#статьи
-

0
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
({
<font color="#069">"firstName"</font> : <font color="#069">"Антон"</font>,
<font color="#069">"lastName"</font> : <font color="#069">"Яценко"</font>
});
Для того чтобы получить информацию в формате JSON, необходимо подготовить правильный HTTP-запрос:
var requestURL = 'test.json'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'json'; request.send();
В его структуре можно выделить пять логических частей:
- var requestURL — переменная с указанием на URL-адреса с необходимой информацией;
- var request = new XMLHttpRequest () — создание нового экземпляра объекта запроса из конструктора XMLHttpRequest с помощью ключевого слова new;
- request.open (‘GET’, requestURL) — открытие нового запроса с использованием метода GET. Обязательно указываем нашу переменную с URL-адресом;
- request.responseType = ‘json’ — явно обозначаем получаемый формат данных как JSON;
- request.send () — отправляем запрос на получение информации.
XML — язык разметки, который определяет набор правил для кодирования документов, записанных в текстовом формате. От JSON отличается большей сложностью — проще всего увидеть это на примере:
<font color="#069"><person></font> <font color="#069"><firstname></font>Антон<font color="#069"></firstname></font> <font color="#069"><lastname></font>Яценко<font color="#069"></lastname></font> <font color="#069"></person></font>
Чтобы получить информацию, хранящуюся на сервере как XML или HTML, потребуется воспользоваться той же библиотекой, как и в случае с JSON, но в качестве responseType следует указать Document.
var requestURL = 'test.txt'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'document'; request.send();
Какой из форматов лучше выбрать? Кажется, что JSON легче для восприятия. Но выбор между определённым форматом HTTP-запроса зависит и от решаемой задачи. Подробно обсудим это в будущих материалах.
А сегодня разберёмся с основами веб-скрейпинга — используем стандартные библиотеки Python и научимся работать с различными полезными инструментами.
Самый простой способ разобраться в парсинге — что-то спарсить. Создадим программу, которая будет показывать информацию о погоде в вашем городе.
Для этого пройдём через три последовательных шага:
- Подключим библиотеки, которые помогут нам спарсить информацию с помощью Python (как установить Python на Windows, macOS и Linux — смотрите в нашей статье).
- Зайдём на сайт, с которого мы планируем парсить информацию, и изучим его исходный код. Важно будет найти те элементы, которые содержат нужную информацию.
- Напишем код и спарсим данные.
Подключаем библиотеки
Подключаем библиотеки
В разных языках программирования есть свои библиотеки для парсинга информации с сайтов. Например, в JavaScript используется библиотека Puppeteer, а на Python популярна библиотека Beautiful Soup. Принципы их работы похожи. Но сначала нужно разобраться с запуском Python на компьютере.
Просто так написать код в текстовом документе не получится. Можно воспользоваться одним из способов:
- Использовать терминал на macOS или Linux, или воспользоваться командной строкой в Windows. Для этого предварительно потребуется установить Python в систему. Мы подробно писали об этом в отдельном материале.
- Воспользоваться одним из онлайн-редакторов, позволяющих работать с кодом на Python без его установки: Google Colab, python.org, onlineGDB или другим.
После установки на свой компьютер Python или запуска онлайн-редактора кода можно переходить к импорту библиотек.
BeautifulSoup — библиотека, которая позволяет работать с HTML- и XML-кодом. Подключить её очень просто:
from bs import BeautifulSoup
Дополнительно потребуется библиотека requests, которая помогает сделать запрос на нужный нам адрес сайта. Импортируется она в одну строку:
import requests
Всё. Все библиотеки готовы к работе — они помогут получить исходный код сайта и найти в нём нужную информацию.
Важно! Библиотека Beautiful Soup чаще всего предустановлена в используемой среде разработке или в Jupyter Notebook, но иногда её нет. Если при попытке её импорта вы получаете ошибку, то выполните команду для её установки, а потом повторите запросы на импорт:
pip3 install bs4
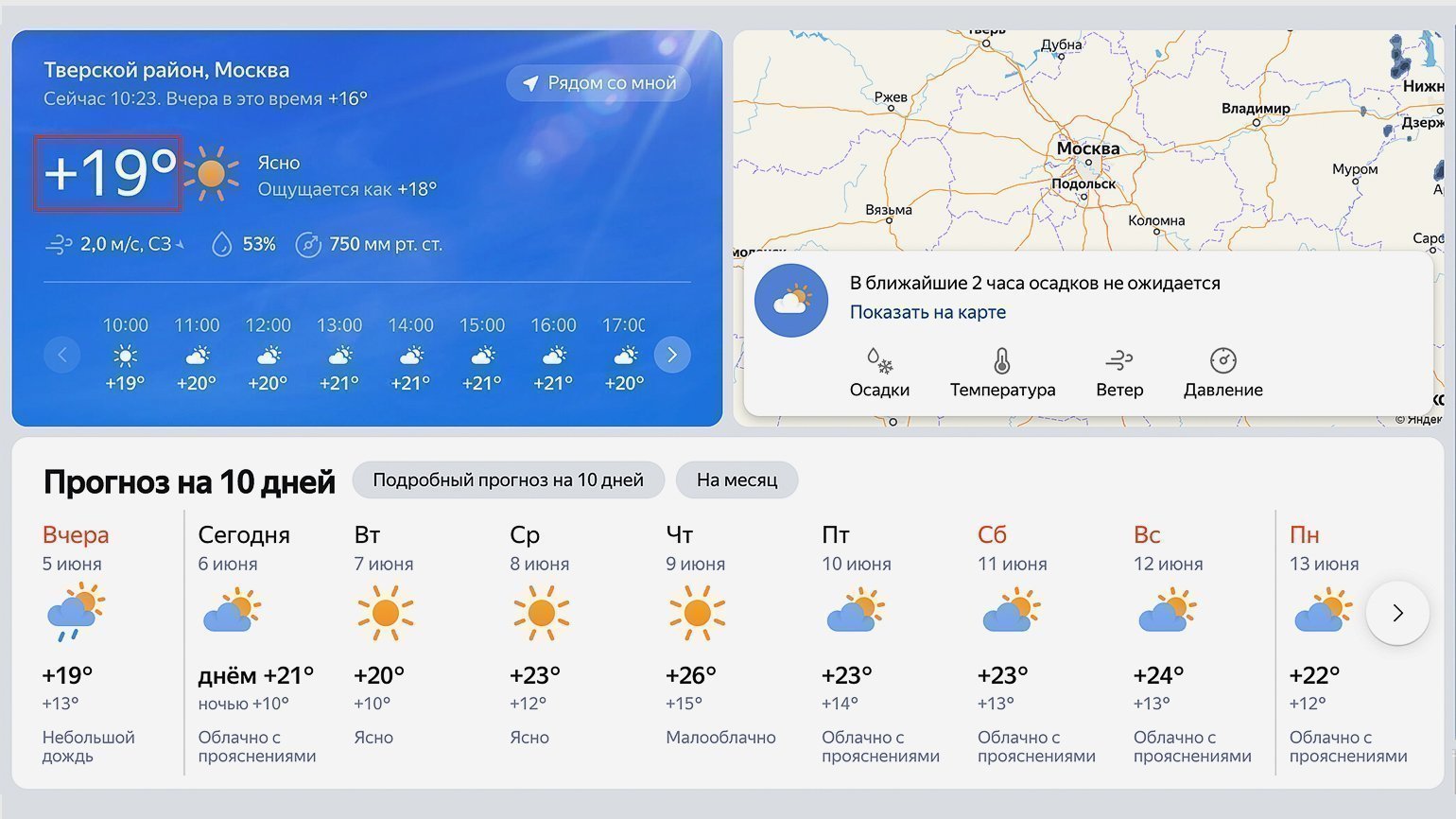
В качестве источника прогнозы погоды будем использовать сайт «Яндекс.Погода». Перейдём на него и в строке поиска найдём свой город. В нашем случае это будет Москва.
Посмотрите внимательно на адресную строку — она ещё пригодится нам в дальнейшем: https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526.
Обычно в адресной строке там нет названия города, а есть географические координаты точки, для которой показана текущая погода (у нас это центр Москвы).
