекций, реализуют конкретную структуру данных.
Низкоуровневый язык программирования (язык программирования низкого уровня) — язык программирования, близкий к программированию непосредственно в машинных кодах используемого реального или виртуального (например, байт-код, Microsoft .NET) процессора. Для обозначения машинных команд обычно применяется мнемоническое обозначение. Это позволяет запоминать команды не в виде последовательности двоичных нулей и единиц, а в виде осмысленных сокращений слов человеческого языка (обычно английских).
Сопрограммы (англ. coroutines) — методика связи программных модулей друг с другом по принципу кооперативной многозадачности: модуль приостанавливается в определённой точке, сохраняя полное состояние (включая стек вызовов и счётчик команд), и передаёт управление другому. Тот, в свою очередь, выполняет задачу и передаёт управление обратно, сохраняя свои стек и счётчик.
Подробнее: Сопрограмма
Макрокоманда, макроопределение или мáкрос — программный алгоритм действий, записанный пользователем. Часто макросы применяют для выполнения рутинных действий. А также макрос — это символьное имя в шаблонах, заменяемое при обработке препроцессором на последовательность символов, например: фрагмент html-страницы в веб-шаблонах, или одно слово из словаря синонимов в синонимизаторах.
Бизнес-логика — в разработке информационных систем — совокупность правил, принципов, зависимостей поведения объектов предметной области (области человеческой деятельности, которую система поддерживает). Иначе можно сказать, что бизнес-логика — это реализация правил и ограничений автоматизируемых операций. Является синонимом термина «логика предметной области» (англ. domain logic). Бизнес-логика задает правила, которым подчиняются данные предметной области.
Кодогенерация — часть процесса компиляции, когда специальная часть компилятора, кодогенератор, конвертирует синтаксически корректную программу в последовательность инструкций, которые могут выполняться на машине. При этом могут применяться различные, в первую очередь машинно-зависимые оптимизации. Часто кодогенератор является общей частью для множества компиляторов. Каждый из них генерирует промежуточный код, который подаётся на вход кодогенератору.
Репликация (англ. replication) — механизм синхронизации содержимого нескольких копий объекта (например, содержимого базы данных). Репликация — это процесс, под которым понимается копирование данных из одного источника на другой (или на множество других) и наоборот.
Межпроцессное взаимодействие (англ. inter-process communication, IPC) — обмен данными между потоками одного или разных процессов. Реализуется посредством механизмов, предоставляемых ядром ОС или процессом, использующим механизмы ОС и реализующим новые возможности IPC. Может осуществляться как на одном компьютере, так и между несколькими компьютерами сети.
Байт-код (байтко́д; англ. bytecode, также иногда p-код, p-code от portable code) — стандартное промежуточное представление, в которое может быть переведена компьютерная программа автоматическими средствами. По сравнению с исходным кодом, удобным для создания и чтения человеком, байт-код — это компактное представление программы, уже прошедшей синтаксический и семантический анализ. В нём в явном виде закодированы типы, области видимости и другие конструкции. С технической точки зрения, байт-код представляет…
Исполняемый файл (англ. executable file, также выполняемый, реже исполнимый, выполнимый) — файл, содержащий программу в виде, в котором она может быть исполнена компьютером. Перед исполнением программа загружается в память, и выполняются некоторые подготовительные операции (настройка окружения, загрузка библиотек).
Реляционная система управления базами данных (РСУБД), реже — система управления реляционными базами данных (СУРБД) — СУБД, управляющая реляционными базами данных.
Компилируемый язык программирования — язык программирования, исходный код которого преобразуется компилятором в машинный код и записывается в файл с особым заголовком и/или расширением для последующей идентификации этого файла, как исполняемого операционной системой (в отличие от интерпретируемых языков программирования, чьи программы выполняются программой-интерпретатором).
Событи́йно-ориенти́рованное программи́рование (англ. event-driven programming; в дальнейшем СОП) — парадигма программирования, в которой выполнение программы определяется событиями — действиями пользователя (клавиатура, мышь), сообщениями других программ и потоков, событиями операционной системы (например, поступлением сетевого пакета).
Кросс-компиля́тор (англ. cross compiler) — компилятор, производящий исполняемый код для платформы, отличной от той, на которой исполняется сам кросс-компилятор. Такой инструмент бывает полезен, когда нужно получить код для платформы, экземпляров которой нет в наличии, или в случаях когда компиляция на целевой платформе невозможна или нецелесообразна (например, это касается мобильных систем или микроконтроллеров с минимальным объёмом памяти).
Сокеты Беркли — интерфейс программирования приложений (API), представляющий собой библиотеку для разработки приложений на языке C с поддержкой межпроцессного взаимодействия (IPC), часто применяемый в компьютерных сетях.
В программировании термин «директива» (указание) по использованию похож на термин «команда», так как также используется для описания некоторых конструкций языка программирования (то есть указаний компилятору или ассемблеру особенностей обработки при компиляции).
Мо́дульное программи́рование — это организация программы как совокупности небольших независимых блоков, называемых модулями, структура и поведение которых подчиняются определённым правилам. Использование модульного программирования позволяет упростить тестирование программы и обнаружение ошибок. Аппаратно-зависимые подзадачи могут быть строго отделены от других подзадач, что улучшает мобильность создаваемых программ.
Механизм копирования при записи (англ. Copy-On-Write, COW) используется для оптимизации многих процессов, происходящих в операционной системе, таких как, например, работа с оперативной памятью или файлами на диске (пример — ext3cow).
При́месь (англ. mix in) — элемент языка программирования (обычно класс или модуль), реализующий какое-либо чётко выделенное поведение. Используется для уточнения поведения других классов, не предназначен для порождения самостоятельно используемых объектов.
Дизассе́мблер (от англ. disassembler ) — транслятор, преобразующий машинный код, объектный файл или библиотечные модули в текст программы на языке ассемблера.
Соглашение о вызове (англ. calling convention) — описание технических особенностей вызова подпрограмм, определяющее…
Код операции, операционный код, опкод — часть машинного языка, называемая инструкцией и определяющая операцию, которая должна быть выполнена.
Стандартные потоки ввода-вывода в системах типа UNIX (и некоторых других) — потоки процесса, имеющие номер (дескриптор), зарезервированный для выполнения некоторых «стандартных» функций. Как правило (хотя и не обязательно), эти дескрипторы открыты уже в момент запуска задачи (исполняемого файла).
Динамическая идентификация типа данных (англ. run-time type information, run-time type identification, RTTI) — механизм в некоторых языках программирования, который позволяет определить тип данных переменной или объекта во время выполнения программы.
Рефа́кторинг (англ. refactoring), или перепроектирование кода, переработка кода, равносильное преобразование алгоритмов — процесс изменения внутренней структуры программы, не затрагивающий её внешнего поведения и имеющий целью облегчить понимание её работы. В основе рефакторинга лежит последовательность небольших эквивалентных (то есть сохраняющих поведение) преобразований. Поскольку каждое преобразование маленькое, программисту легче проследить за его правильностью, и в то же время вся последовательность…
Стати́ческий ана́лиз ко́да (англ. static code analysis) — анализ программного обеспечения, производимый (в отличие от динамического анализа) без реального выполнения исследуемых программ. В большинстве случаев анализ производится над какой-либо версией исходного кода, хотя иногда анализу подвергается какой-нибудь вид объектного кода, например P-код или код на MSIL. Термин обычно применяют к анализу, производимому специальным программным обеспечением (ПО), тогда как ручной анализ называют «program…
Многопото́чность — свойство платформы (например, операционной системы, виртуальной машины и т. д.) или приложения, состоящее в том, что процесс, порождённый в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно», то есть без предписанного порядка во времени. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
Сервер приложений (англ. application server) — это программная платформа (фреймворк), предназначенная для эффективного исполнения процедур (программ, скриптов), на которых построены приложения. Сервер приложений действует как набор компонентов, доступных разработчику программного обеспечения через API (интерфейс прикладного программирования), определённый самой платформой.
Динамическое распределение памяти — способ выделения оперативной памяти компьютера для объектов в программе, при котором выделение памяти под объект осуществляется во время выполнения программы.
Защита памяти (англ. Memory protection) — это способ управления правами доступа к отдельным регионам памяти. Используется большинством многозадачных операционных систем. Основной целью защиты памяти является запрет доступа процессу к той памяти, которая не выделена для этого процесса. Такие запреты повышают надёжность работы как программ, так и операционных систем, так как ошибка в одной программе не может повлиять непосредственно на память других приложений. Следует различать общий принцип защиты…
Шебанг (англ. shebang, sha-bang, hashbang, pound-bang, or hash-pling) — в программировании последовательность из двух символов: решётки и восклицательного знака («#!») в начале файла скрипта.
Монтирование файловой системы — системный процесс, подготавливающий раздел диска к использованию операционной системой.
Модульное тестирование, или юнит-тестирование (англ. unit testing) — процесс в программировании, позволяющий проверить на корректность отдельные модули исходного кода программы, наборы из одного или более программных модулей вместе с соответствующими управляющими данными, процедурами использования и обработки.
Динамический сайт — сайт, состоящий из динамичных страниц — шаблонов, контента, скриптов и прочего, в большинстве случаев в виде отдельных файлов (в Lotus Notes/Domino данные и все элементы дизайна, включая пользовательские скрипты, хранятся в одном файле).
Система управления версиями (от англ. Version Control System, VCS или Revision Control System) — программное обеспечение для облегчения работы с изменяющейся информацией. Система управления версиями позволяет хранить несколько версий одного и того же документа, при необходимости возвращаться к более ранним версиям, определять, кто и когда сделал то или иное изменение, и многое другое.
Служба каталогов в контексте компьютерных сетей — программный комплекс, позволяющий администратору работать с упорядоченным по ряду признаков массивом информации о сетевых ресурсах (общие папки, серверы печати, принтеры, пользователи и т. д.), хранящимся в едином месте, что обеспечивает централизованное управление как самими ресурсами, так и информацией о них, а также позволяющий контролировать использование их третьими лицами.
Безопасность доступа к памяти — концепция в разработке программного обеспечения, целью которой является избежание программных ошибок, которые ведут к уязвимостям, связанным с доступом к оперативной памяти компьютера, таким как переполнения буфера и висячие указатели.
Вы готовитесь к собеседованию по SQL? Тогда вы пришли в нужное место!
Это руководство поможет вам усовершенствовать свои навыки работы с SQL, вернуть уверенность в себе и быть готовым к работе!
Здесь вы найдёте подборку реальных вопросов для собеседований, задаваемых в таких компаниях, как Google, Oracle, Amazon, Microsoft и т.д. К каждому вопросу прилагается идеально написанный ответ, что экономит ваше время на подготовку к собеседованию.
Здесь также рассматриваются практические задачи, которые помогут вам понять основные концепции SQL.
Мы разделили эту статью на следующие разделы:
- Вопросы для собеседования по SQL
- Вопросы для собеседования по PostgreSQL
Вопросы для собеседования по SQL
1. Что такое база данных?
База данных — это совокупность данных, хранящихся и извлекаемых в цифровом виде из удалённой или локальной компьютерной системы.
2. Что такое СУБД?
СУБД расшифровывается как Система Управления Базами Данных. СУБД — это системное программное обеспечение, ответственное за создание, поиск, обновление базы данных и управление ею. Она гарантирует, что наши данные организованы и легкодоступны, выступая в качестве интерфейса между базой данных и её конечными пользователями.
3. Что такое Реляционная СУБД? В чём заключается её отличие от СУБД?
РСУБД расшифровывается как Реляционная Система Управления Базами Данных. Ключевое отличие здесь, по сравнению с СУБД, заключается в том, что РСУБД хранит данные в виде набора таблиц, и между общими полями этих таблиц могут существовать отношения. Большинство современных систем управления базами данных, таких как MySQL, Microsoft SQL Server, Oracle, IBM DB2 и Amazon Redshift, основаны на РСУБД.
4. Что такое SQL?
SQL расшифровывается как язык структурированных запросов. Это стандартный язык для РСУБД. Он особенно полезен при обработке организованных данных, состоящих из сущностей (переменных) и отношений между различными сущностями данных.
5. В чём разница между SQL и MySQL?
SQL — это стандартный язык для извлечения структурированных баз данных и управления ими. Напротив, MySQL — это система управления реляционными базами данных, подобная SQL Server, Oracle или IBM DB2, которые используется для управления базами данных SQL.
6. Что такое таблицы и поля?
Таблица — это организованный набор данных, хранящихся в виде строк и столбцов. Столбцы могут быть классифицированы как вертикальные поля, а строки — как горизонтальные. Поля — это колонки в таблице, которые предназначены для хранения какой-либо информации.
7. Что такое ограничения в SQL?
Ограничения используются для указания правил, касающихся данных в таблице. Они могут быть применены к одному или нескольким полям в таблице SQL во время создания таблицы или после создания с помощью команды ALTER TABLE. Ограничениями являются:
- NOT NULL — ограничивает вставку нулевого значения в столбец.
- CHECK — проверяет, что все значения в поле удовлетворяют условие.