Теперь посмотрим на исходный код страницы и найдём место, где хранится текущая температура. Нас интересует обведённый на скриншоте сайта блок:
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
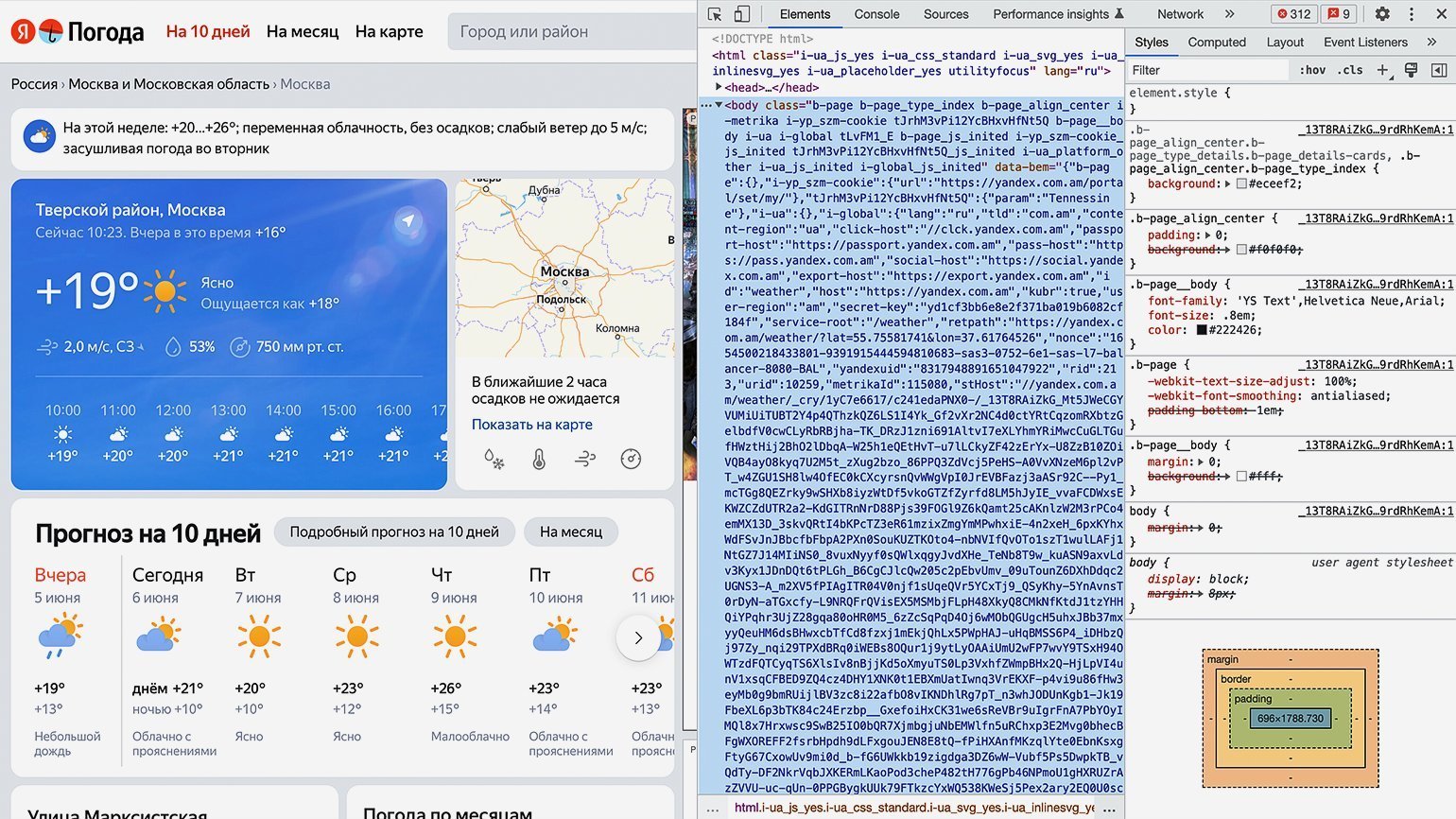
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега <body>. Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
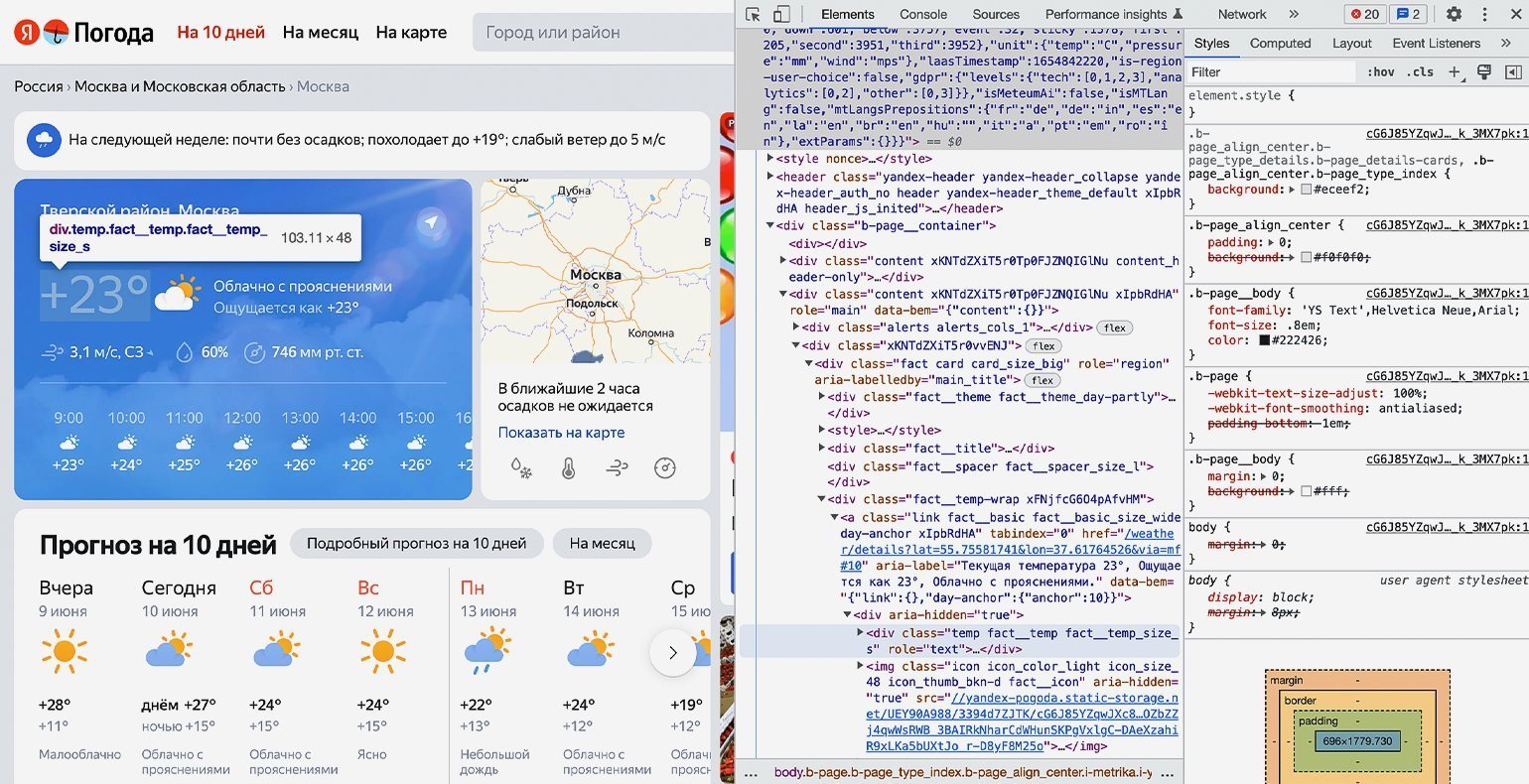
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента <span=»temp fact__temp fact__temp_size_s»>. Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:
url = 'https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526'
Создадим к ней запрос и посмотрим, что вернёт сервер:
response = requests.get(url) print(response)
В нашем случае получаем ответ:
<Response [200]>
Отлично. Ответ «200» значит, что библиотека requests работает правильно и сервер отдаёт нам информацию со страницы.
Теперь получим исходный код, используя библиотеку Beautiful Soup и сразу выведем результат на экран:
bs = BeautifulSoup(response.text,"lxml") print(bs)
После выполнения на экране виден код всей страницы полностью:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это <span=»temp fact__temp fact__temp_size_s»>. Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
Получаем:
<span class="temp__value temp__value_with-unit">+17</span>
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Результат:
+17
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.

Жизнь можно сделать лучше!
Освойте востребованную профессию, зарабатывайте больше и получайте от работы удовольствие. А мы поможем с трудоустройством и важными для работодателей навыками.
Посмотреть курсы
Время на прочтение
3 мин
Количество просмотров 167K
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
r = requests.get(URL_TEMPLATE)
print(r.status_code)
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text)
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
<h2 class="add-bottom-sm"><a href="/ru/jobs/3682040/" title="Комірник, вакансия от 5 ноября 2019">Комірник</a></h2>У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
for name in vacancies_names:
print(name.a['title'])
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
<p class="overflow">Some information about vacancy.</p>Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
print('https://www.work.ua'+name.a['href'])
for info in vacancies_info:
print(info.text)
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
FILE_NAME = "test.csv"
def parse(url = URL_TEMPLATE):
result_list = {'href': [], 'title': [], 'about': []}
r = requests.get(url)
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
result_list['href'].append('https://www.work.ua'+name.a['href'])
result_list['title'].append(name.a['title'])
for info in vacancies_info:
result_list['about'].append(info.text)
return result_list
df = pd.DataFrame(data=parse())
df.to_csv(FILE_NAME)
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
В этой статье мы рассмотрим, как создать базовый парсер сайта на Python, используя библиотеки BeautifulSoup и requests. Он сможет спарсить информацию со страниц сайта и сохранять ее для последующего анализа.
Что такое веб-парсинг?
Парсинг — это процесс извлечения данных из веб-страниц. Эти данные могут включать любую информацию, доступную на веб-странице: текст, ссылки, изображения, метаданные и т.д. Веб-парсеры используются для различных задач, включая мониторинг цен, анализ социальных медиа, веб-майнинг, веб-аналитику и т.д.
Необходимые инструменты
Для начала, нам необходимо установить две библиотеки Python: requests и beautifulsoup4. Это можно сделать при помощи pip:
pip install requests beautifulsoup4
Requests — это библиотека Python, что позволяет нам выполнять HTTP-запросы, а BeautifulSoup — мощная библиотека для парсинга HTML и XML документов.
Начало работы
Для демонстрации мы напишем простой веб-парсер, который соберет заголовки статей с главной страницы блога на условном домене example.com. Первым шагом будет получение HTML-кода страницы. Мы воспользуемся для этого библиотекой requests:
import requests
url = 'https://example.com/blog/'
response = requests.get(url)
Если все прошло гладко, response.text теперь содержит HTML-код главной страницы блога.
Парсинг HTML
Теперь, когда у нас есть HTML-код страницы, мы можем воспользоваться BeautifulSoup для его парсинга:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
BeautifulSoup преобразует HTML-строку в объект, с которым легко работать, предоставляя различные методы для навигации и поиска в HTML-структуре.
Поиск данных
С помощью BeautifulSoup мы можем использовать CSS-селекторы для поиска элементов на странице. Например, давайте найдем все заголовки статей на странице. Просмотрев код страницы, мы видим, что заголовки находятся в тегах <h2>, которые имеют класс blog-title.
titles = soup.select('h2.blog-title')
select возвращает список всех найденных элементов. Если нам нужен только первый найденный элемент, мы можем использовать метод select_one.
Извлечение данных
Теперь, когда мы нашли наши заголовки, мы можем вытянуть из них текст:
for title in titles:
print(title.get_text())
Используя метод get_text(), мы можем получить весь текст, который находится внутри элемента, включая все его дочерние элементы.
Сохранение данных
Последний шаг — это сохранение собранных данных. Мы можем сохранить их в файл, базу данных или любое другое место в зависимости от наших потребностей. Для простоты давайте сохраним их в текстовый файл:
with open('titles.txt', 'w') as f:
for title in titles:
f.write(title.get_text() + '\n')
Теперь у нас есть простой парсер, который собирает заголовки с сайта и сохраняет их в текстовый файл.
Итоги
В этой статье мы рассмотрели основы написания веб-парсера на Python с использованием библиотек requests и BeautifulSoup. Это базовый пример, но принципы, которые мы здесь использовали, могут быть применены для написания намного более сложных веб-парсеров. Благодаря Python и его прекрасным библиотекам, парсинг становится простым и доступным инструментом для сбора данных из Интернета.
Если вы хотите расширить свои знания и навыки в написании парсеров на Python, вот несколько рекомендаций:
- Изучить больше о CSS селекторах и их использовании в BeautifulSoup для поиска нужных элементов.
- Ознакомиться с различными методами для навигации по DOM-структуре, такими как .parent, .children, .next_sibling и другие.
- Рассмотреть использование других библиотек Python для веб-парсинга, таких как lxml, html5lib или PyQuery.
- Исследовать возможности использования веб-парсеров для автоматического заполнения форм, работы с авторизацией на сайтах и обхода защиты от парсинга (например, CAPTCHA).
Кроме того, при написании веб-парсеров важно учитывать этические аспекты и соблюдать правила использования веб-сайтов. Проверяйте, разрешен ли парсинг и уважайте ограничения на частоту запросов.
С опытом и соблюдением лучших практик, написание парсеров на Python станет неотъемлемой частью вашего набора навыков, которая поможет вам собирать и анализировать данные из Интернета для различных целей.
Освоить профессию python разработчика вы можете на нашем курсе Python с трудоустройством.
Веб-скрапинг – это процесс автоматического сбора информации
из онлайн-источников. Для выбора нужных сведений из массива «сырых» данных,
полученных в ходе скрапинга, нужна дальнейшая обработка – парсинг. В процессе
парсинга выполняются синтаксический анализ, разбор и очистка данных. Результат
парсинга – очищенные, упорядоченные, структурированные данные, представленные в
формате, понятном конечному пользователю (или приложению).
Скрипты для скрапинга создают определенную нагрузку на
сайт, с которого они собирают данные – могут, например, посылать чрезмерное
количество GET запросов к серверу. Это одна из причин, по которой
скрапинг относится к спорным видам деятельности. Чтобы не выходить за рамки
сетевого этикета, необходимо всегда соблюдать главные правила сбора публичной
информации:
- Если на сайте есть API, нужно запрашивать данные у него.
- Частота и количество GET запросов должны быть разумными.
- Следует передавать информацию о клиенте в
User-Agent. - Если на сайте есть личные данные пользователей, необходимо учитывать настройки приватности в robots.txt.
Необходимо отметить, что универсальных рецептов скрапинга и
парсинга не существует. Это связано со следующими причинами:
- Некоторые сервисы активно блокируют скраперов. Динамическая смена прокси не всегда помогает решить эту проблему.
- Контент многих современных сайтов генерируется динамически – результат обычного GET запроса из приложения к таким сайтам вернется практически пустым. Эта проблема решается с помощью Selenium WebDriver либо MechanicalSoup, которые имитируют действия браузера и пользователя.
Для извлечения данных со страниц с четкой, стандартной
структурой эффективнее использовать язык запросов XPath. И напротив, для
получения нужной информации с нестандартных страниц с произвольным синтаксисом
лучше использовать средства библиотеки BeautifulSoup. Ниже мы подробно рассмотрим оба подхода.
Экосистема Python располагает множеством инструментов для скрапинга и
парсинга. Начнем с самого простого примера – получения веб-страницы и
извлечения из ее кода ссылки.
Скрапинг содержимого страницы
Воспользуемся модулем urllib.request стандартной библиотеки urllib
для получения исходного кода одностраничного сайта example.com:
from urllib.request import urlopen
url = 'http://example.com'
page = urlopen(url)
print(page.read().decode('utf-8'))
Результат:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Точно такой же результат можно получить с помощью requests:
from bs4 import BeautifulSoup
import requests
url = 'http://example.com'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
print(soup)
Этот результат – те самые сырые данные, которые нужно
обработать (подвергнуть парсингу), чтобы извлечь из них нужную информацию,
например, адрес указанной на странице ссылки:
Парсинг полученных данных
Извлечь адрес ссылки можно 4 разными способами – с помощью:
- Методов строк.
- Регулярного выражения.
- Запроса XPath.
- Обработки BeautifulSoup.
Рассмотрим все эти способы по порядку.
Методы строк
Это самый трудоемкий способ – для извлечения каждого
элемента нужно определить 2 индекса – начало и конец вхождения. При этом к
индексу вхождения надо добавить длину стартового фрагмента:
from urllib.request import urlopen
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
start = html_code.find('href="') + 6
end = html_code.find('">More')
link = html_code[start:end]
print(link)
Результат:
https://www.iana.org/domains/example
Регулярное выражение
В предыдущей главе мы подробно рассматривали способы
извлечения конкретных подстрок из текста. Точно так же регулярные выражения
можно использовать для поиска данных в исходном коде страниц:
from urllib.request import urlopen
import re
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
link = r'(https?://\S+)(?=")'
print(re.findall(link, html_code))
Результат:
https://www.iana.org/domains/example
Запрос XPath
Язык запросов XPath (XML Path Language) позволяет извлекать данные из определенных узлов XML-документа. Для работы с HTML кодом в Python используют
модуль etree:
from urllib.request import urlopen
from lxml import etree
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
tree = etree.HTML(html_code)
print(tree.xpath("/html/body/div/p[2]/a/@href")[0])
Результат:
https://www.iana.org/domains/example
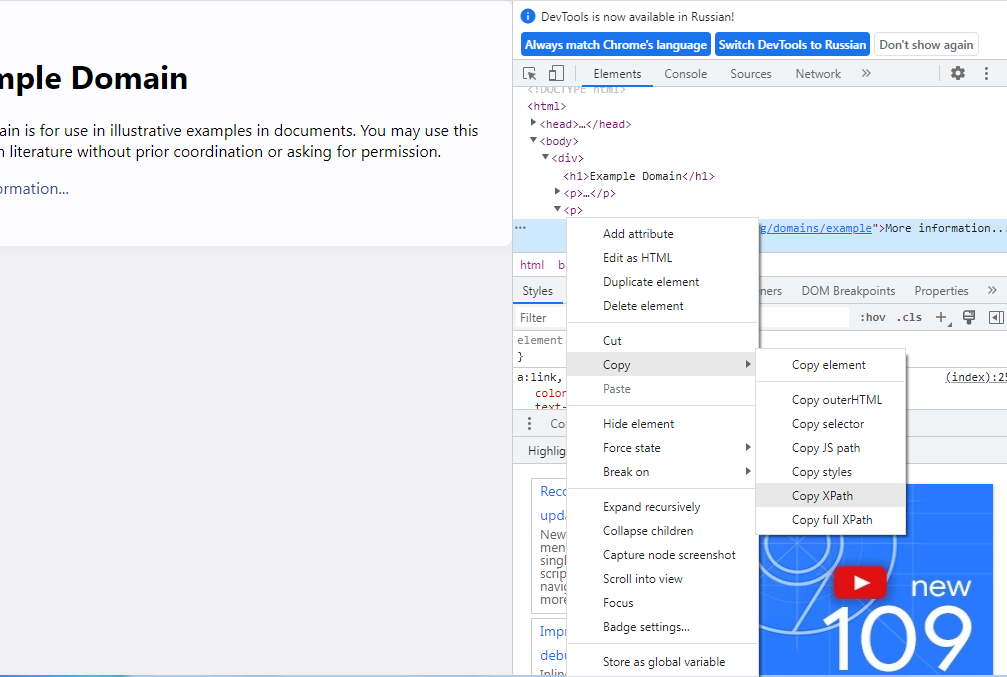
Чтобы узнать путь к нужному элементу страницы, в браузерах
Chrome
и FireFox надо
кликнуть правой кнопкой по элементу и выбрать «Просмотреть код», после чего
откроется консоль. В консоли по интересующему элементу нужно еще раз кликнуть
правой кнопкой, выбрать «Копировать», а затем – копировать путь XPath:
В приведенном выше примере для извлечения ссылки к пути
/html/body/div/p[2]/a/ мы добавили указание для получения значения ссылки @href,
и индекс [0], поскольку результат возвращается в виде списка. Если @hrefзаменить на
text(), программа вернет текст ссылки, а не сам URL:
print(tree.xpath("/html/body/div/p[2]/a/text()")[0])
Результат:
More information...
Парсер BeautifulSoup
Регулярные выражения и XPath предоставляют огромные возможности
для извлечения нужной информации из кода страниц, но у них есть свои
недостатки: составлять Regex-шаблоны
сложно, а запросы XPath
хорошо работают только на страницах с безупречной, стандартной структурой. К
примеру, страницы Википедии не отличаются идеальной структурой, и использование
XPath для извлечения
нужной информации из определенных элементов статей, таких как таблицы infobox, часто оказывается
неэффективным. В этом случае оптимальным вариантом становится BeautifulSoup,
специально разработанный для парсинга HTML-кода.
Библиотека BeautifulSoup не входит в стандартный набор Python, ее нужно установить
самостоятельно:
pip install beautifulsoup4
В приведенном ниже примере мы будем извлекать из исходного
кода страницы уникальные ссылки, за исключением внутренних:
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = 'https://webscraper.io/test-sites/e-commerce/allinone/phones'
page = urlopen(url)
html = page.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
links = set()
for link in soup.find_all('a'):
l = link.get('href')
if l != None and l.startswith('https'):
links.add(l)
for link in links:
print(link)
Результат:
https://twitter.com/webscraperio
https://www.facebook.com/webscraperio/
https://forum.webscraper.io/
https://webscraper.io/downloads/Web_Scraper_Media_Kit.zip
https://cloud.webscraper.io/
https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
При использовании XPath точно такой же результат даст следующий скрипт:
from urllib.request import urlopen
from lxml import etree
url = 'https://webscraper.io/test-sites/e-commerce/allinone/phones'
page = urlopen(url)
html_code = page.read().decode('utf-8')
tree = etree.HTML(html_code)
sp = tree.xpath("//li/a/@href")
links = set()
for link in sp:
if link.startswith('http'):
links.add(link)
for link in links:
print(link)
Имитация действий пользователя в браузере
При скрапинге сайтов очень часто требуется авторизация,
нажатие кнопок «Читать дальше», переход по ссылкам, отправка форм,
прокручивание ленты и так далее. Отсюда возникает необходимость имитации
действий пользователя. Как правило, для этих целей используют Selenium, однако есть и более легкое
решение – библиотека MechanicalSoup:
pip install MechanicalSoup
По сути, MechanicalSoup исполняет роль браузера без
графического интерфейса. Помимо имитации нужного взаимодействия с элементами
страниц, MechanicalSoup также парсит HTML-код, используя для этого все функции BeautifulSoup.