- DEFAULT — автоматически присваивает значение по умолчанию, если для поля не было указано значение.
- UNIQUE — гарантирует, что в поле будут вставлены уникальные значения.
- INDEX — индексирует поле, обеспечивая более быстрый поиск записей.
- PRIMARY KEY — уникально идентифицирует каждую запись в таблице.
- FOREIGN KEY — обеспечивает ссылочную целостность для записи в другой таблице.
8. Что такое PRIMARY KEY?
Ограничение PRIMARY KEY уникально идентифицирует каждую строку в таблице. Оно должно содержать UNIQUE значения и иметь неявное ограничение NOT NULL.Таблица в SQL строго ограничена наличием одного и только одного PRIMARY KEY, который состоит из одного или нескольких полей (столбцов).
CREATE TABLE Students ( /* Create table with a single field as primary key */
ID INT NOT NULL
Name VARCHAR(255)
PRIMARY KEY (ID)
);
CREATE TABLE Students ( /* Create table with multiple fields as primary key */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL,
CONSTRAINT PK_Student
PRIMARY KEY (ID, FirstName)
);
ALTER TABLE Students /* Set a column as primary key */
ADD PRIMARY KEY (ID);
ALTER TABLE Students /* Set multiple columns as primary key */
ADD CONSTRAINT PK_Student /*Naming a Primary Key*/
PRIMARY KEY (ID, FirstName);
9. Что такое UNIQUE?
Ограничение UNIQUE гарантирует, что все значения в столбце будут разными. Это обеспечивает уникальность столбца (ов) и помогает однозначно идентифицировать каждую строку. В отличие от PRIMARY KEY, для каждой таблицы может быть определено несколько уникальных ограничений. Синтаксис кода для UNIQUE очень похож на синтаксис PRIMARY KEY:
CREATE TABLE Students ( /* Create table with a single field as unique */
ID INT NOT NULL UNIQUE
Name VARCHAR(255)
);
CREATE TABLE Students ( /* Create table with multiple fields as unique */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL
CONSTRAINT PK_Student
UNIQUE (ID, FirstName)
);
ALTER TABLE Students /* Set a column as unique */
ADD UNIQUE (ID);
ALTER TABLE Students /* Set multiple columns as unique */
ADD CONSTRAINT PK_Student /* Naming a unique constraint */
UNIQUE (ID, FirstName);
10. What is a Foreign K
10. Что такое FOREIGN KEY?
FOREIGN KEY состоит из одного поля или набора полей в таблице, которые ссылаются на PRIMARY KEY в другой таблице. Данное ограничение обеспечивает ссылочную целостность в отношении между двумя таблицами.Таблица с FOREIGN KEY помечена как дочерняя таблица, а таблица, содержащая PRIMARY KEY, помечена как родительская таблица.
CREATE TABLE Students ( /* Create table with foreign key — Way 1 */
ID INT NOT NULL
Name VARCHAR(255)
LibraryID INT
PRIMARY KEY (ID)
FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
CREATE TABLE Students ( /* Create table with foreign key — Way 2 */
ID INT NOT NULL PRIMARY KEY
Name VARCHAR(255)
LibraryID INT FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
ALTER TABLE Students /* Add a new foreign key */
ADD FOREIGN KEY (LibraryID)
REFERENCES Library (LibraryID);
11. Что такое объединение?
SQL Join (объединение) используется для объединения записей (строк) из двух или более таблиц в базе данных SQL на основе связанного столбца между ними.
12. Что такое Self-Join?
Self-Join — это «самосоединение», объединение внутри одной таблицы. Оно используется тогда, когда у разных полей одной таблицы могут быть одинаковые значения.
SELECT A.emp_id AS «Emp_ID»,A.emp_name AS «Employee»,
B.emp_id AS «Sup_ID»,B.emp_name AS «Supervisor»
FROM employee A, employee B
WHERE A.emp_sup = B.emp_id;
13. Что такое перекрёстное соединение?
Во время перекрёстного соединения каждая строка одной таблицы соединяется с каждой строкой второй таблицы, давая тем самым в результате все возможные сочетания строк двух таблиц.
14. Что такое индекс?
Индексы — это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные. Они расположены в самой таблице и являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным оптимальным способом.
15. Какие существуют виды индексов?
Индексы бывают нескольких типов:
- Уникальный и неуникальный индекс:
Уникальные индексы — это индексы, которые помогают поддерживать целостность данных, гарантируя, что никакие две строки данных в таблице не имеют идентичных значений.
Неуникальные индексы не используются для применения ограничений к таблицам, с которыми они связаны. Вместо этого, неуникальные индексы используются исключительно для повышения производительности запросов за счет поддержания отсортированного порядка значений данных, которые часто используются.
- Кластеризованные и некластеризованные индексы
Кластеризованные индексы — это индексы, порядок строк в базе данных которых соответствует порядку строк в индексе. Вот почему в данной таблице может существовать только один кластеризованный индекс.
Некластеризованные индексы имеют структуру, отдельную от строк данных. В некластеризованном индексе содержатся значения ключа некластеризованного индекса, и каждая запись значения ключа содержит указатель на строку данных, содержащую значение ключа.
16. В чём разница между кластеризованными и некластеризованными индексами?
Основное различие между кластеризованным и некластеризованным индексом состоит в том, что кластеризованный индекс определяет, как данные хранятся в строках таблицы. С другой стороны, некластеризованный индекс хранит данные в одном месте, а индексы хранятся в другом месте.
17. Что такое целостность данных?
Целостность данных-это поддержание и обеспечение точности и согласованности данных на протяжении всего их жизненного цикла. Является критическим аспектом проектирования, внедрения и использования любой системы, которая хранит, обрабатывает или извлекает данные.
18. Что такое запросы в SQL?
SQL-запросы необходимы для работы с информацией из базы данных. Это может быть внесение, извлечение, сортировка, удаление и ряд других операций. При этом не указывается способ осуществления запрашиваемого действия.
19. Что такое подзапросы в SQL?
Подзапрос — это запрос внутри другого запроса, также известный как вложенный запрос или внутренний запрос. Он используется для ограничения или улучшения данных, запрашиваемых основным запросом, тем самым ограничивая или улучшая выходные данные основного запроса.
Существует два типа подзапросов — коррелированные и некоррелированные.
20. Что такое оператор SELECT?
Оператор SELECT в SQL используется для выбора данных из базы данных. Возвращаемые данные сохраняются в таблице результатов, называемой результирующим набором.
21. Зачем нужны операторы UNION, MINUS и INTERSECT?
Оператор UNION отвечает за объединение строк из обоих подзапросов;
Оператор MINUS отвечает за вычитание результатов одного подзапроса из результатов второго подзапроса;
Оператор INTERSECT отвечает за пересечение строк из обоих подзапросов.
Перед выполнением любого из приведенных выше инструкций в SQL, необходимо выполнить определенные условия:
- Каждый оператор SELECT в предложении должен иметь одинаковое количество столбцов;
- Столбцы также должны иметь аналогичные типы данных;
- Столбцы в каждой инструкции SELECT обязательно должны иметь одинаковый порядок.
22. Что такое курсор?
Курсор в SQL – это область в памяти базы данных, которая предназначена для хранения последнего оператора SQL. Если текущий оператор – запрос к базе данных, в памяти сохраняется и строка данных запроса, называемая текущим значением, или текущей строкой курсора.
23. Что такое сущности и отношения?
Сущность (entity) представляет тип объектов, которые должны храниться в базе данных. Каждая таблица в базе данных должна представлять одну сущность. Как правило, сущности соответствуют объектам из реального мира. У каждой сущности определяют набор атрибутов.
Отношения — это установленные связи между двумя или более таблицами. Отношения основаны на общих полях из более чем одной таблицы, часто связанных с первичными и иностранными ключами.
24. Перечислите различные типы связей в SQL.
- One-to-One — этот тип может быть определён как отношение между двумя таблицами, где каждая запись в одной таблице связана максимум с одной записью в другой таблице.
- One-to-Many & Many-to-One — это наиболее часто используемое отношение, когда запись в таблице связана с несколькими записями в другой таблице.
- Many-to-Many — этот тип используется в случаях, когда для определения отношения требуется несколько экземпляров с обеих сторон.
- Self-Referencing Relationships — этот тип используется, когда таблице необходимо определить связь с самой собой.
25. Что такое Alias в SQL?
Alias (псевдоним) — это имя, назначенное источнику данных в запросе при использовании выражения в качестве источника данных или для упрощения ввода и прочтения инструкции SQL. Такая возможность полезна, если имя источника данных слишком длинное или его трудно вводить. Псевдонимы могут быть использованы для переименования таблиц и колонок.
26. Что такое представление?
Представление в SQL — это виртуальная таблица, основанная на наборе результатов инструкции SQL. Представление содержит строки и столбцы, точно так же, как настоящая таблица. Поля в представлении — это поля из одной или нескольких реальных таблиц в базе данных.
27. Что такое нормализация?
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
28. Что такое денормализация?
Денормализация — это обратный процесс нормализации, при котором нормализованная схема преобразуется в схему, содержащую избыточную информацию. Производительность повышается за счет использования избыточности и обеспечения согласованности избыточных данных. Причиной выполнения денормализации являются накладные расходы, возникающие в процессоре запросов из-за чрезмерно нормализованной структуры.
29. Что такое подстановочные знаки?
Это специальные символы, которые нужны для замены каких-либо знаков в запросе. Они используются вместе с оператором LIKE, с помощью которого можно отфильтровать запрашиваемые данные.
30. Зачем нужны операторы TRUNCATE, DELETE и DROP?
TRUNCATE удаляет все строки из таблицы.
Команда DELETE используется для удаления одной или всех строк в таблице.
Команда DROP удаляет таблицу из базы данных. Все строки таблицы, индексы и привилегии удаляются.
31. В чём разница между операторами DROP и TRUNCATE?
Команда DROP удаляет таблицу из базы данных целиком, вместе со структурой. То есть после выполнения такой команды обратиться к удаленной таблице, например с помощью SELECT, будет уже нельзя. В свою очередь команда TRUNCATE удаляет не саму таблицу, а данные, которые эта таблица содержит.
32. В чём разница между операторами DELETE и TRUNCATE?
Операция DELETE блокирует каждую строку, а TRUNCATE — всю таблицу. Операция TRUNCATE не возвращает какого-то осмысленного значения (обычно возвращает 0) в отличие от DELETE, которая возвращает число удаленных строк. Также стоит заметить, что при использовании TRUNCATE, операцию удаления уже нельзя будет отменить.
33. Что такое агрегатные и скалярные функции?
Агрегатная функция выполняет вычисление над набором значений и возвращает одно значение. В табличной модели данных это значит, что функция берет ноль, одну или несколько строк для какой-то колонки и возвращает единственное значение. Для сравнения — скалярные функции принимают на вход одно значение и возвращают одно значение.
Примеры агрегатных функций:
- AVG() — Функция вычисляет среднее значение
- MAX() — Функция вычисляет элемент с максимальным значением
- MIN() — Функция вычисляет элемент с минимальным значением
- SUM() — Функция суммирует значения
Примеры скалярных функций:
- LEN() — Функция вычисляет общую длину поля
- MID() — Функция извлекает подстроки из набора строковых значений в таблице
- RAND() — Функция генерирует случайный набор чисел заданной длины
- NOW() — Функция возвращает текущую дату и время
34. Что такое определяемая пользователем функция?
Определяемая пользователем функция — это подпрограмма, которая принимает параметры, выполняет действие и возвращает результат в виде одного скалярного значения или результирующий набор.
35. Что такое OLTP?
OLTP — это транзакционные системы, то есть системы, ориентированные на быстрое добавление транзакций (операций) и, возможно, их изменения.
36. В чём различия между OLTP и OLAP?
OLTP-это система обработки транзакций, то есть она управляет приложениями, основанными на транзакциях, через Интернет. Например, системы OLTP отвечают за предоставление данных в хранилища данных. С другой стороны, OLAP-это система аналитической обработки. Это означает, что она отвечает на многомерные аналитические запросы, соответствующие финансовой отчетности, прогнозированию и т.д. Например, данные, доступные в хранилище данных, анализируются с помощью OLAP-системы.
37. Что такое сопоставление?
Сопоставление в SQL — это ряд правил, согласно которым сортируются и сравниваются данные. Эти правила определяют порядок сортировки символьных данных, в зависимости от регистра, надстрочных знаков (акцента), символьных типов Kana, ширины символов.
38. Что такое хранимая процедура?
Хранимая процедура — это объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам.
39. Что такое рекурсивная хранимая процедура?
Рекурсивная хранимая процедура — это хранимая процедура, которая вызывает сама себя.
40. Как создать пустые таблицы с той же структурой, что и у другой таблицы?
Создание пустых таблиц с одинаковой структурой может быть выполнено путём извлечения записей из одной таблицы в новую таблицу с помощью оператора INTO, установив при этом значение WHERE для всех записей равным false. Следовательно, SQL подготавливает новую таблицу с повторяющейся структурой для приема извлечённых записей, но поскольку никакие записи не извлекаются из-за действия предложения WHERE, в новую таблицу ничего не вставляется.