Воспользуемся тестовым сайтом http://httpbin.org/,
на котором есть возможность отправки формы заказа пиццы:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("http://httpbin.org/")
browser.follow_link("forms")
browser.select_form('form[action="/post"]')
print(browser.form.print_summary())
В приведенном выше примере браузер MechanicalSoup перешел по
внутренней ссылке http://httpbin.org/forms/post
и вернул описание полей ввода:
<input name="custname"/>
<input name="custtel" type="tel"/>
<input name="custemail" type="email"/>
<input name="size" type="radio" value="small"/>
<input name="size" type="radio" value="medium"/>
<input name="size" type="radio" value="large"/>
<input name="topping" type="checkbox" value="bacon"/>
<input name="topping" type="checkbox" value="cheese"/>
<input name="topping" type="checkbox" value="onion"/>
<input name="topping" type="checkbox" value="mushroom"/>
<input max="21:00" min="11:00" name="delivery" step="900" type="time"/>
<textarea name="comments"></textarea>
<button>Submit order</button>
Перейдем к имитации заполнения формы:
browser["custname"] = "Best Customer"
browser["custtel"] = "+7 916 123 45 67"
browser["custemail"] = "trex@example.com"
browser["size"] = "large"
browser["topping"] = ("cheese", "mushroom")
browser["comments"] = "Add more cheese, plz. More than the last time!"
Теперь форму можно отправить:
response = browser.submit_selected()
Результат можно вывести с помощью print(response.text):
{
"args": {},
"data": "",
"files": {},
"form": {
"comments": "Add more cheese, plz. More than the last time!",
"custemail": "trex@example.com",
"custname": "Best Customer",
"custtel": "+7 916 123 45 67",
"delivery": "",
"size": "large",
"topping": [
"cheese",
"mushroom"
]
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "191",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"Referer": "http://httpbin.org/forms/post",
"User-Agent": "python-requests/2.28.1 (MechanicalSoup/1.2.0)",
"X-Amzn-Trace-Id": "Root=1-6404d82d-2a9ae95225dddaec1968ccb8"
},
"json": null,
"origin": "86.55.39.89",
"url": "http://httpbin.org/post"
}
Скрапинг и парсинг динамического контента
Все примеры, которые мы рассмотрели выше, отлично работают
на статических страницах. Однако на множестве платформ используется
динамический подход к генерации и загрузке контента – к примеру, для просмотра
всех доступных товаров в онлайн-магазине страницу нужно не только открыть, но и
прокрутить до футера. Для работы с динамическим контентом в Python нужно установить:
- Модуль Selenium.
- Драйвер Selenium WebDriver для браузера.
Если установка прошла успешно, выполнение этого кода приведет к
автоматическому открытию страницы:
from selenium import webdriver
driver = webdriver.Chrome() # или webdriver.Firefox()
driver.get('https://google.com')
Бывает, что даже после установки оптимальной версии драйвера
интерпретатор Python возвращает ошибку OSError: [WinError 216] Версия. В этом случае нужно
"%1" не совместима с версией Windows
воспользоваться модулем webdriver—manager, который самостоятельно
установит подходящий драйвер для нужного браузера:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
Имитация прокрутки страницы и парсинг данных
В качестве примера скрапинга и парсинга динамического сайта
мы воспользуемся разделом тестового
онлайн-магазина. Здесь расположены карточки с информацией о планшетах.
Карточки загружаются ряд за рядом при прокрутке страницы:
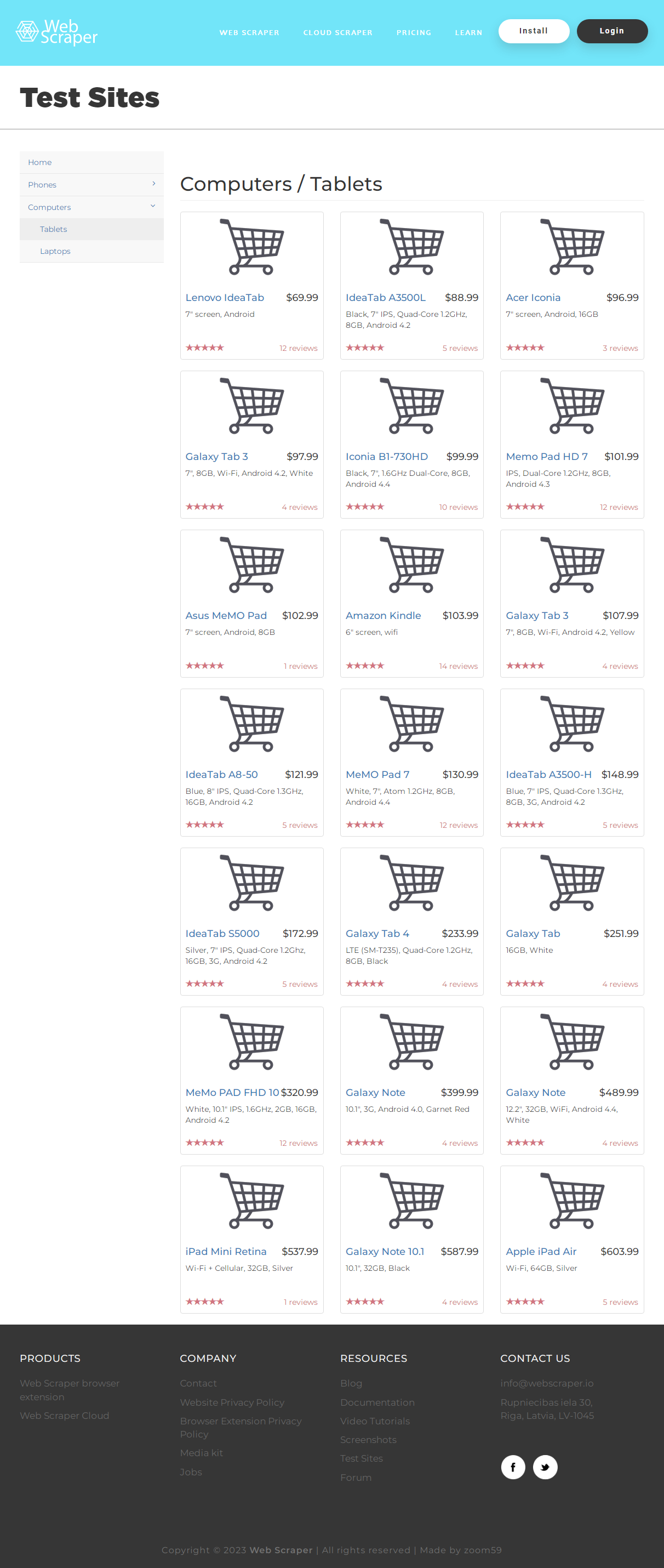
Пока страница не прокручена, полный HTML-код с информацией о планшетах
получить невозможно. Для имитации прокрутки мы воспользуемся скриптом 'window.scrollTo(0,. Цены планшетов находятся в тегах h4 класса pull-right price, а
document.body.scrollHeight);'
названия моделей – в тексте ссылок a класса title. Готовый код
выглядит так:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager(cache_valid_range=10).install()))
url = 'https://webscraper.io/test-sites/e-commerce/scroll/computers/tablets'
driver.get(url)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(5)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
prices = soup.find_all('h4', class_='pull-right price')
models = soup.find_all('a', class_='title')
for model, price in zip(models, prices):
m = model.get_text()
p = price.get_text()
print(f'Планшет {m}, цена - {p}')
Результат:
Планшет Lenovo IdeaTab, цена - $69.99
Планшет IdeaTab A3500L, цена - $88.99
Планшет Acer Iconia, цена - $96.99
Планшет Galaxy Tab 3, цена - $97.99
Планшет Iconia B1-730HD, цена - $99.99
Планшет Memo Pad HD 7, цена - $101.99
Практика
Задание 1
Напишите программу для получения названий последних статей из блога издательства O’Reilly:
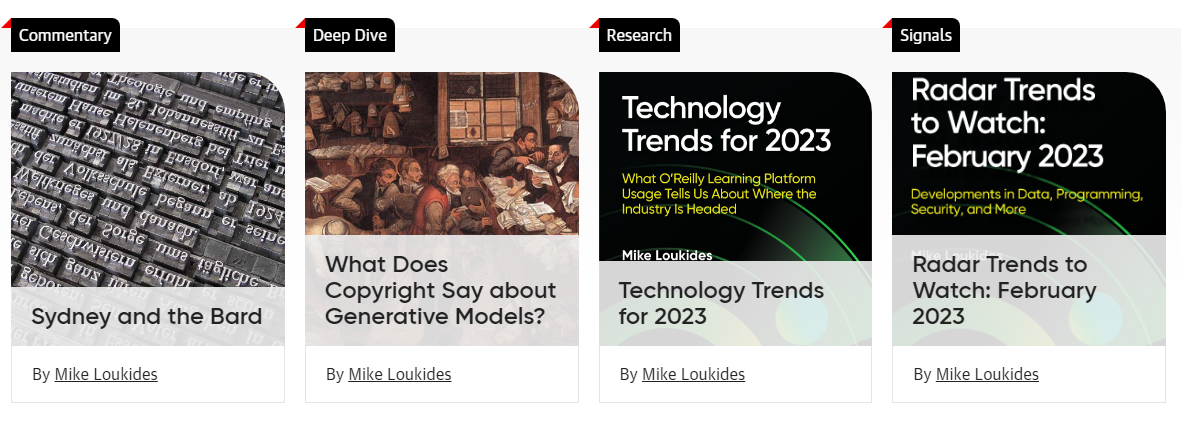
Пример результата:
Sydney and the Bard
What Does Copyright Say about Generative Models?
Technology Trends for 2023
Radar Trends to Watch: February 2023
Решение:
from bs4 import BeautifulSoup
import requests
url = 'https://www.oreilly.com/radar/'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
sp = soup.find_all('h2', class_='post-title')
for post in sp:
print(post.get_text())
Задание 2
Напишите программу для определения 10 слов, которые чаще
всего встречаются в тексте сказки «Колобок» (без учета регистра). Предлоги
учитывать не нужно.
Ожидаемый результат:
колобок - 32
ушел - 14
тебя - 7
коробу - 6
сусеку - 6
сметане - 5
масле - 5
покатился - 4
катится - 4
навстречу - 4
Решение:
from bs4 import BeautifulSoup
import requests
import re
url = 'https://azku.ru/russkie-narodnie-skazki/kolobok.html'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
res = soup.find_all('div', class_='entry-content')
text = res[0].get_text().split('Мне нравится')[0]
sp = re.sub(r'[-,.?!"—:]', ' ', text).lower().split()
result_dict = {word: sp.count(word) for word in sp if len(word) > 3}
max_values = sorted(result_dict.items(), key=lambda x:x[1], reverse=True)[:10]
for word, number in max_values:
print(f'{word} - {number}')
Задание 3
Напишите программу, которая на основе данных
таблицы создает список цитат из фильмов, выпущенных после 1995 года.
Ожидаемый результат:
Show me the money! Покажи мне деньги! Род Тидвелл Кьюба Гудинг мл. Джерри Магуайер 1996
I see dead people. Я вижу мёртвых людей. Коул Сиэр Хэйли Джоэл Осмент Шестое чувство 1999
You had me at 'hello'. Я была твоя уже на «здрасьте». Дороти Бойд Рене Зеллвегер Джерри Магуайер 1996
My precious. Моя прелесть. Голлум Энди Серкис Властелин колец: Две крепости 2002
I’m the king of the world! Я король мира! Джек Доусон Леонардо Ди Каприо Титаник 1997
Решение:
from bs4 import BeautifulSoup
import requests
import re
url = 'https://ru.wikipedia.org/wiki/100_%D0%B8%D0%B7%D0%B2%D0%B5%D1%81%D1%82%D0%BD%D1%8B%D1%85_%D1%86%D0%B8%D1%82%D0%B0%D1%82_%D0%B8%D0%B7_%D0%B0%D0%BC%D0%B5%D1%80%D0%B8%D0%BA%D0%B0%D0%BD%D1%81%D0%BA%D0%B8%D1%85_%D1%84%D0%B8%D0%BB%D1%8C%D0%BC%D0%BE%D0%B2_%D0%B7%D0%B0_100_%D0%BB%D0%B5%D1%82_%D0%BF%D0%BE_%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D0%B8_AFI'
res = requests.get(url).text
soup = BeautifulSoup(res,'html.parser')
table = soup.find('table', class_='wikitable')
header = table.find_all('th')
quotes = table.find_all('tr')
quotes_after_1995 = []
for i in range(1, len(quotes)):
q = quotes[i].get_text()
if int(q[-5:]) > 1995:
quotes_after_1995.append(' '.join(q.split('\n\n')[1:]).replace('\n', ''))
for quote in quotes_after_1995:
print(quote)
Задание 4
Напишите программу, которая извлекает
данные о моделях, конфигурации и стоимости 117-ти ноутбуков, и записывает
полученную информацию в csv
файл.
Ожидаемый результат:
Модель;Описание;Цена
Asus VivoBook X441NA-GA190;Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd;$295.99
...
Asus ROG Strix SCAR Edition GL503VM-ED115T;Asus ROG Strix SCAR Edition GL503VM-ED115T, 15.6" FHD 120Hz, Core i7-7700HQ, 16GB, 256GB SSD + 1TB SSHD, GeForce GTX 1060 6GB, Windows 10 Home;$1799.00
Решение:
from bs4 import BeautifulSoup
import requests
url = 'https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
models = soup.find_all('a', class_='title')
description = soup.find_all('p', class_='description')
prices = soup.find_all('h4', class_='pull-right price')
with open('laptops.csv', 'w', encoding='utf-8') as file:
file.write(f'Модель;Описание;Цена\n')
for m, d, p in zip(models, description, prices):
file.write(f"{m['title']};{d.get_text()};{p.get_text()}\n")
Задание 5
Напишите программу для скачивания полноразмерных обложек из профилей
книг на LiveLib. Обложки открываются после двойного клика по миниатюре:
Решение:
from bs4 import BeautifulSoup
import requests
import re
url = 'https://www.livelib.ru/book/1002978643-ohotnik-za-tenyu-donato-karrizi'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
sp = soup.find('div', class_='bc-menu__image-wrapper')
img_url = re.findall(r'(?:https\:)?//.*\.(?:jpeg)', str(sp))[0]
response = requests.get(img_url, headers=headers)
if response.status_code == 200:
file_name = url.split('-', 1)[1]
with open(file_name + '.jpeg', 'wb') as file:
file.write(response.content)
Задание 6
Напишите программу, которая составляет рейтинг топ-100
лучших триллеров на основе этого
списка.
Пример результата:
1. "Побег из Шоушенка", Стивен Кинг - 4.60
2. "Заживо в темноте", Майк Омер - 4.50
3. "Молчание ягнят", Томас Харрис - 4.47
4. "Девушка с татуировкой дракона", Стиг Ларссон - 4.42
5. "Внутри убийцы", Майк Омер - 4.38
...
98. "Абсолютная память", Дэвид Болдаччи - 4.22
99. "Сломанные девочки", Симона Сент-Джеймс - 4.11
100. "Цифровая крепость", Дэн Браун - 3.98
Решение:
from bs4 import BeautifulSoup
import requests
url = 'https://www.livelib.ru/genre/%D0%A2%D1%80%D0%B8%D0%BB%D0%BB%D0%B5%D1%80%D1%8B/top'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content,'html.parser')
titles = soup.find_all('a', class_='brow-book-name with-cycle')
authors = soup.find_all('a', class_='brow-book-author')
rating = soup.find_all('span', class_='rating-value stars-color-orange')
i = 1
for t, a, r in zip(titles, authors, rating):
print(f'{i}. "{t.get_text()}", {a.get_text()} - {r.get_text()}')
i += 1
Задание 7
Напишите программу, которая составляет топ-20 языков
программирования на основе рейтинга популярности TIOBE.
Пример результата:
1. Python: 14.83%
2. C: 14.73%
3. Java: 13.56%
4. C++: 13.29%
5. C#: 7.17%
6. Visual Basic: 4.75%
7. JavaScript: 2.17%
8. SQL: 1.95%
9. PHP: 1.61%
10. Go: 1.24%
11. Assembly language: 1.11%
12. MATLAB: 1.08%
13. Delphi/Object Pascal: 1.06%
14. Scratch: 1.00%
15. Classic Visual Basic: 0.98%
16. R: 0.93%
17. Fortran: 0.79%
18. Ruby: 0.76%
19. Rust: 0.73%
20. Swift: 0.71%
Решение:
import requests
from lxml import html
url = 'https://www.tiobe.com/tiobe-index/'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
page = requests.get(url, headers=headers)
tree = html.fromstring(page.content)
languages, rating = [], []
for i in range(1, 21):
languages.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[{i}]/td[5]/text()')[0])
rating.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[{i}]/td[6]/text()')[0])
i = 1
for l, r in zip(languages, rating):
print(f'{i}. {l}: {r}')
i += 1
Задание 8
Напишите программу для получения рейтинга 250 лучших фильмов
по версии IMDb. Названия должны
быть на русском языке.
Пример результата:
1. Побег из Шоушенка, (1994), 9,2
2. Крестный отец, (1972), 9,2
3. Темный рыцарь, (2008), 9,0
...
248. Аладдин, (1992), 8,0
249. Ганди, (1982), 8,0
250. Танцующий с волками, (1990), 8,0
Решение:
import requests
from lxml import html
url = 'https://www.imdb.com/chart/top/'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
"Accept-Language": "ru-RU"}
page = requests.get(url, headers=headers)
tree = html.fromstring(page.content)
movies, year, rating = [], [], []
for i in range(1, 251):
movies.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[{i}]/td[2]/a/text()')[0])
year.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[{i}]/td[2]/span/text()')[0])
rating.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[{i}]/td[3]/strong/text()')[0])
i = 1
for m, y, r in zip(movies, year, rating):
print(f'{i}. {m}, {y}, {r}')
i += 1
Задание 9
Напишите программу, которая сохраняет в текстовый файл
данные о фэнтези фильмах с 10 первых страниц
соответствующего раздела IMDb.
Если у фильма/сериала еще нет рейтинга, следует указать N/A.
Ожидаемый результат в файле fantasy.txt – 500 записей:
Мандалорец, (2019– ), 8,7
Всё везде и сразу, (2022), 8,0
Атака титанов, (2013–2023), 9,0
Peter Pan & Wendy, (2023), N/A
Игра престолов, (2011–2019), 9,2
...
Шрэк 3, (2007), 6,1
Кунг-фу Панда 3, (2016), 7,1
Смерть ей к лицу, (1992), 6,6
Исход: Цари и боги, (2014), 6,0
Кошмар на улице Вязов 3: Воины сна, (1987), 6,6
Решение:
import requests
import mechanicalsoup
from lxml import html
import time
url = 'https://www.imdb.com/search/title/?genres=fantasy'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
"Accept-Language": "ru-RU"}
browser = mechanicalsoup.StatefulBrowser()
j = 51
for _ in range(10):
browser.open(url)
page = requests.get(url, headers=headers)
tree = html.fromstring(page.content)
titles, year, rating = [], [], []
for i in range(1, 51):
if tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/p[1]/b/text()') != []:
titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/h3/a/text()')[0])
year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/h3/span[2]/text()')[0])
rating.append('N/A')
else:
titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/h3/a/text()')[0])
year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/h3/span[2]/text()')[0])
rating.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[{i}]/div[3]/div/div[1]/strong/text()')[0])
with open('fantasy.txt', 'a', encoding='utf-8') as file:
for t, y, r in zip(titles, year, rating):
file.write(f'{t}, {y}, {r}\n')
time.sleep(2)
lnk = browser.follow_link('start=' + str(j))
url = browser.url
j += 50
Задание 10
Напишите программу для получения главных новостей (на
русском) с портала Habr. Каждый
заголовок должен сопровождаться ссылкой на полный текст новости.
Пример вывода:
Bethesda назвала дату релиза Starfield на ПК, Xbox Series и Xbox Game Pass — 6 сентября 2023 года
https://habr.com/ru/news/t/721148/
Honda запатентовала съёмные подушки безопасности для мотоциклистов
https://habr.com/ru/news/t/721142/
...
Microsoft увольняет 689 сотрудников из своих офисов в Сиэтле
https://habr.com/ru/news/t/721010/
«Ъ»: в России образовались большие запасы бытовой техники из-за низкого спроса
https://habr.com/ru/news/t/721006/
Решение:
from bs4 import BeautifulSoup
import requests
url = 'https://habr.com/ru/news/'
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
"Accept-Language": "ru-RU"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.content,'html.parser')
articles = soup.find_all('a', class_='tm-article-snippet__title-link')
for a in articles:
print(f'{a.get_text()}\nhttps://habr.com{a.get("href")}')
Заключение
Мы рассмотрели основные приемы работы с главными Python-инструментами для скрапинга и парсинга. Способы извлечения и обработки данных варьируются от
сайта к сайту – в некоторых случаях эффективнее использование XPath, в других – разбор с BeautifulSoup, а иногда может
потребоваться применение регулярных выражений.