SELECT * INTO Students_copy FROM Students WHERE 1 = 2;
41. Что такое сопоставление шаблонов в SQL?
Сопоставление шаблонов SQL позволяет искать шаблоны в данных, если вы не знаете точное слово или фразу, которую ищете. Этот тип SQL — запроса использует подстановочные знаки для соответствия шаблону, а не точное его указание. Например, вы можете использовать подстановочный знак «C%» для соответствия любой строке, начинающейся с заглавной С .
SELECT * FROM students WHERE first_name LIKE ‘K%’
Вопросы для собеседования по PostgreSQL
42. Что такое PostgreSQL?
PostgreSQL — это реляционная база данных с открытым кодом, которая поддерживается в течение 30 лет разработки и является одной из наиболее известных среди всех существующих реляционных баз данных.
43. Как определять индексы в PostgreSQL?
Индексы — это встроенные функции в PostgreSQL, которые используются запросами для более эффективного выполнения поиска по таблице в базе данных. Предположим, что у вас есть таблица с тысячами записей, и у вас есть приведённый ниже запрос, согласно которому только несколько записей могут удовлетворять условию, тогда потребуется много времени для поиска и возврата тех строк, которые соответствуют этому условию. Это, несомненно, неэффективно для системы, имеющей дело с огромными данными. Теперь, если бы у этой системы был индекс столбца, в котором мы применяем поиск, она могла бы использовать эффективный метод для определения совпадающих строк, пройдя всего несколько уровней. Это называется индексацией.
Select * from some_table where table_col=120
44. Как изменить тип данных столбца?
Это можно сделать с помощью инструкции ALTER TABLE, как показано ниже:
ALTER TABLE tname ALTER COLUMN col_name [SET DATA] TYPE new_data_type;
45. Какая команда используется для создания базы данных в PostgreSQL?
Первым шагом использования PostgreSQL является создание базы данных. Это делается с помощью команды createdb, как показано ниже: createdb db_name
CREATE DATABASE
46. Как запустить, перезапустить или остановить сервер PostgreSQL?
Чтобы запустить сервер PostgreSQL, мы используем:
service postgresql start
Чтобы перезапустить сервер PostgreSQL, мы используем:
service postgresql restart
Чтобы остановить сервер PostgreSQL, мы используем:
service postgresql stop
47. Что такое секционирование таблицы в PostgreSQL?
Секционированием данных называется разбиение одной большой логической таблицы на несколько меньших физических секций.
48. Что такое токен в PostgreSQL?
Токеном в PostgreSQL может являться ключевое слово, идентификатор, литерал, константа, идентификатор в кавычках, либо любой символ, обладающий отличительной индивидуальностью. Они могут быть разделены пробелом, новой строкой или табуляцией. Если токены являются ключевыми словами, то обычно это команды с полезными значениями. Токены известны как строительные блоки любого кода PostgreSQL
49. В чём важность оператора TRUNCATE?
Оператор TRUNCATE TABLE name_of_table эффективно и быстро удаляет данные из таблицы.Оператор TRUNCATE также может быть использован для сброса значений столбцов идентификаторов вместе с очисткой данных, как показано ниже:
TRUNCATE TABLE name_of_table RESTART IDENTITY;
50. Какова максимальная ёмкость таблицы в PostgreSQL?
Максимальный размер таблицы PostgreSQL может составлять 32 ТБ.
51. Что такое последовательность?
Последовательность представляет собой объект, используемый для автоматического формирования чисел для различных целей, например для ключей.
52. Что такое строковые константы в PostgreSQL?
Строковые константы представляют собой последовательности символов, заключенные в одинарные кавычки. Они используются при вставке данных или обновлении символов в базе данных.Существуют специальные строковые константы, которые указаны в долларах. Синтаксис: $tag$$tag$ Тег в константе необязателен, и когда мы не указываем тег, константа называется строковым литералом с двойным долларом.
53. Как можно получить список всех баз данных в PostgreSQL?
Это можно сделать с помощью команды \l ( обратная слеш, за которым следует строчная буква L).
54. Как удалить базу данных в PostgreSQL?
Это можно сделать с помощью команды DROP DATABASE, как показано ниже:
DROP DATABASE database_name;
Если база данных была удалена успешно, то будет показано следующее сообщение:
DROP DATABASE
55. Что такое ACID?
Это свойства транзакции базы данных, которые используются для обеспечения достоверности данных в случае ошибок и сбоев.
56. Можете ли вы объяснить архитектуру PostgreSQL?
Архитектура PostgreSQL соответствует модели клиент-сервер.
Серверная часть состоит из диспетчера фоновых процессов, обработчика запросов, утилит и общего пространства памяти, которые работают вместе для создания экземпляра PostgreSQL, имеющего доступ к данным. Клиентское приложение выполняет задачу подключения к этому экземпляру и запрашивает обработку данных у служб. Клиентом может быть либо GUI (графический пользовательский интерфейс), либо веб-приложение. Наиболее часто используемым клиентом для PostgreSQL является pgAdmin.
57. Что вы понимаете под управлением параллелизмом нескольких версий?
Под управлением параллелизмом подразумевают различные техники, которые используются для сохранения целостности базы данных, когда несколько пользователей обновляют строки одновременно. Неверный параллелизм может привести к проблемам, таким как чтение фантомных данных, чтение недействительных данных и неповторяемые чтения.
58. Зачем нужна команда enable-debug?
Команда enable-debug используется для включения компиляции всех библиотек и приложений. Когда она включено, системные процессы затрудняются и, как правило, увеличивают размер двоичного файла. Следовательно, не рекомендуется использовать её в производственной среде. Чаще всего она используется разработчиками для отладки ошибок в своих скриптах и помогает им выявлять проблемы.
59. Какие существуют операторы в PostgreSQL?
Операторы PostgreSQL включают в себя арифметические операторы, операторы сравнения, логические операторы и побитовые операторы.
60. Что вы можете сказать о WAL (ведение журнала с опережением записи)?
Ведение журнала с опережением записи (WAL)-это стандартный метод обеспечения целостности данных. Подробное описание можно найти в большинстве (если не во всех) книг об обработке транзакций. Вкратце, центральная концепция WAL заключается в том, что изменения в файлах данных (где находятся таблицы и индексы) должны быть записаны только после того, как эти изменения были зарегистрированы, то есть после того, как записи журнала, описывающие изменения, были сброшены в постоянное хранилище.
61. В чем заключается основной недостаток удаления данных из существующей таблицы с помощью команды DROP TABLE?
Хотя команда DROP TABLE позволяет полностью удалить данные из существующей таблицы, у не` есть недостаток — она удаляет полную структуру таблицы из базы данных. Из-за этого нам нужно заново создать таблицу для хранения данных.
62. Как выполнить сопоставление без учёта регистра с использованием регулярных выражений в PostgreSQL?
Чтобы выполнить сопоставления без учета регистра с использованием регулярного выражения, мы можем использовать выражение POSIX (~*) из операторов сопоставления с образцом. Например:
‘interviewbit’ ~* ‘.*INTervIewBit.*’
63. Как сделать резервную копию базы данных в PostgreSQL?
Мы можем достичь этого, используя инструмент pg_dump для сброса всего содержимого объекта в базе данных в один файл. Вот несколько шагов:
Шаг 1: Перейдите в папку bin по пути установки PostgreSQL.
C:\>cd C:\Program Files\PostgreSQL\10.0\bin
Шаг 2: Запустите программу pg_dump, чтобы перенести дамп данных в папку .tar, как показано ниже:
pg_dump -U postgres -W -F t sample_data > C:\Users\admin\pgbackup\sample_data.tar
Дамп базы данных будет сохранен в файле sample_data.tar в указанном расположении.
64. Поддерживает ли PostgreSQL полнотекстовый поиск?
Полнотекстовый поиск — это метод поиска одного документа или коллекции документов, хранящихся на компьютере, в полнотекстовой базе данных. В основном он поддерживается в продвинутых системах баз данных, таких как SOLR или ElasticSearch. Тем не менее, эта функция присутствует, но довольно проста в PostgreSQL.
65. Что такое параллельные запросы в PostgreSQL?
Параллельные запросы в PostgreSQL имеют возможность использовать более одного ядра процессора для каждого запроса.В параллельных запросах оптимизатор разбивает задачи запроса на более мелкие части и распределяет каждую задачу по нескольким ядрам процессора.
66. В чём разница между commit и checkpoint?
Действие commit обеспечивает сохранение согласованности данных транзакции и завершает текущую транзакцию в разделе. Commit добавляет в журнал новую запись, описывающую фиксацию в памяти. Checkpoint используется для записи всех изменений, которые были зафиксированы на диске, вплоть до SCN, которые будут храниться в заголовках файлов данных и файлах управления.
Заключение
SQL — это язык для работы с базой данных. Он обладает обширными и надёжными возможностями для создания различных объектов базы данных и управления ими с помощью таких команд, как CREATE, ALTER, DROP и т.д., А также загрузки объектов базы данных с помощью таких команд, как INSERT. Он также предоставляет опции для манипулирования данными с помощью таких команд, как DELETE, TRUNCATE, а ещё обеспечивает эффективное извлечение данных с помощью команд курсора, таких как FETCH, SELECT и т.д. Существует множество команд, которые предоставляют программисту большой объем контроля для эффективного взаимодействия с базой данных, не тратя впустую много ресурсов. Популярность SQL выросла настолько, что почти каждый программист полагается на него для реализации функций хранения данных в своих приложениях, что делает SQL полезным языком для изучения. Изучение этого даёт разработчику преимущество в понимании структур данных, используемых для хранения данных организации, и обеспечивает дополнительный уровень контроля и углубленного понимания приложения.
PostgreSQL, в свою очередь, являющаяся системой баз данных с открытым исходным кодом, обладающая чрезвычайно надежной и сложной поддержкой ACID, индексацией и транзакцией, завоевала широкую популярность среди сообщества разработчиков.
Статья взята из следующего источника:
Объекты реляционной базы данных
Иерархия объектов реляционной базы данных
Одной из главных задач, которые обязан решить проектировщик на стадии проектирования физической модели реляционной базы данных, является задача превращения объектов логической модели реляционной базы данных в объекты реляционной базы данных. Для решения этой задачи проектировщику базы данных необходимо знать: а) какими объектами располагает реляционная база данных в принципе; б) какие объекты поддерживает конкретная СУБД, которая выбрана для реализации базы данных.
Таким образом, мы предполагаем, что решение о выборе СУБД уже принято руководителем ИТ-проекта, и согласовано с заказчиком базы данных, т.е. СУБД задана. Проектировщик базы данных должен ознакомиться с документацией, в которой описан диалект SQL, поддерживаемый выбранной СУБД. В настоящей лекции предполагается, что была выбрана СУБД Oracle 9i, хотя подавляющая часть материала охватывает объекты в любой промышленной реляционной СУБД.
Замечание. О выборе СУБД. Выбор СУБД относится к многокритериальной задаче выбора и в настоящем курсе не рассматривается. Следует помнить о том, что СУБД обычно поддерживает только одну модель данных: реляционную, иерархическую, сетевую, многомерную, объектно-ориентированную, объектно-реляционную. Исключение составляют небольшое число СУБД. Например, ADABAS, Software AG (сетевая и реляционная модели), или Oracle 9i, Oracle Inc. (реляционная и объектно-реляционная модели). Обычно при выборе СУБД при всех прочих равных возможностях стараются создать базу данных на СУБД, претендующей на промышленный стандарт.
Иерархия объектов реляционной базы данных прописана в стандартах по SQL, в частности, в стандарте SQL-92, на который мы будем ориентироваться при изложении материала настоящей лекции. Этот стандарт поддерживается практически всеми современными СУБД, вплоть до настольных. Иерархия объектов реляционной базы данных показана на рисунке ниже.
На самом нижнем уровне находятся наименьшие объекты, с которыми работает реляционная база данных, — столбцы (колонки) и строки. Они, в свою очередь, группируются в таблицы и представления.
Замечание. В контексте лекции атрибуты, колонки, столбцы и поля считаются синонимами. То же относится и к терминам «строка», «запись» и «кортеж».
Таблицы и представления, которые представляют физическое отражение логической структуры базы данных, собираются в схему. Несколько схем собираются в каталоги, которые затем могут быть сгруппированы в кластеры. Следует отметить, что ни одна из групп объектов стандарта SQL-92 не связана со структурами физического хранения информации в памяти компьютеров.
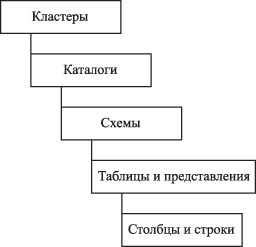
Рис.
8.1.
Иерархия объектов реляционной базы данных, соответствующая стандарту SQL-92
Помимо указанных на рисунке объектов, в реляционной базе данных могут быть созданы индексы, триггеры, события, хранимые команды, хранимые процедуры и ряд других. Теперь перейдем к определению объектов реляционной базы данных.
Основные объекты реляционной базы данных
Кластеры, каталоги и схемы не являются обязательными элементами стандарта и, следовательно, программной среды реляционных баз данных.
Под кластером понимается группа каталогов, к которым можно обращаться через одно соединение с сервером базы данных (программная компонента СУБД).
На практике процедура создания каталога определяется реализацией СУБД на конкретной операционной платформе. Под каталогом понимается группа схем. На практике каталог часто ассоциируется с физической базой данных как набором физических файлов операционной системы, которые идентифицируются ее именем.
Для проектировщика базы данных схема — это общее логическое представление отношений законченной базы данных. С точки зрения SQL, схема — это контейнер для таблиц, представлений и других структурных элементов реляционной базы данных. Принцип размещения элементов базы данных в каждой схеме полностью определяется проектировщиком базы данных.
Для создания таблиц и представлений наличие схемы не обязательно. Если у вас планируется инсталляция только одной логической базы данных, то ясно, что можно обойтись и без схемы. Но если планируется, что одна и та же СУБД будет использоваться для поддержки нескольких баз данных, то надлежащая организация объектов баз данных в схемы может значительно облегчить сопровождение этих баз данных. На практике схема часто ассоциируется с объектами определенного пользователя физической базы данных.
Далее объекты реляционной базы данных будут вводиться в контексте реляционной СУБД Oracle 9i. Такой подход принят потому, что проектирование физической модели реляционной базы данных выполняется для конкретной среды ее реализации.
В Oracle 9i термин схема (Schema) используется для описания всех объектов базы данных, которые созданы некоторым пользователем. Для каждого нового пользователя автоматически создается новая схема.
К числу основных объектов реляционных баз данных относятся таблица, представление и пользователь.
Таблица (Table) является базовой структурой реляционной базы данных. Она представляет собой единицу хранения данных — отношение. Таблица идентифицируется в базе данных своим уникальным именем, которое включает в себя идентификацию пользователя. Таблица может быть пустой или состоять из набора строк.
Представление (View) — это поименованная динамически поддерживаемая СУБД выборка из одной или нескольких таблиц базы данных. Оператор выборки ограничивает видимые пользователем данные. Обычно СУБД гарантирует актуальность представления — его формирование производится каждый раз, когда представление используется. Иногда представления называют виртуальными таблицами.
Пользователь (User) — это объект, обладающий возможностью создавать или использовать другие объекты базы данных и запрашивать выполнение функций СУБД, таких как организация сеанса работы, изменение состояние базы данных и т. д.
Для упрощения идентификации и именования объектов в базе данных поддерживается такие объекты, как синоним, последовательность и определенные пользователем типы данных.
Синоним (Synonym) — это альтернативное имя объекта (псевдоним) реляционной базы данных, которое позволяет иметь доступ к данному объекту. Синоним может быть общим и частным. Общий синоним позволяет всем пользователям базы данных обращаться к соответствующему объекту по его псевдониму. Синоним позволяет скрыть от конечных пользователей полную квалификацию объекта в базе данных.
Последовательность (Sequence) — это объект базы данных, который позволяет генерировать последовательность уникальных чисел (номеров) в условиях многопользовательского асинхронного доступа. Обычно элементы последовательности используются для уникальной нумерации элементов таблиц (строк) в операциях модификации данных.
Определенные пользователем типы данных (User-defined data types) представляют собой определенные пользователем типы атрибутов (домены), которые отличаются от поддерживаемых (встроенных) СУБД типов. Они определяются на основе встроенных типов. Определенные пользователем типы данных образуют ту часть среды СУБД, которая организована в соответствии с объектно-ориентированной парадигмой.
Для обеспечения эффективного доступа к данным в реляционных СУБД поддерживаются ряд других объектов: индекс, табличная область, кластер, секция.
Индекс (Index) — это объект базы данных, создаваемый для повышения производительности выборки данных и контроля уникальности первичного ключа (если он задан для таблицы). Полностью индексные таблицы (index-organized tables) исполняют роль таблицы и индекса одновременно.
Табличное пространство или область (Tablespace) — это именованная часть базы данных, используемая для распределения памяти для таблиц и индексов. В Oracle 9i — это логическое имя физических файлов операционной системы. Все объекты базы данных, в которых хранятся данные, соответствуют некоторым табличным пространствам. Большинство объектов базы данных, в которых данные не хранятся, находятся в словаре данных, расположенном в табличном пространстве SYSTEM.
Кластер (Cluster) — это объект, задающий способ совместного хранения данных в нескольких или одной таблице. Одним из критериев использования кластера является наличие общих ключевых полей в нескольких таблицах, которые используются в одной и той же команде SQL. Обычно кластеризованные столбцы или таблицы хранятся в базе данных в виде таблиц хэширования (т.е. специальным образом).
Секция (Partition) — это объект базы данных, который позволяет представить объект с данными в виде совокупности подобъектов, отнесенных к различным табличным пространствам. Таким образом, секционирование позволяет распределять очень большие таблицы на нескольких жестких дисках.
Для обработки данных специальным образом или для реализации поддержки ссылочной целостности базы данных используются объекты: хранимая процедура, функция, команда, триггер, таймер и пакет (Oracle). С помощью этих объектов базы данных можно выполнять так называемую построчную обработку (record processing) данных. С точки зрения приложений баз данных построчная обработка — это последовательная выборка данных по одной строке, ее обработка и переход к обработке следующей строки.
Данные объекты реляционной базы данных представляют собой программы, т.е. исполняемый код. Этого код обычно называют серверным кодом (server-side code), поскольку он выполняется компьютером, на котором установлено ядро реляционной СУБД. Планирование и разработка такого кода является одной из задач проектировщика реляционной базы данных.
Хранимая процедура (Stored procedure) — это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных (например, SQLWindows или PL/SQL).
Функция (Function) — это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных, который при выполнении возвращает значение — результат вычислений.
Команда (Command) — это поименованный оператор SQL, который заранее откомпилирован и сохраняется в базе данных. Скорость обработки команды выше, чем у соответствующего ему оператора SQL, т.к. при этом не выполняются фазы синтаксического разбора и компиляции.
Триггер (Trigger) — это объект базы данных, который представляет собой специальную хранимую процедуру. Эта процедура запускается автоматически, когда происходит связанное с триггером событие (например, до вставки строки в таблицу).
Таймер (Timer) отличается от триггера тем, что запускающим событием для хранимой процедуры является событие таймера.
Пакет (Package) — это объект базы данных, который состоит из поименованного структурированного набора переменных, процедур и функций.
В распределенных реляционных СУБД имеются специальные объекты: снимок и связь базы данных.
Снимок (Snapshop) — локальная копия таблицы удаленной базы данных, которая используется для тиражирования (репликации) таблицы или результата запроса. Снимки могут быть модифицируемыми или предназначенными только для чтения.
Связь базы данных (Database Link) или связь с удаленной базой данных — это объект базы данных, который позволяет обратиться к объектам удаленной базы данных. Имя связи базы данных, грубо говоря, можно представить как ссылку на параметры доступа к удаленной базы данных.
Для эффективного управления разграничением доступа к данным в Oracle поддерживает объект роль.
Роль (Role) — объект базы данных, представляющий собой поименованную совокупность привилегий, которые могут назначаться пользователям, категориям пользователей или другим ролям.
В Microsoft SQL Server для реализации и автоматизации своих собственных алгоритмов (расчётов) можно использовать хранимые процедуры, поэтому сегодня мы с Вами поговорим о том, как они создаются, изменяются и удаляются.
Но сначала немного теории, чтобы Вы понимали, что такое хранимые процедуры и для чего они нужны в T-SQL.
Примечание! Начинающим программистам рекомендую следующие полезные материалы на тему T-SQL:
- Справочник Transact-SQL;
- Основы программирования на T-SQL;
- SQL код – самоучитель по SQL для начинающих программистов;
- Если Вы хотите освоить язык SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL.
Содержание
- Что такое хранимые процедуры в T-SQL?
- Примеры работы с хранимыми процедурами в Microsoft SQL Server
- Исходные данные для примеров
- Создание хранимой процедуры на T-SQL – инструкция CREATE PROCEDURE
- Запуск хранимой процедуры на T-SQL – команда EXECUTE
- Изменение хранимой процедуры на T-SQL – инструкция ALTER PROCEDURE
- Удаление хранимой процедуры на T-SQL – инструкция DROP PROCEDURE

Хранимые процедуры – это объекты базы данных, в которых заложен алгоритм в виде набора SQL инструкций. Иными словами, можно сказать, что хранимые процедуры – это программы внутри базы данных. Хранимые процедуры используются для сохранения на сервере повторно используемого кода, например, Вы написали некий алгоритм, последовательный расчет или многошаговую SQL инструкцию, и чтобы каждый раз не выполнять все инструкции, входящие в данный алгоритм, Вы можете оформить его в виде хранимой процедуры. При этом, когда Вы создаете процедуру SQL, сервер компилирует код, а потом, при каждом запуске этой процедуры SQL сервер уже не будет повторно его компилировать.
Для того чтобы запустить хранимую процедуру в SQL Server, необходимо перед ее названием написать команду EXECUTE, также возможно сокращенное написание данной команды EXEC. Вызвать хранимую процедуру в инструкции SELECT, например, как функцию уже не получится, т.е. процедуры запускаются отдельно.
В хранимых процедурах, в отличие от функций, уже можно выполнять операции модификации данных такие как: INSERT, UPDATE, DELETE. Также в процедурах можно использовать SQL инструкции практически любого типа, например, CREATE TABLE для создания таблиц или EXECUTE, т.е. вызов других процедур. Исключение составляет несколько типов инструкций таких как: создание или изменение функций, представлений, триггеров, создание схем и еще несколько других подобных инструкций, например, также нельзя в хранимой процедуре переключать контекст подключения к базе данных (USE).
Хранимая процедура может иметь входные параметры и выходные параметры, она может возвращать табличные данные, может не возвращать ничего, только выполнять заложенные в ней инструкции.
Хранимые процедуры очень полезны, они помогают нам автоматизировать или упростить многие операции, например, Вам постоянно требуется формировать различные сложные аналитические отчеты с использованием сводных таблиц, т.е. оператора PIVOT. Чтобы упростить формирование запросов с этим оператором (как Вы знаете, у PIVOT синтаксис достаточно сложен), Вы можете написать процедуру, которая будет Вам динамически формировать сводные отчеты, например, в материале «Динамический PIVOT в T-SQL» представлен пример реализации данной возможности в виде хранимой процедуры.
Заметка! Назначение хранимых процедур в языке T-SQL (Microsoft SQL Server).
Примеры работы с хранимыми процедурами в Microsoft SQL Server
Исходные данные для примеров
Все примеры ниже будут выполнены в Microsoft SQL Server 2016 Express. Для того чтобы продемонстрировать, как работают хранимые процедуры с реальными данными, нам нужны эти данные, давайте их создадим. Например, давайте создадим тестовую таблицу и добавим в нее несколько записей, допустим, что это будет таблица, содержащая список товаров с их ценой.
--Инструкция создания таблицы
CREATE TABLE TestTable(
[ProductId] INT IDENTITY(1,1) NOT NULL,
[CategoryId] INT NOT NULL,
[ProductName] VARCHAR(100) NOT NULL,
[Price] MONEY NULL
)
GO
-- Инструкция добавления данных
INSERT INTO TestTable(CategoryId, ProductName, Price)
VALUES (1, 'Мышь', 100),
(1, 'Клавиатура', 200),
(2, 'Телефон', 400)
GO
--Запрос на выборку
SELECT * FROM TestTable
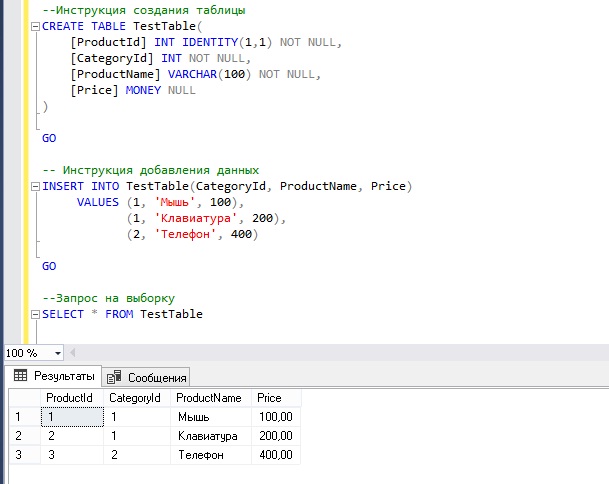
Данные есть, теперь давайте переходить к созданию хранимых процедур.
Создание хранимой процедуры на T-SQL – инструкция CREATE PROCEDURE
Хранимые процедуры создаются с помощью инструкции CREATE PROCEDURE, после данной инструкции Вы должны написать название Вашей процедуры, затем в случае необходимости в скобочках определить входные и выходные параметры. После этого Вы пишите ключевое слово AS и открываете блок инструкций ключевым словом BEGIN, закрываете данный блок словом END. Внутри данного блока Вы пишите все инструкции, которые реализуют Ваш алгоритм или какой-то последовательный расчет, иными словами, программируете на T-SQL.