В следующей главе приступим к изучению основ ООП (объектно-ориентированного программирования).
***
Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП – инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
- Основы разработки игр на Pygame
- Основы работы с SQLite
- Основы веб-разработки на Flask
- Основы работы с NumPy
- Основы анализа данных с Pandas
***
Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
“Requests” — это наша следующая библиотека для установки. Ее задача – запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
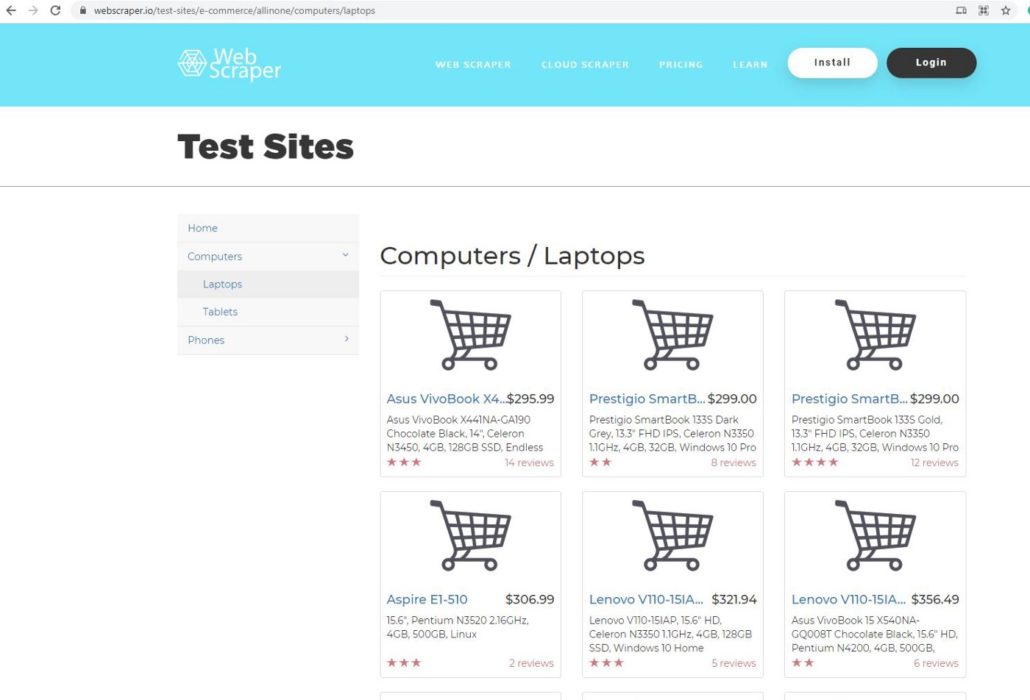
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
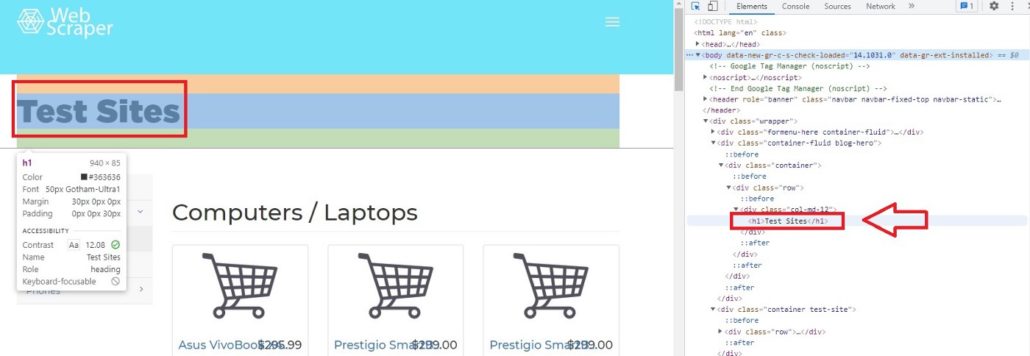
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
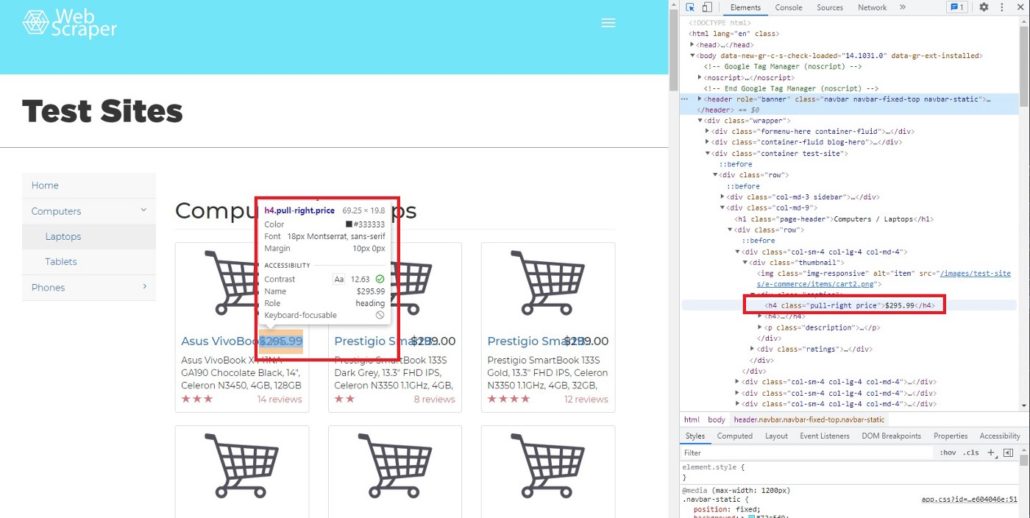
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica – напишите письмо или заполните заявку указав все детали задачи по парсингу.
Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием Beautiful Soup (Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте realpython.com, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал: Beautiful Soup: Build a Web Scraper With Python.
Цель: Fake Python Job Site
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.

Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
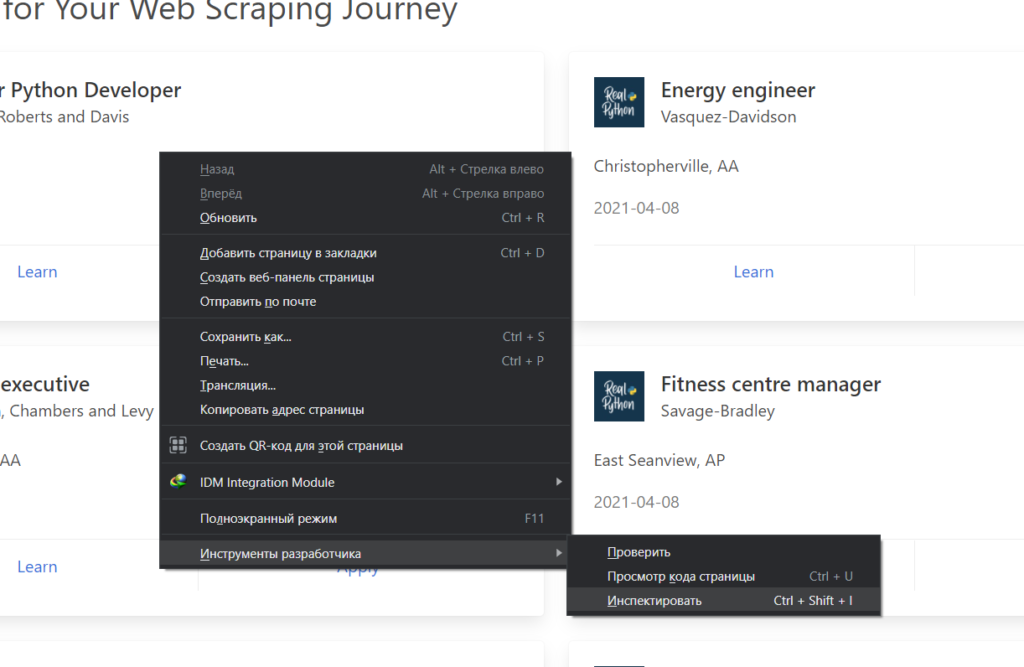
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
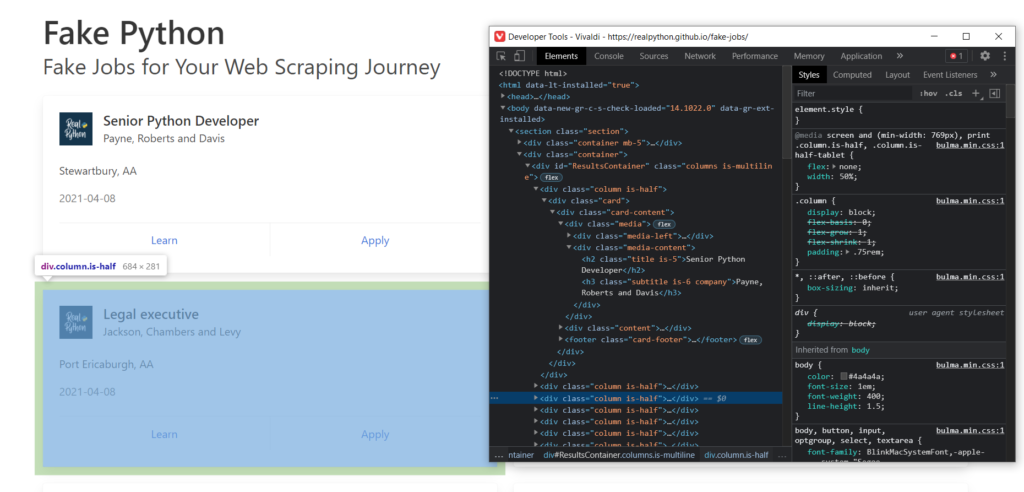
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4. Их устанавливаем через терминал при помощи команд:
|
python —m pip install beautifulsoup4 |
и
|
python —m pip install requests |
После чего пишем следующий код:
|
import requests from bs4 import BeautifulSoup URL = «https://realpython.github.io/fake-jobs/» page = requests.get(URL) soup = BeautifulSoup(page.content, «html.parser») |
Тут мы импортируем новые библиотеки. URL это строка, она содержит ссылку на сайт. При помощи requests.get мы совершаем запрос к веб страничке. Сама функция возвращает ответ от сервера (200, 404 и т.д.), а page.content предоставляет нам полный код загруженной страницы. Тот же код, который мы видели в инспекторе.