Для примера давайте напишем хранимую процедуру, которая будет добавлять новую запись, т.е. новый товар в нашу тестовую таблицу. Для этого мы определим три входящих параметра: @CategoryId – идентификатор категории товара, @ProductName — наименование товара и @Price – цена товара, данный параметр будет у нас необязательный, т.е. его можно будет не передавать в процедуру (например, мы не знаем еще цену), для этого в его определении мы зададим значение по умолчанию. Эти параметры в теле процедуры, т.е. в блоке BEGIN…END можно использовать, так же как и обычные переменные (как Вы знаете, переменные обозначаются знаком @). В случае если Вам нужно указать выходные параметры, то после названия параметра указывайте ключевое слово OUTPUT (или сокращённо OUT).
В блоке BEGIN…END мы напишем инструкцию добавления данных, а также в завершении процедуры инструкцию SELECT, чтобы хранимая процедура вернула нам табличные данные о товарах в указанной категории с учетом нового, только что добавленного товара. Также в этой хранимой процедуре я добавил обработку входящего параметра, а именно удаление лишних пробелов в начале и в конце текстовой строки с целью исключения ситуаций, когда случайно занесли несколько пробелов.
Вот код данной процедуры (его я также прокомментировал).
--Создаем процедуру
CREATE PROCEDURE TestProcedure
(
--Входящие параметры
@CategoryId INT,
@ProductName VARCHAR(100),
@Price MONEY = 0
)
AS
BEGIN
--Инструкции, реализующие Ваш алгоритм
--Обработка входящих параметров
--Удаление лишних пробелов в начале и в конце текстовой строки
SET @ProductName = LTRIM(RTRIM(@ProductName));
--Добавляем новую запись
INSERT INTO TestTable(CategoryId, ProductName, Price)
VALUES (@CategoryId, @ProductName, @Price)
--Возвращаем данные
SELECT * FROM TestTable
WHERE CategoryId = @CategoryId
END
GO
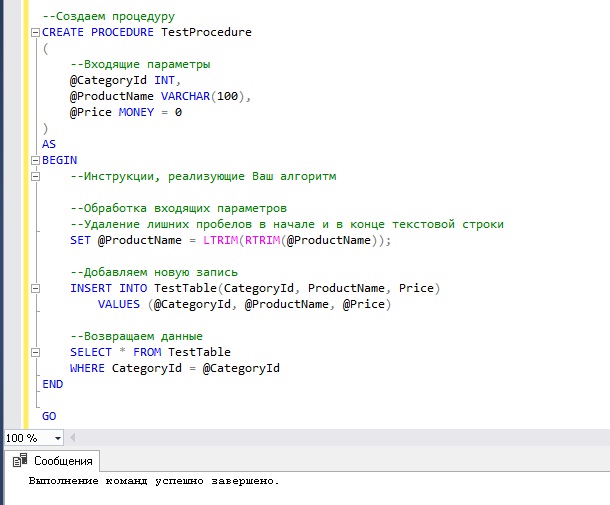
Запуск хранимой процедуры на T-SQL – команда EXECUTE
Запустить хранимую процедуру, как я уже отмечал, можно с помощью команды EXECUTE или EXEC. Входящие параметры передаются в процедуры путем простого их перечисления и указания соответствующих значений после названия процедуры (для выходных параметров также нужно указывать команду OUTPUT). Однако название параметров можно и не указывать, но в этом случае необходимо соблюдать последовательность указания значений, т.е. указывать значения в том порядке, в котором определены входные параметры (это относится и к выходным параметрам).
Параметры, которые имеют значения по умолчанию, можно и не указывать, это так называемые необязательные параметры.
Вот несколько разных, но эквивалентных способов запуска хранимых процедур, в частности нашей тестовой процедуры.
--1. Вызываем процедуру без указания цены
EXECUTE TestProcedure @CategoryId = 1,
@ProductName = 'Тестовый товар 1'
--2. Вызываем процедуру с указанием цены
EXEC TestProcedure @CategoryId = 1,
@ProductName = 'Тестовый товар 2',
@Price = 300
--3. Вызываем процедуру, не указывая название параметров
EXEC TestProcedure 1, 'Тестовый товар 3', 400
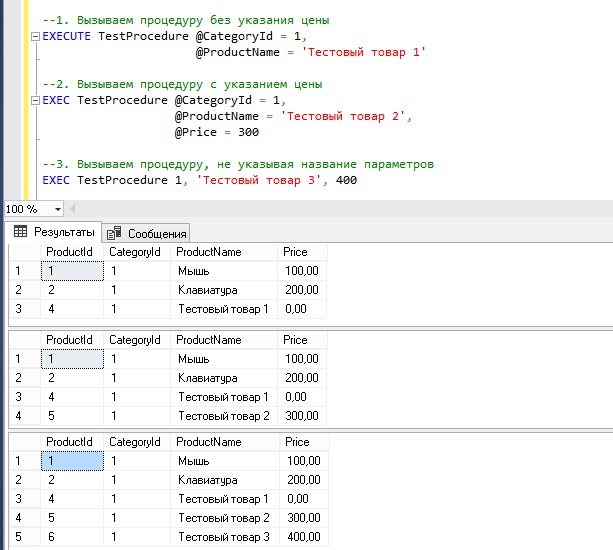
Изменение хранимой процедуры на T-SQL – инструкция ALTER PROCEDURE
Внести изменения в алгоритм работы процедуры можно с помощью инструкции ALTER PROCEDURE. Иными словами, для того чтобы изменить уже существующую процедуру, Вам достаточно вместо CREATE PROCEDURE написать ALTER PROCEDURE, а все остальное изменять по необходимости.
Допустим, нам необходимо внести изменения в нашу тестовую процедуру, скажем, параметр @Price, т.е. цену, мы сделаем обязательным, для этого уберём значение по умолчанию, а также представим, что у нас пропала необходимость в получении результирующего набора данных, для этого мы просто уберем инструкцию SELECT из хранимой процедуры.
--Изменяем процедуру
ALTER PROCEDURE TestProcedure
(
--Входящие параметры
@CategoryId INT,
@ProductName VARCHAR(100),
@Price MONEY
)
AS
BEGIN
--Инструкции, реализующие Ваш алгоритм
--Обработка входящих параметров
--Удаление лишних пробелов в начале и в конце текстовой строки
SET @ProductName = LTRIM(RTRIM(@ProductName));
--Добавляем новую запись
INSERT INTO TestTable(CategoryId, ProductName, Price)
VALUES (@CategoryId, @ProductName, @Price)
END
GO
Удаление хранимой процедуры на T-SQL – инструкция DROP PROCEDURE
В случае необходимости можно удалить хранимую процедуру, это делается с помощью инструкции DROP PROCEDURE.
Например, давайте удалим созданную нами тестовую процедуру.
DROP PROCEDURE TestProcedure
При удалении хранимых процедур стоит помнить о том, что, если на процедуру будут ссылаться другие процедуры или SQL инструкции, после ее удаления они будут завершаться с ошибкой, так как процедуры, на которую они ссылаются, больше нет.
У меня все, надеюсь, материал был Вам интересен и полезен, пока!
1.
Сергей Воробьёв
Ведущий инженертестировщик
SQL. Базовый курс
www.aplana.ru
2.
Содержание
● Часть 1. Введение в SQL
● Часть 2. Data Defenition Language
● Часть 3. Data Manipulation Language
● Часть 4. DRL. Простые запросы.
● Часть 5. Выборка данных из нескольких таблиц.
● Часть 6. Агрегатные функции. Группирование данных.
● Часть 7. Подзапросы.
● Часть 8. Функции для работы со строками, датами и числами.
23
3.
SQL. Базовый курс
Часть 1. Введение в SQL
www.aplana.ru
4.
Введение в SQL
SQL (англ. Structured Query Language – «язык структурированных
запросов») – универсальный компьютерный язык, применяемый для
создания, модификации и управления данными в реляционных базах
данных.
43
5.
Введение в SQL
• База данных – список или множество связанных списков с
информацией
• Система управления базами данных (СУБД) – специальный
софт, управляющиий этими списками
53
6.
Реляционные и нереляционные БД
Реляционная БД – база данных, основанная на реляционной модели
данных:
• Данные в базе представляют собой набор таблиц;
• Данные удовлетворяют определенным условиям целостности;
• Поддерживает операторы манипулирования таблицами
(например, выборка или копирование таблицы).
Нереляционные базы данных – иерархические, сетевые,
объектно-ориентированные, NoSQL.
63
7.
Чем БД отличаются от электронных таблиц
1. Хранение большого количества строк
• В электронных таблицах количество строк ограничено.
• В БД хранятся миллионы строк.
2. Одновременное обслуживание многих пользователей
3. Безопасность.
• Пользователям предоставляются привилегии только на
определенные таблицы и действия.
4. Реляционные свойства.
• Данные хранятся в разных таблицах, между таблицами
существуют связи.
5. Ограничения, гарантирующие качество данных.
73
8.
Таблица (table)
Строка(row) – горизонтальный ряд ячеек, отведенный для каждого
объекта таблицы.
Запись (record) – данные в строке.
Столбец(column) – содержит информацию одного типа.
Поле(field) – пересечение столбца и строки.
83
9.
Основы интерфейса SQL
СУБД
93
Название
Расшифровка
InterBase/FireBird
PSQL
Procedural SQL
IBM DB2
SQL PL
SQL Procedural Language
Ms SQL Server/Sybase ASE
T-SQL
Transact-SQL
MySQL
SQL/PSM
SQL/Persistent Stored
Module
Oracle
PL/SQL
Procedural Language/SQL
(основан на языке Ada)
PostgreSQL
PL/pgSQL
Procedural
Language/PostgreSQL
(очень похож на Oracle
PL/SQL)
10.
Различия синтаксиса функций СУБД
MSSQL
DB2
NUMERIC
NUMBER
NUMERIC
DATEADD
MONTH_ADD
(Date + 10 DAYS)
EOMONTH
LAST_DAY
LAST_DAY
DATEDIFF
MONTH_BETWEEN
TIMESTAMPDIFF
UPPER
UPPER
UCASE/UPPER
CONVERT
TO_CHAR
TO_CHAR
INITCAP
INITCAP
—
103
Oracle
11.
Синтаксис SQL
• Функции и названия объектов нечуствительны к регистру:
SELECT = sELeCt.
• Однако при поиске по текстовым полям регистр учитывается
• SQL не чувствителен к переносу строк
• Отсутствуют обязательные символы, завершающие строки
• Поддерживаются —однострочные комментарии и
/*многострочные */
• Каждую транзакцию принято завершать точкой с запятой, но
при выполнении отдельных команд их употребление не
обязательно
113
12.
Типы данных
CHAR(n) – строки постоянной длины (до 256 байтов в MS SQL Server), т.е.
ввели меньше данных в строку – размер не изменится
VARCHAR(n) – строки переменной длины, т.е. требует памяти столько,
сколько данных
INTEGER – число без десятичной точки
NUMERIC (m,n) – используется для хранения нуля и положительных или
отрицательных чисел с фиксированной и плавающей точкой. MТОЧНОСТЬ (общее число цифр), n – МАСШТАБ (число цифр справа от
десятичной точки). m/n –необязательные параметры
DATE — дата в формате yyyy-mm-dd (ISO), dd/mm/yyyy (ANSI), dd-MON-yy.
BOOLEAN – логический тип данных: true/false или 1/0.
Также значением поля может быть NULL – означает отсутствие значений –
пустую ячейку.
123
13.
Тип DATE
По умолчанию можно представлять в базе данных дату в формате DD-MONYYYY (например, ‘01-FEB-1900’):
INSERT INTO table1 (id, date_work) values (1, ‘01-FEB-1900’).
Также можно использовать ключевое слово DATE. При этом уже для
формата даты YYYY-MM-DD (например, ‘1900-02-01’):
INSERT INTO table1 (id, date_work) values (1, DATE ‘1900-02-01’).
Также альтернативно можно использовать тип даты + время TIMESTAMP
для задания уже не только даты, но и времени:
INSERT INTO table1 (id, date_work) values (1, ‘01-FEB-1900-10.50.01’),
т.е.
1 февраля 1900 10 часов 50 минут и 1 секунда (формат dd-MON-yy
-hh.mm.ss.nnnnn)
133
14.
Преобразование типов данных в MSSQL
CONVERT(тип данных, строка, стиль) – преобразование одного
формата данных в другой
В символы:
CONVERT(VARCHAR(20), GETDATE())
В дату
CONVERT(DATETIME, ’14-11-2015′, 105)
В число
CONVERT(NUMERIC, ‘1234657890′)
143
15.
Преобразование типов данных в Oracle
TO_CHAR(входное значение, формат) – преобразование даты,
числа, времени в строку.
Формат: ’MONTH DD’, ‘MONTH DD, YYYY’, ‘DD/MM/YYYY’, ‘DAY MON, YY AD’
YEAR
$9,999.00
И т. д.
TO_CHAR(SYSDATE, ‘MONTH DD’)
TO_DATE(входное значение, формат) – преобразование строки в
дату. Формат: DD-MON-YYYY
Month dd, YYYY , HH:MI p.m.
И т. д.
TO_DATE(’02-JAN-2012′, ‘DD-MON-YYYY’)
TO_NUMBER(входное значение, формат) – преобразование строки в число.
TO_NUMBER(‘123’)
153
16.
Другие объекты базы данных
Представление (view) – это объекты БД, которые не содержат
собственных таблиц, но их содержимое берется из других таблиц
или представлений посредством выполнения запроса.
Схема (schema) – поименованная группа связанных объектов БД.
Индекс (index) – объект, создаваемый для повышения
производительности Поиска. Скрытая таблица, содержащая один
или несколько важных столбцов таблицы и указатели на строки
таблицы.
Ограничение (constraint) – условия, которым должны удовлетворять
введенные пользователем записи.
163
17.
Другие объекты базы данных
Хранимая процедура (stored procedure) – объект базы данных,
представляющий собой набор SQL-инструкций. Хранится в БД.
Вызов процедуры приводит к выполнению содержащихся в ней
инструкций.
Функция (function) – похожа на хранимую процедуру, но возвращает
значение, которое может быть использовано в более крупном
операторе.
Триггер (trigger) – процедура, которая выполняется автоматически,
когда происходит некоторое заданное событие.
Курсор (cursor) – ссылка на контекстную область памяти. Используя
курсор, можно отдельно обрабатывать каждую строку связанного с
ним SQL-оператора.
173
18.
Разделы языка SQL
1. DDL — Data Defenition Language (язык определения объектов БД).
CREATE, ALTER, DROP и тд
2. DCL — Data Control Language (язык управления данными).
GRANT, REVOKE
3. DML — Data Manipulation Language (язык манипулирования
данными). INSERT, UPDATE, DELETE
4. Data Retrieval — выборка данных SELECT
5. Transaction Control (язык поддержания процесса транзакций).
COMMIT, ROLLBACK, SAVEPOINT.
183
19.
SQL. Базовый курс
Часть 2. Data Defenition Language
www.aplana.ru
20.
Data Defenition Language
1.
CREATE TABLE (создание таблиц)
Общий синтаксис:
CREATE TABLE имя_таблицы (
поле1 Тип поля1,
поле2 Тип поля2,
…, полеN Тип поляN);
CREATE TABLE person_info (
person_id INTEGER NOT NULL,
first_name VARCHAR(15) NOT NULL,
last_name VARCHAR(20) NOT NULL,
gender CHAR(1),
birthday DATE,
salary NUMERIC(7,2));
203
21.
Data Defenition Language
2. ALTER TABLE (изменение таблиц)
ALTER TABLE имя_таблицы {ADD <имя столбца> <определение столбца>}|
{MODIFY <имя столбца> <Определение столбца>}| {DROP COLUMN <имя
столбца>}
3. DROP TABLE (удаление таблиц)
DROP TABLE имя_таблицы {CASCADE CONSTRAINTS};
4. TRUNCATE TABLE (очистка таблиц)
TRUNCATE TABLE имя_таблицы
213
22.
SQL. Базовый курс
Часть 3. Data Manipulation Language
www.aplana.ru
23.
Data Manipulation Language
1. INSERT — Вставка отдельной записи.
•INSERT INTO имя_таблицы VALUES (значение поля1, значение поля2,..,
значение поляN);
•INSERT INTO имя_таблицы (поле1, поле3,…) VALUES (значение поля1, значение поля2,…,
значение поляN);
INSERT INTO person_info VALUES (1, ‘John’, ‘Smith’, ‘M’, ’15-OCT-1973′,
45568.56);
INSERT INTO person_info (person_id, first_name, last_name) VALUES (5, Sarah’, ‘Connor’);
Успешно.
INSERT INTO person_info VALUES (NULL, ‘Jane’, ‘Smith’, ‘F’, ‘8-AUG-1987’,
NULL);
Ошибка, т.к person_id не может быть NULL.
233
24.
Data Manipulation Language
Вставка группы записей
INSERT INTO имя_таблицы
SELECT…;
CREATE TABLE t2 (
first_1 VARCHAR(15),
last_1 VARCHAR(20),
birthday_1 DATE);
INSERT INTO t2
SELECT first_name, last_name, birthday
FROM person_info;
243
25.
Data Manipulation Language
INSERT INTO person_info VALUES (2, ‘Sara’, ‘Doe’, ‘F’, ‘9-OCT-1986’,
29789.56);
INSERT INTO person_info VALUES (2, ‘Rita’, ‘Blow’, ‘F’, ‘9-OCT-1975’,
29789.56);
Успешно.
INSERT INTO person_info VALUES (3, ‘Sara’, ‘Doe’, ‘F’, ‘9-OCT-1986’,
29789.56);
Теперь удалим вторую запись с person_id=2
DELETE FROM person_info WHERE person_id = 2
253
26.
Data Manipulation Language
Целостность данных
Целостность сущностей — определяет строку таблицы как уникальный экземпляр
некоторой сущности.
Первичный ключ (primary key) — столбец или группа столбцов уникально
идентифицирующий каждую запись.
Внешний ключ (foreign key) – отражение связей между таблицами. Подчиненная
таблица должна иметь идентичный столбец (или группу столбцов) для хранения
значений, уникально идентифицирующих главные записи.
Ссылочная целостность – в подчиненных таблицах не должно быть записей,
ссылающихся на несуществующие записи главных таблиц.
263
27.
Data Manipulation Language
273
28.
Data Manipulation Language
Первичный ключ
ALTER TABLE имя_таблицы
ADD PRIMARY KEY (имя_столбца);
ALTER TABLE person_info
ADD PRIMARY KEY(person_id);
Значения первичного ключа подразумевают уникальную идентификацию
записи, соответственно, значения не могут повторяться.
И опять попытаемся добавить запись с person_id=2:
INSERT INTO person_info VALUES (2, ‘Rita’, ‘Blow’, ‘F’, ‘9-OCT-1975’,
29789.56);
283
29.
Внешний ключ
ALTER TABLE имя_подчиненной_таблицы
ADD CONSTRAINT имя_ограничения FOREIGN KEY (имя_столбца
подчиненной
таблицы) REFERENCES имя_главной_таблицы;
CREATE TABLE person_address (
person_id INTEGER,
address VARCHAR(200));
ALTER TABLE person_address
ADD CONSTRAINT person_fk_address
FOREIGN KEY (person_id)
REFERENCES person_info;
293
30.
Data Manipulation Language
INSERT INTO person_address VALUES (1, ‘Moscow, Arbat street, 67-14’);
INSERT INTO person_address VALUES (2, ‘Moscow, Arbat street, 67-14’);
Успешно.
INSERT INTO person_address VALUES (4, ‘Zelenograd,Green street, 23’);
Ошибка. Попытка вставить подчиненную запись при отсутствии
соответствующей главной записи.
INSERT INTO person_address VALUES (3, ‘Zelenograd,Green street, 23’);
303
31.
Связывание таблиц при создании
Как мы уже рассмотрели ранее, широко используется создание
первичного (PRIMARY KEY) и внешнего (FOREIGN KEY) ключей
через команды изменения структуры существующих таблиц. Также
можно добавлять эти конструкции и при создании таблицы:
CREATE TABLE tab1(
id integer PRIMARY KEY,
…..
313
32.
Data Manipulation Language
2. UPDATE — Изменение значений столбцов таблицы
A)Изменение всех значений столбца таблицы
UPDATE <table_name>
SET <column_name> = <value>
UPDATE person_address
SET address = ‘Volgograd, First street, 15-20’
Б)Изменение конкретных значений таблицы
UPDATE <table_name>
SET <column_name> = <value>
WHERE <column_name> = <value>
UPDATE person_address SET address = ‘Volgograd, First street, 15-20’
WHERE person_id = 3;
UPDATE <table_name>
SET <column_name> = <value>
WHERE <column_name> = <column_name> [оператор]
UPDATE person_info SET salary = salary * 2
WHERE person_id = 3;
323
33.
Data Manipulation Language
3. DELETE — Удаление строк из таблицы
А) Удаление всех значений столбца таблицы
DELETE FROM <table_name>
Б) Удаление конкретных значений таблицы
DELETE FROM <table_name>
WHERE <column_name> = <value>
333
34.
Практическое задание № 1
1. Создать БД, изображенную на рис.1 (создать таблицы и внешний ключ)
2. Внести в таблицы следующие данные.
Dept: (1, ‘Marketing’), (2, ‘RD’)
Emp: (1, 1, ‘James’, 1000), (2, 2, ‘Smith’, 2000)
3. Создать таблицу dept_arch с такой же структурой, как и у таблицы dept.
4. Вставить в таблицу dept_arch все данные из таблицы dept.
343
35.
Практическое задание № 1 (продолжение)
5. Увеличьте на 15% зарплату сотруднику Smith.
6. Убедитесь, что в таблицу dept нельзя вставить такую запись: (2, ‘Sales’). Почему?
7. Убедитесь, что в таблицу emp нельзя вставить такую запись: (3, 4, ‘Black’, 3000,
‘Active’). Почему?
8. Измените название отдела RD на RandD (таблица dept).
9. Удалите из таблицы emp запись с emp_id = 1.
12. Удалите из таблицы emp все записи.
13. Удалите таблицу emp.
353
36.
SQL. Базовый курс
Часть 4. DRL. Простые запросы
www.aplana.ru
37.
Наша учебная БД
373
38.
Data Retrieval Language
SELECT – выборка данных. Этот раздел является обязательным в запросе и
позволяет:
SELECT поле1,…полеN FROM таблица1, .., таблицаN WHERE условие
383
Определить список выходных столбцов
Включить вычисляемые столбцы
Включить константы
Переименовать выходные столбцы
Указать принцип обработки дублей строк
Включить агрегатные функции
39.
Data Retrieval Language
1.
Определение списка выходных столбцов
Список выходных столбцов может быть указан несколькими способами:
•. Указать символ *, обозначающий включение в результаты запроса всех колонок
запроса в естественной последовательности.
•. Перечислить в желательном порядке только нужные <имена столбцов>.
SELECT person_code, first_name, last_name FROM person;
—Можем менять порядок столбцов
SELECT first_name, last_name, person_code FROM person;
393
40.
Конкатенация
Соединение двух и более частей текста.
SELECT product_name + ‘ was sold by ‘ + salesperson FROM purchase;
403
41.
Data Retrieval Language
2. Включение вычисляемых столбцов
В качестве вычисляемых столбцов запроса могут выступать:
•. Результаты простейших арифметических выражения (+, -, /, *_ или
конкатенации строк (+).
•. Результаты функций агрегирования {AVG|SUM|MAX|MIN|
COUNT}
413
42.
Data Retrieval Language
3. Включение констант
В качестве столбцов могут выступать константы числового и
символьного типов.
SELECT ‘Есть такой код’,person_code, ‘для’, first_name, last_name
FROM person
423
43.
Data Retrieval Language
4.
Переименование выходных столбцов
Вычисляемым, а также любым другим столбцам, при желании,
можно присвоить уникальное имя с помощью ключевого слова
AS: <выражение> AS <новое имя>
SELECT product_name + ‘ was sold by ‘ + salesperson AS SOLDBY
FROM purchase;
Можно задавать псевдонимы и без использования ключевого слова, но с ограничениями:
SELECT product_name + ‘ was sold by ‘ + salesperson SOLDBY
FROM purchase;
SELECT product_name + ‘ was sold by ‘ + salesperson «Sold By»
FROM purchase;
433
44.
Data Retrieval Language
5. Указывание принципа обработки дублей
• DISTINCT – запрещает появление строк-дублей в выходном
множестве. Его можно задавать один раз для оператора SELECT.
На практике первоначально формируется выходное множество,
упорядочивается, а затем из него удаляются повторяющиеся
значения. Обычно это занимает много времени и не следует этим
злоупотреблять.
SELECT DISTINCT * FROM person
• ALL (действует по умолчанию) – обеспечивает включение в
результаты запроса и повторяющихся значений
443
45.
Data Retrieval Language
6.
Включение агрегатных функций
Функции агрегирования (функции над множествами, статистические или
базовые) предназначены для вычисления некоторых значений для
заданного множества строк. Используются следующие агрегатные
функции:
AVG|SUM(<выражение) – подсчитывает среднее значение | сумму от
<выражение>.
MIN|MAX(<выражение>) – находит максимальное | минимальное значение.
COUNT(*|[DISTINCT] <имя столбца>) – подсчитывает число строк
Но об этом далее
453
46.
Data Retrieval Language
WHERE – выборка данных, которые удовлетворяют определенным
условиям.
SELECT поле1,…полеN FROM таблица1, .., таблицаM WHERE
условие1,…условиеY
463
47.