Для большего понимания можно вывести принтом оба варианта:
|
print(page) print(page.content) |

Первый дал ответ 200, т.е. ОК. А дальше идёт тот самый будущий суп из html, который нам и нужно будет разобрать.
В следующей строке и вступает в игру BeautifulSoup, куда мы передаём первым аргументом весь код страницы, а вторым указываем, что это анализировать будем именно html.
Хотите увидеть результат? Давайте выведем объект soup.
Да, это всё тот же код, но уже сейчас куда более читаемый. Технически, вы уже получили код страницы при помощи python, но информация в таком виде содержит слишком много лишнего. И сейчас мы научимся его отсекать.
Ищем элементы по ID
Как вы могли заметить, наблюдая за html кодом, есть много блоков с различными параметрами, class, id и т.д. Часто именно id делает элементы разметки уникальными и по этому параметру можно найти интересующие нас части.
Если брать во внимание разбираемый нами сайт, то вы могли заметить, что все отдельные карточки находятся внутри одного объекта div с id = ResultsContainer:
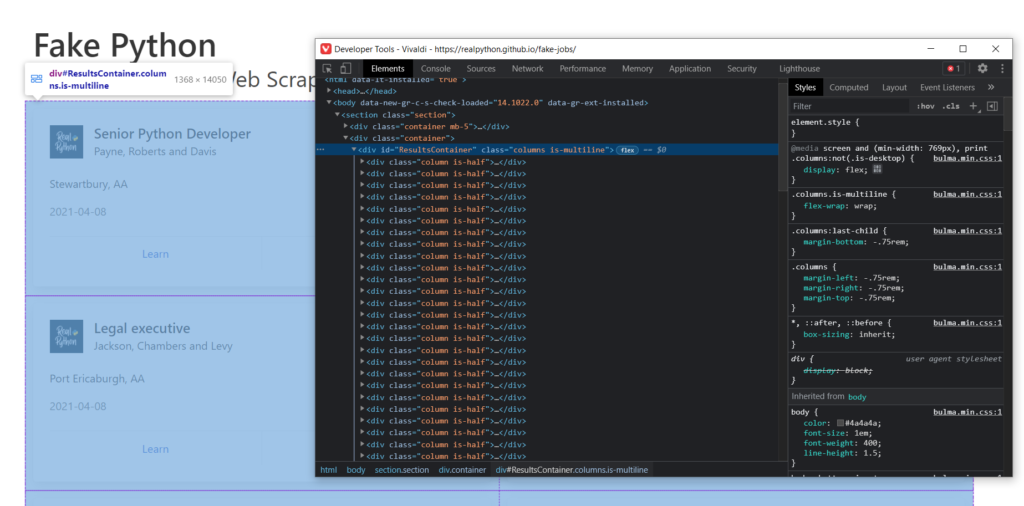
Это нам подходит. Так и пишем, а заодно и выведем результат:
|
results = soup.find(id=«ResultsContainer») print(results) |
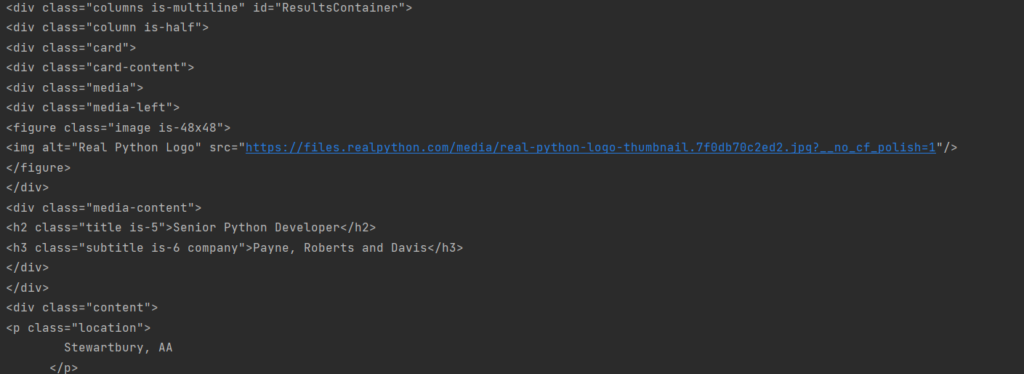
Теперь мы получили только выбранный блок. Да, всё ещё не особо читаемое, да и форматирование не отражает иерархии. С первым мы разберемся далее, а вот второе исправить достаточно просто. Вместо простого принта объекта мы можем использовать функцию prettify.
|
print(results.prettify()) |
А результат станет несколько приятнее для чтения:
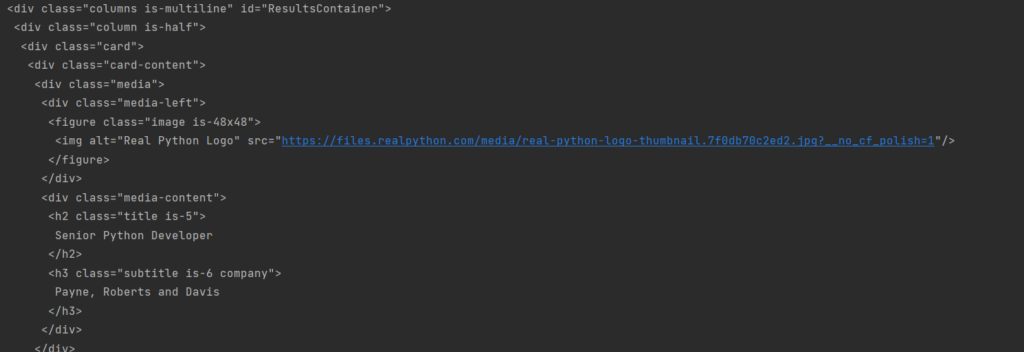
И да, мы получили уже конкретный блок необходимых данных, но это только начало.
Ищем элементы по имени класса
Смотрим дальше. Внутри каждой из полученных карточек есть объект с классом card-content. Мы можем это использовать, чтобы получить массив из всех элементов, которые содержат этот класс.
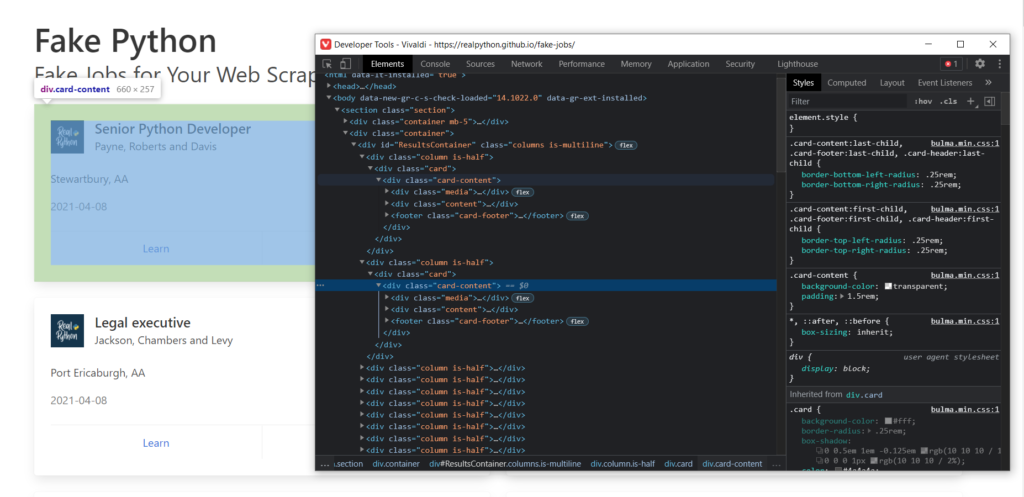
Но так как мы хотим получить только элементы из последнего блока данных, а не всего сайта, то теперь вызываем find_all не от soup, а от results. Достаточно простая система.
|
job_elements = results.find_all(«div», class_=«card-content») for job in job_elements: print(«\n\n») print(job.prettify()) |
Я сразу вывел каждую карточку отдельно, но с отступами:
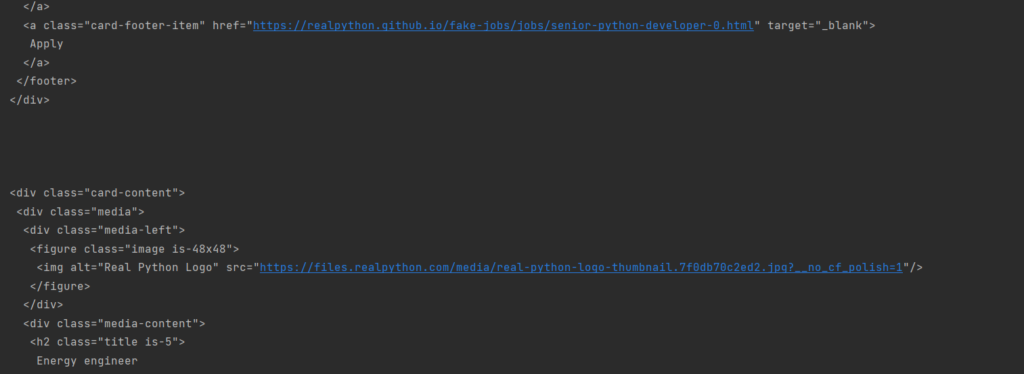
Теперь это не один блок кода, а множество однообразных маленьких. А мы ещё на шаг ближе к цели.
Посмотрим на первый элемент. Тут есть элемент h2 и элемент h3. Они отображают должность и компанию соответственно. При этом у них есть ещё и особые классы: title и company. А ещё есть параграф p с классом location.
Но p, h2 и h3 это не id и не class, так что немного изменим наши параметры для более точной работы функции find.