Data Retrieval Language
Примеры:
SELECT * FROM product WHERE laststockdate IS NULL;
SELECT * FROM product WHERE laststockdate IS NOT NULL;
• SELECT product_name, product_price, quantity_on_hand
FROM product WHERE quantity_on_hand > 150;
• SELECT product_name, product_price FROM product
WHERE product_name <> ‘Square Zinculator’;
473
48.
Data Retrieval Language
Есть и более сложные условия:
Попадания во множество
<конструктор значений строки> [NOT] IN (<подзапрос>|<набор конструкторов
значений строки>)
Определяется множество значений, которому объект сравнения, записанный до
ключевого слова IN, может принадлежать или не принадлежать. Если подзапрос не
возвращает строк, то предикат принимает значение FALSE.
Примеры на работу со множествами:
SELECT * FROM purchase WHERE salesperson IN (‘CA’, ‘BB’);
SELECT * FROM purchase WHERE salesperson NOT IN (‘CA’, ‘BB’);
SELECT * FROM purchase WHERE (salesperson + product_name) in ((‘CA’ + ‘Small
Widget’), (‘GA’ + ‘Chrome Phoobar’))
483
49.
Data Retrieval Language
Принадлежности диапазону
<конструктор значений строки> [NOT] BETWEEN <конструктор
значений строки 1> AND <конструктор значений строки 2>
Предикат BETWEEN сходен с предикатом IN, но вместо элементов
множества он задает включающие границы, в которые [не] должно
попадать проверяемое значение.
SELECT product_name, product_price FROM product WHERE
product_price NOT BETWEEN 1 AND 80;
493
50.
Data Retrieval Language
Булевы операторы
<предикат> {AND|OR|NOT} <предикат>
Примечания: булевы оператора связывают один или несколько предикатов, образуя
единственное логическое значение TRUE|FALSE. Используя предикаты с
булевыми операторами, можно значительно увеличить и избирательную
способность по отбору строк в результат запроса.
При использовании булевых операторов, особенно оператора NOT, следует
применять круглые скобки для правильного составления условий (AND
выполняется раньше OR).
SELECT product_name, product_price FROM product WHERE product_name LIKE
‘%Widget’ OR product_price < 20;
SELECT product_name, product_price FROM product WHERE product_name LIKE
‘%Widget’ AND product_price < 20;
503
51.
Data Retrieval Language
Оператор примерного поиска LIKE
SELECT список полей FROM список таблиц WHERE проверяемое значение LIKE
(шаблон) (ESCAPE (имя пропуска));
Один любой символ — _
SELECT person_code, first_name, last_name FROM person WHERE person_code LIKE ‘_A’;
Любая подстрока — %
SELECT product_name FROM product WHERE product_name LIKE ‘%Chrome%’;
Если надо найти текст с символом % (например, название продукта
ab%cdef):
WHERE product_name LIKE ‘ab$%c%’ ESCAPE ‘$’;
Первый % читается как символ в названии, второй – как любая строка.
513
52.
Data Retrieval Language
Оператор примерного поиска LIKE
… where отчество like ‘%ов%’
… where отчество like ‘И%’
… where отчество like ‘%вич’
… where Фамилия like ‘____ов’
523
53.
Data Retrieval Language
Оператор примерного поиска LIKE
select product_name from purchase
select product_name from purchase
where product_name like ‘%Widget’
select product_name from purchase
where product_name like ‘%$%Widget’
escape ‘$’
533
54.
Data Retrieval Language
Сортировка
SELECT список столбцов FROM список таблиц WHERE условие
ORDER BY список столбцов ASC (DESC);
По убыванию:
SELECT product_name, product_price FROM product
ORDER BY product_price DESC;
По возрастанию:
SELECT product_name, product_price FROM product
ORDER BY product_name ASC;
543
55.
Практическое задание № 2
1. Напишите запрос, полностью показывающий таблицу purchase.
2. Напишите запрос, выбирающий столбцы product_name и quantity из
таблицы Purchase.
3. Напишите запрос, выбирающий эти столбцы в обратном порядке.
4. Напишите запрос, выводящий для каждой строки таблицы person
следующий текст:
<first_name> <last_name> started work <hiredate>*. Получаемому столбцу
присвоить псевдоним “Started Work”.
5. Напишите запрос,выводящий наименование продуктов product_name
(таблица product), для которых цена не определена (NULL).
6. Напишите запрос, выводящий наименование продуктов product_name
(таблица purchase), которых продали от 3 до 23 штук.
* MSSQL не поддерживает объединение столбцов с типами данных varchar и date. Используйте оператор
конветации: CONVERT(VARCHAR, hiredate)
3
56.
Практическое задание № 2 (продолжение)
7. Напишите запрос, выводящий фамилии сотрудников, которых
приняли на работу 1го, 15го и 28го февраля 2010 года.
8. Напишите запрос, выводящий наименование продуктов
product_name (таблица purchase), проданных сотрудниками, фамилии которых начинаются на “B”.
9. Напишите запрос, выводящий наименование продуктов
product_name (таблица purchase), проданных сотрудниками, фамилии которых не начинаются на
“B”.
10. Напишите запрос, выводящий фамилии и дату приема на работу
сотрудников, фамилии которых начинаются на “B” и которых приняли
на работу раньше 1 марта 2010 года.
11. Напишите запрос, выводящий наименование продуктов
product_name и дату последней поставки laststockdate (таблица
product), наименование которых Small Widget, Medium Widget и Large
Widget или те, для которых не указана дата последней поставки.
Отсортируйте по убыванию даты последней поставки.
563
57.
SQL. Базовый курс
Часть 5. Выборка данных из нескольких таблиц
www.aplana.ru
58.
Выборка данных из нескольких таблиц
SELECT имя_таблицы_1.имя_столбца, имя_таблицы_2.
имя_столбца
FROM имя_таблицы_1, имя_таблицы_2;
SELECT purchase.product_name, person.first_name, person.last_name
FROM purchase, person;
Декартово произведение (Cartesian product) — соединение без
конструкции WHERE, в результате которого каждая строка
одной таблицы комбинируется с каждой строкой другой
таблицы.
583
59.
Выборка данных из нескольких таблиц с условием
SELECT имя_таблицы_1.имя_столбца, имя_таблчцы_2. имя_столбца
FROM имя_таблицы_1, имя_таблицы_2
WHERE имя_главной_таблицы.первичный_ключ =
имя_подчиненной_таблицы.внешний_ключ;
SELECT purchase.product_name, person.first_name, person.last_name
FROM purchase, person
WHERE person.person_code = purchase.salesperson;
593
60.
Типы соединения
Существуют также иные способы соединения таблиц по ключам:
<таблица А> [<тип соединения>] JOIN <таблица B> ON <предикат>
<тип соединения> представляет собой один из аргументов: INNER|{LEFT|RIGHT|
FULL[OUTER]}
INNER – включает строки, в которых есть столбцы с совпадающими данными
объединяемых таблиц. Используется по умолчанию.
LEFT[OUTER] – включает все строки таблицы А (левая таблица) и все совпадающие
значения из таблицы B. Столбцы несовпадающих строки заполняются NULL-значениями.
RIGHT[OUTER] – включает все строки таблицы B (правая таблица) и все совпадающие
значения таблицы А. обратный вариант для левого объединения.
FULL[OUTER] – включает все строки обеих таблиц. Столбцы совпадающих строк
заполнены реальными значениями, а несовпадающих строк – NULL-значениями.
OUTER (внешний) – уточняющее слово, означающее, что несовпадающие строки из
ведущей таблицы включаются вместе с совпадающими.
603
61.
Варианты соединения таблиц
address
phone
INNER JOIN
SELECT * FROM address INNER JOIN phone ON address.ClientID=phone.ClientID
613
62.
Варианты соединения таблиц
address
phone
SELECT * FROM address, phone WHERE address.clientID=phone.ClientID
623
63.
Варианты соединения таблиц
address
phone
LEFT JOIN
SELECT * FROM address LEFT JOIN phone ON address.ClientID=phone.ClientID
633
64.
Варианты соединения таблиц
address
phone
RIGHT JOIN
SELECT * FROM address RIGHT JOIN phone ON address.ClientID=phone.ClientID
643
65.
Варианты соединения таблиц
address
phone
FULL JOIN
SELECT * FROM address FULL JOIN phone ON address.ClientID=phone.ClientID
653
66.
Операторы соединения
UNION возвращает все строки из обоих операторов SELECT; повторяющиеся
значения удаляются.
UNION ALL возвращает все строки из обоих операторов SELECT; повторяющиеся
значения показываются.
INTERSECT возвращает строки, которые возвращены и первым, и вторым
оператором SELECT.
EXCEPT возвращает строки, которые возвращены первым оператором SELECT,
исключая те, которые возвращены вторым оператором.
Количество и порядок столбцов, возвращаемых SELECT из обеих таблиц, должны
совпадать.
663
67.
Операторы соединения
SELECT product_name
FROM purchase
ORDER BY product_name
673
SELECT product_name
FROM purchase_archive
ORDER BY product_name
SELECT product_name
FROM purchase
UNION
SELECT product_name
FROM purchase_archive
ORDER BY product_name
68.
Операторы соединения
SELECT product_nam e
FRO M purchase
U N IO N ALL
SELECT product_nam e
FRO M purchase_archive
O RD ER BY 1
683
SELECT product_nam e
FRO M purchase
EXCEPT
SELECT product_nam e
FRO M purchase_archive
O RD ER BY 1
SELECT product_nam e
FRO M purchase
IN TERSECT
SELECT product_nam e
FRO M purchase_archive
O RD ER BY 1
69.
Псевдоним в области FROM
• При использовании больших баз со схемами принято
использование псевдонимов:
SELECT purc.product_name, prod.laststockdate, pers.first_name,
pers.last_name
FROM purchase as purc,
Person as pers,
Product prod
WHERE pers.person_code = purc.salesperson AND
prod.product_name = purc.product_name;
693
70.
Практическое задание № 3
1. Напишите запрос, выводящий декартово произведение таблиц product
и purchase.
2. Напишите запрос, выводящий наименование проданного товара
product_name, количество quantity (таблица purchase) и
quantity_on_hand (таблица product).
3.Напишите запрос, выводящий наименование товара product_name
(таблица purchase), дату последней поставки laststockdate (таблица
product) и фамилию продавца last_name (таблица person).
4. Напишите запрос, выводящий столбцы product_name, first_name,
last_name внешнего объединения таблиц purchase и person. Используйте для таблиц
короткие псевдонимы.
703
71.
Практическое задание № 3 (продолжение)
5. Напишите запрос, который выводит все неповторяющиеся в purchase коды
продавцов
salesperson из таблицы purchase_archive.
6. Напишите запрос, который выводит коды только тех продавцов salesperson из
таблицы purchase, которые так же содержаться в таблице purchase_archive.
7. Напишите запрос, который выводит все (в том числе повторяющиеся) коды
продавцов salesperson из таблиц purchase и purchase_archive.
713
72.
SQL. Базовый курс
Часть 6. Агрегатные функции. Группирование
данных.
www.aplana.ru
73.
Математические операторы
Математический оператор – символы, обозначающие операции (+, -,*, /)
Вычисления с использованием данных из таблиц.
SELECT product_name, product_price * 1.07 FROM product;
SELECT product_name, product_price * quantity_on_hand
FROM product;
SELECT product_name, product_price * 1.07 * quantity_on_hand product_price * quantity_on_hand
FROM product;
SELECT product_name, product_price * (quantity_on_hand + 10)
FROM product;
733
74.
Математические операторы
Функции агрегирования (функции над множествами, статистические или базовые)
предназначены для вычисления некоторых значений для заданного множества
строк.
1. SUM — суммирует значения и возвращает итог.
SELECT SUM(quantity)
FROM purchase;
2. AVG – возвращает среднее значение по указанному
столбцу.
SELECT AVG(product_price)
FROM product;
743
75.
Математические операторы
3. MIN – возвращает минимальное значение из указанного столбца.
SELECT MIN(product_price)
FROM product;
4. MAX — возвращает максимальное значение из указанного столбца.
SELECT MAX(product_price)
FROM product;
753
76.
Математические операторы
5. COUNT – подсчитывает записи.
SELECT COUNT(*)
FROM purchase; —число строк с учетом NULL значений
SELECT COUNT(product_name)
FROM purchase;—значений в столбце, игнорируя NULL
763
77.
GROUP BY
Этот раздел предназначен для объединения результатов запроса в группы и расчета
для каждой из них статистических значений. Иногда используют термин
«сгруппированная таблица».
SELECT product_name, SUM(quantity)
FROM purchase
GROUP BY product_name;
В оператор SELECT можно включить несколько групповых функций.
SELECT product_name, SUM(quantity) «Total Sold», COUNT(quantity) Transactions
FROM purchase
GROUP BY product_name;
773
78.
HAVING
HAVING – является подразделом предназначенным для ограничения числа
строк в сгруппированной таблице и является частью раздела GROUP BY.
Предикат этого раздела строится по тем же семантическим правилам, что и
в разделе WHERE, однако напрямую в предикате могут участвовать только
те столбцы, которые указаны в раздел GROUP BY. Остальные можно
использовать только внутри функций агрегирования. Этот раздел
ограничивает состав групп (подгрупп) строк, на которые разбивается
результат запроса. В группы (подгруппы) включаются только те из
множества возможных строк, для значений которых выполняются условия
предиката раздела HAVING. Внутри раздела HAVING можно использовать
вложенные запросы с функциями агрегирования, а также связанные
подзапросы.
783
79.
HAVING
Т.е., подведя итог выше описанного, можно сузить
назначение подраздела до:
С помощью конструкции HAVING можно
фильтровать группы.
HAVING работает для групп так же, как и WHERE для отдельных записей.
SELECT product_name, SUM(quantity) «Total Sold»,
COUNT(quantity) Transactions
FROM purchase
GROUP BY product_name
HAVING SUM(quantity) < 5;
793
80.
Практическое задание № 4
1. Напишите запрос, показывающий, какой будет цена продукта product_price после
увеличения на 15%.
2. Напишите запрос, показывающий, сколько всего имеется товаров в таблице product.
3.Напишите запрос, показывающий, для какого количества товаров (таблица product) не
указана цена.
4. Напишите запрос, выводящий минимальную и максимальную цену товаров product_price.
5. Напишите запрос, показывающий, какая сумма была выручена с продаж товаров каждого
наименования.
6. Напишите запрос, показывающий, какая сумма была выручена с продаж товаров каждого
наименования. Вывести только те записи, для которых сумма продаж больше 125.
803
81.
SQL. Базовый курс
Часть 7. Подзапросы
www.aplana.ru
82.
Подзапросы
Подзапрос — это обычный запрос SELECT, вложенный в оператор
SELECT,
UPDATE
или
DELETE.
Он используется в качестве источника данных для раздела FROM или
WHERE родительского оператора.
823
83.
Подзапросы
Есть некие ограничения использования подзапросов:
833
Подзапрос должен выбирать только один столбец (за исключением подзапроса с
предикатом EXISTS), и тип данных его результата должен соответствовать типу
данных значения, указанному в предикате.
В ряде случаев можно использовать ключевое слово DISTINCT для гарантии
получения единственного значения.
Во вложенном запросе нельзя включать раздел ORDER BY и UNION.
Подзапрос может находиться и слева и справа от условия поиска.
В подзапросах могут использоваться функции агрегирования без раздела
GROUP BY
84.
Однострочные подзапросы
Однострочный подзапрос – это подзапрос, который возвращает лишь 1 значение.
Используются символы сравнения с результатом вложенного запроса (=, <>, <, <=,
>, >=)
SELECT * FROM product
WHERE laststockdate = (SELECT laststockdate
FROM product WHERE product_name = ‘Small Widget’);
Пример (использование агрегатной функции в однострочном подзапросе):
SELECT * FROM product WHERE product_price >
(SELECT AVG(product_price) FROM product);
843
85.
Многострочные подзапросы
Многострочный подзапрос – это подзапрос, который возвращает лишь >=1
значение.
Для таких подзапросов нельзя выполнять сравнение с
помощью знаков равенства/неравенства; необходимо использовать функцию [NOT]
IN.
SELECT * FROM product
WHERE product_name IN
(SELECT DISTINCT product_name FROM purchase);
UPDATE product SET product_price = product_price * 0.9
WHERE product_name NOT IN (SELECT DISTINCT product_name
FROM purchase);
853
86.
EXISTS
EXISTS использует подзапрос в качестве аргумента и
оценивает его как истинный, если в подзапросе есть
выходные данные, а в противном случае как ложный.
Выполняется подзапрос один раз и может содержать
несколько столбцов, поскольку их значения не проверяются,
а просто фиксируется результат наличия строк.
Примечания по предикату EXISTS:
• EXISTS – предикат, возвращающий значение TRUE или FALSE, и
его можно применять отдельно или вместе с другими булевыми
выражениями.
863
87.
EXISTS
SELECT * FROM product
WHERE EXISTS
(SELECT * FROM purchase
WHERE product.product_name = purchase.product_name);
873
88.
Групповые условия (операторы сравнения).
ALL — сравнение будет производиться со всеми записями, которые
возвращает подзапрос (или просто со всеми значениями в наборе). True
вернется только в том случае, если все записи, которые возвращает
подзапрос, будут удовлетворять указанному вами условию.
SELECT * FROM product
WHERE product_price >= ALL (SELECT product.product_price
FROM purchase, product
WHERE purchase.product_name = product.product_name
AND purchase.salesperson = ‘GA’);
Запрос вернёт все товары из таблицы product, цена которых больше или
равна цене каждого товара, проданного сотрудником с кодом ‘GA’.
883
89.
Групповые условия (операторы сравнения).
ANY — сравнение вернет true, если условию будет удовлетворять хотя бы одна
запись из подзапроса (или набора).
SELECT * FROM product WHERE product_price > ANY (SELECT
product.product_price
FROM purchase, product
WHERE purchase.product_name = product.product_name
AND purchase.salesperson = ‘GA’);
Запрос вернет все записи из таблицы product, для которых цена продукта
больше цены какого-либо продукта, проданного сотрудником с кодом ‘GA’.
SOME — делает то же самое, что ANY. Полностью взаимозаменяемы.
893
90.
Практическое задание № 5
1. Напишите запрос, который возвращает всех сотрудников, которых взяли на работу в то же
день, что и сотрудника John Smith.
2. Напишите запрос, который возвращает все товары, цена которых ниже средней цены.
3. Напишите запрос, который возвращает все товары, которые продавались более одного
раза.
4. Выведите увеличенную на 15% цену товаров, которые продавались более одного раза.
5. Используя условие EXISTS, напишите запрос, который возвращает всех сотрудников,
которые хотя бы один раз что-либо продали.
6. Напишите запрос, который возвращает все товары из таблицы product, цена которых
меньше цены любого товара, проданного сотрудником с кодом ‘GA’.
7. напишите запрос, который вернет все товары из таблицы product, цена которых меньше
цены хотя бы одного товара, проданного сотрудником с кодом ‘GA’. Убедитесь, что
операторы SOME и ANY взаимозаменяемы.
903
91.
SQL. Базовый курс
Часть 8. Функции для работы со строками, датами и
числами
www.aplana.ru
92.
Функции для работы с числами
ROUND — округляет числа с любой заданной точностью.
ROUND(входное_значение, число_знаков_после_десятичной_точки)
SELECT product_name, ROUND(product_price, 0)
FROM product;
SELECT ROUND(1234.5678, 3) —MSSQL
SELECT ROUND(1234.5678, 3) FROM DUAL;
Функция ROUND
ROUND(1234.5678,4)
ROUND( 1234.5678, 3)
ROUND( 1234.5678, 2)
ROUND( 1234.5678,1)
ROUND( 1234.5678,0)
ROUND(1234.5678, -1)
ROUND( 1234.5678,-2)
ROUND(1234.5678,-3)
923
Возвращаемое значение
1234.5678
1234.568
1234.57
1234.6
1235
1230
1200
1000
—Oracle
93.
Функции для работы с числами
TRUNC — усекает число, понижая его точность.
Функция TRUNC
Возвращаемое значение
TRUNC( 1234.5678,4)
1234.5678
TRUNC( 1234.5678,3)
1234.567
TRUNC( 1234.5678, 2) 1234.56
TRUNC( 1234.5678,1)
1234.5
TRUNC(1234.5678,0)
1234
TRUNC(1234.5678,-1)
1230
TRUNC( 1234.5678, -2) 1200
TRUNC( 1234.5678, -3) 1000
933
94.
Вспомогательные таблицы
Вспомогательные (dummy) таблицы
Для выполнения функций, без привязки к конкретным таблицам в ряде СУБД
необходимо указывать служебную таблицу, поскольку SQL подразумевает
конструкцию select … from.
• Oracle – DUAL
• DB2 – SYSDUMMY1
• SYBASE – DUMMY
• MySQL – DUAL
• MSSQL – отсутствует. MSSQL распознает служебные запросы без
необходимости указывать dummy-таблицу.
943
95.
Функции для работы с датами
GETDATE – возвращает текущую дату.
select getdate();
DATEADD – Возвращает дату, полученную как сумму исходной даты
date и интервала, добавленного к заданному компоненту datepart даты
date.
АDD_МONTHS(величина, количество, начальная дата)
SELECT DATEADD(month, 1, GETDATE());
SELECT DATEADD(year, -2, GETDATE());
953
96.
Функции для работы с датами
EOMONTH – возвращает последний день любого месяца, указанного
в переданной ей дате (MSSQL 2012+).
EOMONTH(дата)
SELECT EOMONTH(GETDATE());
SELECT EOMONTH(‘2015-03-15’);
SELECT first_name, last_name, hiredate, EOMONTH(hiredate)+1
FROM person;
963
97.
Функции для работы с датами
DATEDIFF – возвращает количество единиц, разделяющих две даты.
DATEDIFF(величина, начальная дата, конечная дата)
SELECT DATEDIFF(millisecond, GETDATE(), SYSDATETIME());
SELECT DATEDIFF(MONTH, ’17-AUG-2012′, GETDATE());
973
98.
Функции для работы с текстом
UPPER – ставит все символы строки в верхний регистр.
LOWER — ставит все символы строки в нижний регистр.
INITCAP (oracle) – изменяет регистр строки на смешанный (первая буква каждого
слова будет в верхнем регистре, остальное слово – в нижнем).
SELECT UPPER(product_name) FROM product;
SELECT LOWER(product_name) FROM product;
SELECT INITCAP(‘this TEXT hAd UNpredictABLE caSE’) FROM DUAL;
983
99.
Функции для работы с текстом
LEN – определяет длину строки.
SELECT product_name, LEN(product_name) LENGTH
FROM product
WHERE LEN(product_name) > 15;
993
100.
Функции для работы с текстом
SUBSTRING – обрезает значение в параметре.
SUBSTRING(исходный_текст, позиция начального символа,
количество символов)
SUBSTRING(строка 1, a, [,b])
Возвращает часть «Строка 1», начинающуюся с символа с номером a,
и имеющую длину b символов. Если a = 0, это равносильно тому, что
a = 1 (начало строки) если b положительно возвращаются символы
слева направо. Если b отрицательно то, начиная с конца строки и
считаются справа налево! Если b отсутствует, то по умолчанию
возвращаются все символы, до конца строки
100
3
101.
Функции для работы с текстом
SELECT SUBSTRING(item_id, 1, 3) LOCATION,
SUBSTRING(item_id, 5, 3) ITEM_NUMBER
FROM old_item;
101
3
102.
Функции для работы с текстом
CHARINDEX- находит позицию символа (или символов), разделяющего элементы
cтрок.
CHARINDEX(строка 1, строка 2, [,a])
Возвращает местоположение «строка 1», в «строка 2». «строка 2» просматривается
слева, начиная с позиции a. Если a отрицательно, то «строка 2», просматривается
справа. Значением по умолчанию для a является 1, что дает в результате позицию,
первого вхождения, «строка 1», в «строка 2». Если при заданной a, «строка 1» не
найдена, возвращается 0
102
3
103.
Функции для работы с текстом
CHARINDEX(искомый_символ, текст _для_поиска, позиция
_начального_символа)
SELECT item_desc, CHARINDEX(‘,’, item_desc, 1 )
FROM old_item;
103
3
104.
Вложение функций
SELECT item_desc, SUBSTRING(item_desc, 1, CHARINDEX(‘,’, item_desc, 1))
CATEGORY
FROM old_item;
104
3
105.
Вложение функций
105
3
SELECT item_desc,
SUBSTRING(item_desc, 1, CHARINDEX(‘,’, item_desc, 1)-1) CATEGORY,
SUBSTRING(item_desc, CHARINDEX(‘,’, item_desc, 1)+2, 99) ITEM_SIZE
FROM old_item;
106.
Практическое задание № 6
1. Использую функции для работы с датами и числами, посчитайте,
сколько вам полных лет.
2. Выведите строку ‘я ЗнаЮ тЕкСтовыЕ фУнкциИ’ в верхнем и
нижнем регистре.
3. Узнайте длину этой строки.
4. Работая со столбцом purchase.product_name, выведите:
• первые три символа
• все оставшиеся символы, начиная с четвёртого
• полную строку
106
3
107.
Полезные ресурсы
• http://sqlfiddle.com/ — инструмент, эмулирующий пустую БД:
позволяет выполнять значительную часть DML, DDR и DR
запросов. Поддерживает 5 основных диалектов
• http://www.sql-tutorial.ru/ — интерактивный учебник по SQL на
русском
• http://www.sql-ex.ru/ — интерактивный портал для решения
задач на SQL
• https://dev.mysql.com/downloads/mysql/ — бесплатный SQL
сервер под различные ОС
• https://www.mysql.com/products/workbench/ — бесплатный
инструмент для работы с MySql сервером
107
3
108.
Спасибо за внимание!
Ваши вопросы?
Компания «Аплана»
Сергей Воробьёв
Ведущий инженер-тестировщик
+7-917-556-13-49
www.aplana.ru