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element) print(company_element) print(location_element) print() |
Запустите. Теперь выбираем только тогда, когда конкретный компонент имеет указанный класс. Так получим подходящие данные из карточек. Правда, всяк с html кодом. Но чтобы его отбросить просто в print добавляем .text:
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element.text) print(company_element.text) print(location_element.text) print() |
Вывод:
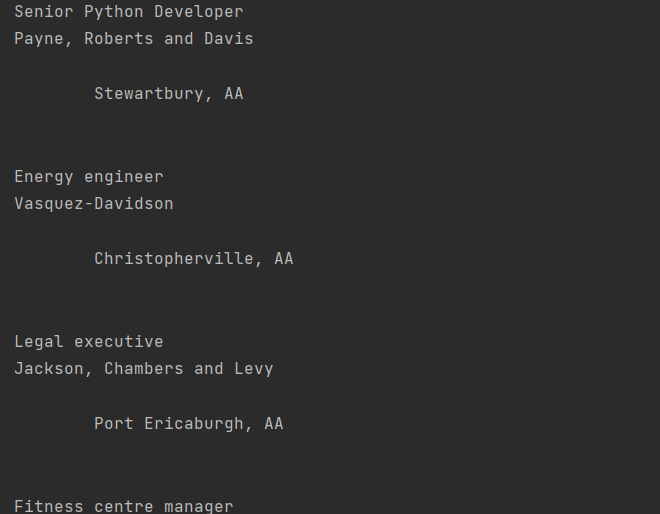
Почти, но местоположение куда-то отпрыгивает из-за наличия кучи лишних отступов. Но так как мы уже выводим не какие-то объекты BS4, а обычные питоновские строки, то мы можем использовать .strip() чтобы удалить все пробелы в начале и конце строки:
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element.text.strip()) print(company_element.text.strip()) print(location_element.text.strip()) print() |
Теперь мы получили большой список должностей, компаний и их местоположений, который в точности совпадает с сайтом, так как и взят именно оттуда. Для наглядности сравним:
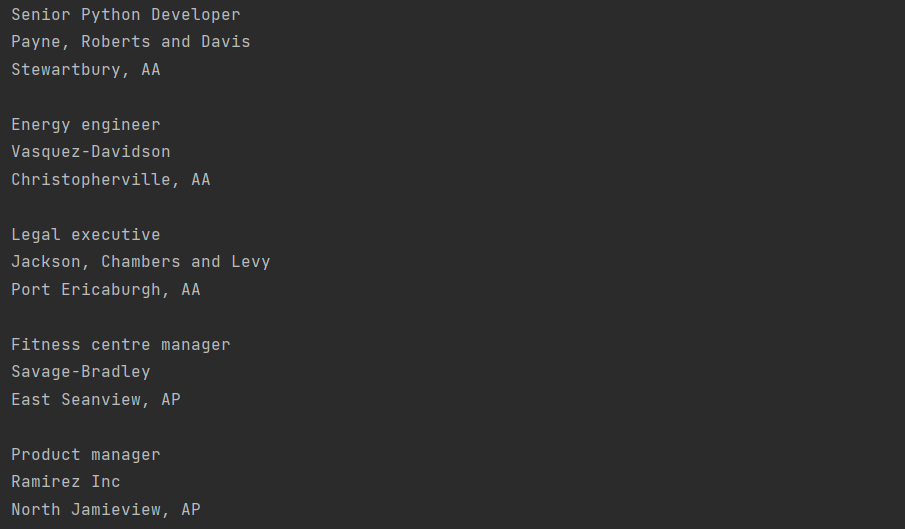
Ищем элементы по содержимому
Да, мы вывели буквально ВСЕ доступные профессии. Но BeautifulSoup позволяет не только найти по параметрам, но и отсеять по-содержимому. Предлагаю закомментировать список всех работ и дописать новый запрос:
|
# job_elements = results.find_all(«div», class_=»card-content») # # for job in job_elements: # title_element = job.find(«h2″, class_=»title») # company_element = job.find(«h3″, class_=»company») # location_element = job.find(«p», class_=»location») # print(title_element.text.strip()) # print(company_element.text.strip()) # print(location_element.text.strip()) # print() python_jobs = results.find_all(«h2», string=«Python») print(python_jobs) |
И запускаем.
Ничего? Не удивительно. Попробуйте найти там вакансию, которая состоит из одного только слова Python. Find_all ищет точное соответствие для такого запроса, но таких в списке нет. Как вы знаете, даже регистр будет влиять на результат, и это нужно учитывать.
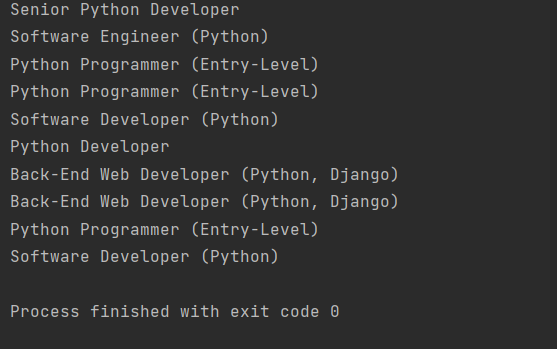
Если мы хотим включить все карточки, где есть определённое слово (python, например), то нужно использовать лямбда функцию. Изменим код выше на этот:
|
python_jobs = results.find_all( «h2», string=lambda text: «python» in text.lower() ) for job_title in python_jobs: print(job_title.text.strip()) |
И теперь мы передали string= не конкретный текст, а функцию, при выполнении условий которой элемент будет добавлен. Запускаем снова. Теперь у нас отобразили целый список подходящих вакансий:
Обращаемся к родителям найденных результатов
Смотрите, только что мы выбрали только заголовки должностей, но компании и остальные данные оказались вне выборки. Но мы знаем, что заголовок h3 с названием компании был в том же блоке, что и заголовок h2 названием должности. Следовательно, если мы перейдём в родителя h2, то сможем выйти и на h3.
|
<div class=«media-content»> <h2 class=«title is-5»>Senior Python Developer</h2> <h3 class=«subtitle is-6 company»>Payne, Roberts and Davis</h3> </div> |
Давайте попробуем это сделать.
Меняем последний цикл, который выводил выбранные вакансии с питоном на такой блок:
|
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») print(job_title.text.strip()) print(company_element.text.strip()) print() |
В первой же строке я при помощи .parent обращаюсь к родителю заголовка, а это div с классом с media-content, а уже в нём ищу h3 company. И нахожу:
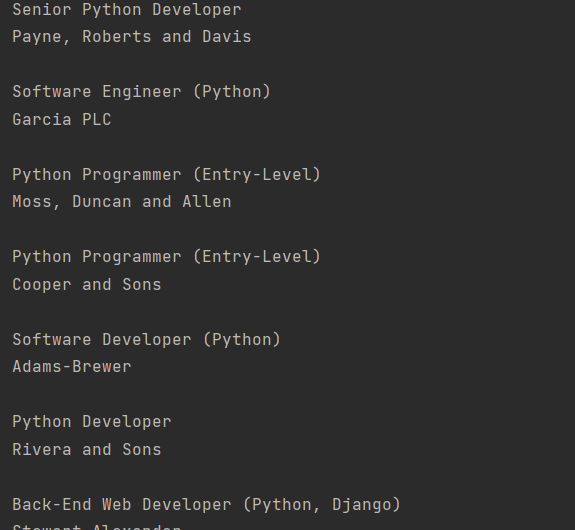
Всё тот же список с Python вакансиями, но теперь ещё и с компаниями. Иногда так даже удобнее.
Мы научились получать текстовое содержимое объектов. Но у каждой карточки есть две кнопки. Попробуем получить их и вывести содержимое. Я поступлю очень лениво и просто из предыдущего примера вернусь к родителю родителя родителя и найду в нём footer карточки, в котором и лежат обе кнопки-ссылки:
|
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») card_parent = parent.parent.parent.parent card_footer = card_parent.find(«footer», class_=«card-footer») card_links = card_footer.find_all(«a») for link in card_links: print(link.text.strip()) print(job_title.text.strip()) print(company_element.text.strip()) print() |
Вот только понимаете, в чём беда, текст ссылки есть, а ссылки – нет. Сомнительная польза.
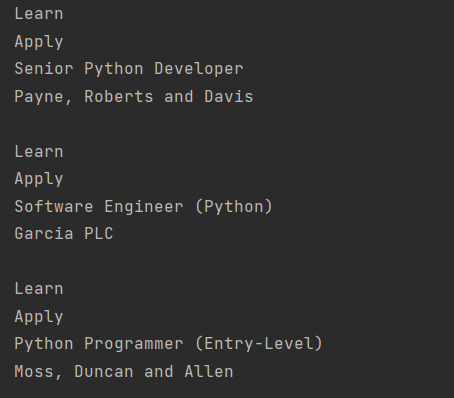
Это связанно с тем, что ссылка href является частью html, это атрибут. И если мы хотим получить текст элемента, то весь html (в т.ч. и атрибуты) будет отброшен. Что мы и увидели. Но извлечь атрибуты из объекта довольно просто. В этом нам помогут квадратные скобки и имя атрибута.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») card_parent = parent.parent.parent.parent card_footer = card_parent.find(«footer», class_=«card-footer») card_links = card_footer.find_all(«a») for link in card_links: link_url = link[«href»] link_text = link.text.strip() print(f«Link for {link_text} is {link_url}») print(job_title.text.strip()) print(company_element.text.strip()) print() |
Результат лучше, чем можно было бы мечтать:
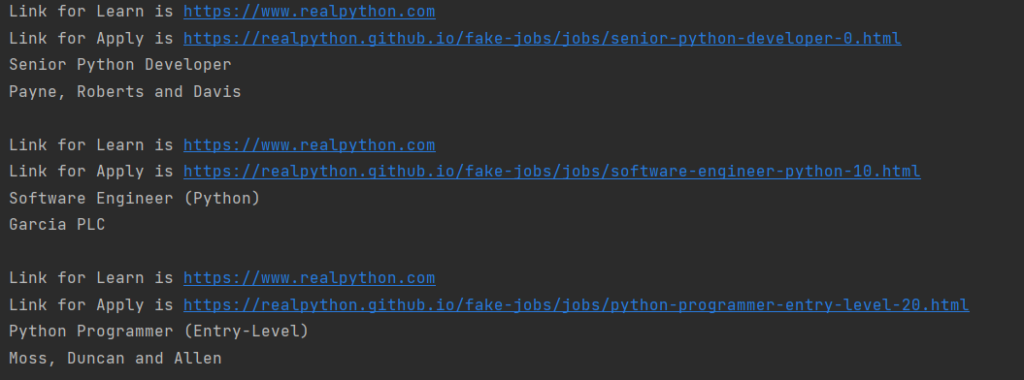
Теперь эти данные готовы для любой обработки, хоть в БД кидай, хоть на сервер пересылай. При этом никто не запрещает вам перейти по новым ссылкам и собрать какие-то данные оттуда. Таким образом можно было бы собрать полные данные о вакансии в одно месте, без необходимости перехода.
На этом пока всё, спасибо за внимание!
Ещё по Python: Графика в Python при помощи модуля Turtle. Часть 1